为 vLLM 推理有效规划 GPU 规模并进行合理配置,首先需要清晰理解大语言模型处理的两个基本阶段——Prefill(预填充)和 Decode(解码),以及这两个阶段对硬件提出的不同需求。
本指南深入剖析了 vLLM 运行时行为的内部机制,阐明了内存需求、量化和张量并行等核心概念,并提供了将 GPU 选型与实际工作负载相匹配的实用策略。通过探究这些因素之间的相互作用,您将能够准确预判性能瓶颈,并在 GPU 基础设施上部署大型语言模型时,做出明智且具有成本效益的决策。
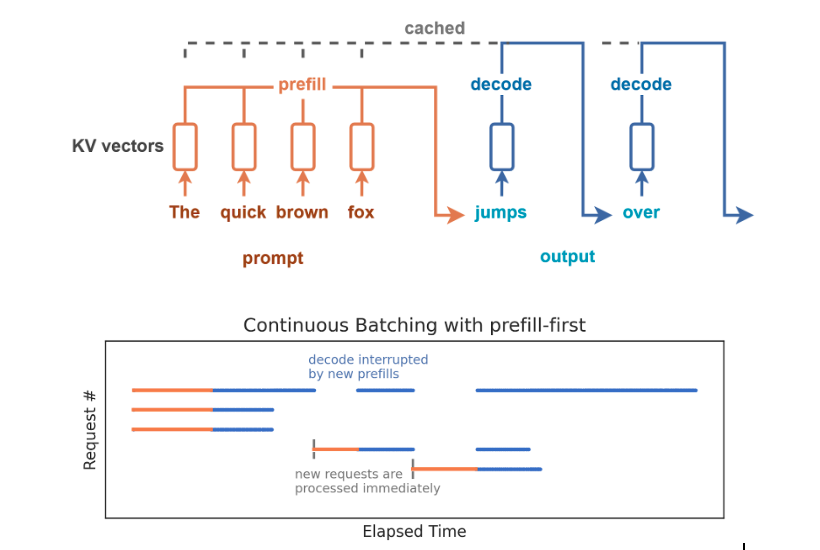
vLLM 运行时行为剖析:预填充阶段 vs 解码阶段
预填充阶段(”读取”阶段)
这是任何请求的第一步。vLLM 接收整个输入提示(用户查询 + 系统提示 + 任何 RAG 上下文),并以高度并行的方式一次性处理所有内容。
- 过程:模型”读取”上下文,并用该上下文的数学表示填充键值(KV)缓存。
- 瓶颈 :由于并行处理数千个令牌,此阶段几乎总是受限于内存带宽。速度上限取决于 GPU 将巨大的权重矩阵从显存移动到计算核心的速度。有关 GPU 性能特性的更多信息,请参阅我们的 GPU 性能优化指南。
- 实际影响:这决定了首 Token 延迟(Time-To-First-Token)。如果要总结一个长达 10 万 Token 的庞大文档,预填充阶段就是让用户在第一个词出现前等待的原因。
解码阶段(”写入”阶段)
预填充完成后,vLLM 进入自回归循环以生成输出。
- 过程:模型生成一个 Token,将其附加到序列中,然后再次运行整个模型以生成下一个 Token。对于单个请求而言,这本质上是串行的。
- 挑战:仅为了计算单个用户的一个 Token 而从显存加载庞大的模型权重是极其低效的;GPU 在移动数据上花费的时间比计算还多。
- 解决方案(连续批处理**)**:为了解决这个问题,像 vLLM 这样的现代引擎不会逐个处理请求。相反,它们使用连续批处理。请求动态地进入和离开批处理批次。vLLM 在同一个 GPU 周期内,将新请求的预填充操作与进行中请求的解码步骤交错进行。
- 瓶颈 :当有效进行批处理时,此阶段变为计算受限(受原始 TFLOPS 限制),因为目标是尽可能多地并行处理 Token 计算,以最大化总体吞吐量。
预填充阶段与解码阶段的对比
- 主要瓶颈:预填充阶段为内存带宽,解码阶段为计算能力。
- 衡量指标 :预填充影响首 Token 延迟 ,解码影响吞吐量。
- 并行性 :预填充阶段针对单个请求具有高并行性;解码阶段对单个请求是顺序的,但通过跨请求的连续批处理实现并行。
将阶段与工作负载及硬件关联
了解哪个阶段在您的工作负载中占主导地位,对于选择合适的硬件至关重要。
| 运行时阶段 | 主要操作 | 主要硬件约束 | 主要用例场景 | | ———————- | —————— | ——————————————————————- | —————————————————————– | | 预填充阶段 | 并行处理长输入。 | 内存带宽 (TB/s)(对快速 TTFT 至关重要) | • RAG• 长文档摘要 • 大规模少样本提示 | | 解码阶段 | 顺序生成输出。 | 计算能力(TFLOPS)(对快速 Token 生成至关重要) | • 交互式聊天与客服 • 实时代码生成 • 多轮智能体工作流 |
运行时的 KV Cache
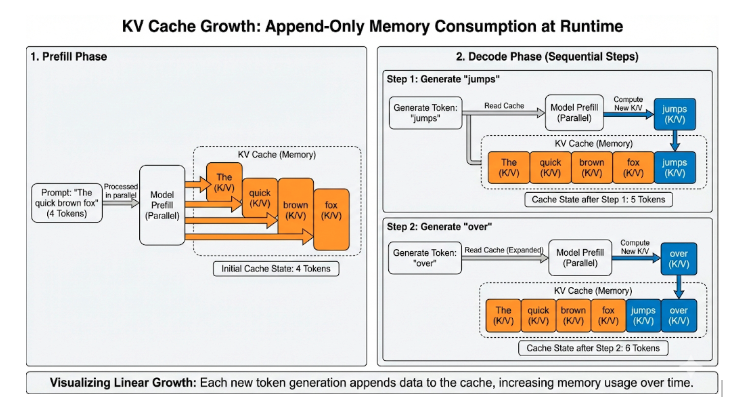
在推理过程中,vLLM 高度依赖 KV Cache,用来避免重复计算已经完成的工作。
工作机制
在 Transformer 中,每个 token 都会在注意力层内被转换为 Key(K) 和 Value(V) 向量。 如果没有缓存机制,模型在生成第 t+1 个 token 时,就必须重新处理整个历史序列(token 0 … t)。
解决方案:KV Cache
KV Cache 的作用正是把这些已经计算过的 K / V 向量保存下来并重复利用。
- Prefill 阶段: vLLM 会一次性为所有输入提示词计算 K / V,并立即写入缓存。
- Decode 阶段:每生成一个新 token,只需从缓存中读取历史 K / V,并仅为这个新 token 计算新的 K / V。
带来的收益
这种机制将注意力计算:
- 从近似二次复杂度(为了写下每一个字,都要把整本书重新读一遍)
- 转变为线性复杂度(只需要写下下一个字)
代价:动态内存增长
性能提升的代价是 显存占用。
每生成一个新 token,KV Cache 中都会追加新的条目。运行时,KV Cache 的使用量会随着以下因素动态增长:
- Prompt 长度与输出长度对话越长,占用的 VRAM 越多。
- 并发请求数(Concurrency每一个活跃请求都需要自己独立的一份 KV Cache。
- 模型规模 模型越深(层数越多)、越宽(注意力头越多),每个 token 所需的缓存就越大。
这正是为什么人们经常说,使用同一个模型的两个工作负载,可能对硬件的需求却天差地别。
例如:一个 70B 模型 本身也许能放进单张 GPU,但如果在长对话中 KV Cache 持续膨胀,服务器仍然可能因为 显存耗尽(OOM)而直接崩溃。
因此,在生产环境中,理解并管理内存 行为是部署 LLM 的核心能力之一 ,这一点在我们卓普云官网博客中的《LLM 微调与部署指南》中也有详细说明。
资源配置基础:模型、精度与硬件如何决定适配性
理解 vLLM 的运行时行为后,下一步是确定模型能否在给定 GPU 上运行,以及它能支持怎样的并发级别或上下文长度。
本节将提供所需的数学公式与决策树,用于计算静态内存需求、估算 KV 缓存增长,并系统性地排查和确定适配问题。
GPU 硬件特性与约束
在计算模型大小之前,首先必须理解我们要把模型放进的”容器”是什么。不同的 GPU 在可行性与性能上都有各自明确的硬性限制。
常见数据中心 GPU 的显存容量
以下是当前主流推理 GPU 的物理显存 上限,也是模型部署时不可突破的硬限制。
vLLM 推理与训练的 GPU 对比:
即使模型本身能够装入显存,GPU 架构差异仍会显著影响 vLLM 的实际性能。需要重点关注以下指标:
模型权重占用(静态显存)
在 vLLM 能够对外提供推理服务之前,模型必须先将全部权重加载进 GPU 显存(VRAM)。
权重大小完全取决于模型的参数数量以及所选择的数值精度。
静态权重计算公式
模型所需的显存容量(GB)可以使用以下公式进行估算:
显存(GB)≈ 参数量(十亿) × 每个参数所占字节数
下表展示了 Llama 3.1 70B(700 亿参数)模型在不同量化精度下的显存占用情况:
精度选择是决定模型是否可部署的最关键因素。
将一个 70B 模型从 FP16 量化为 INT4,可将静态显存占用减少 **75%**,使其从”单节点无法运行”变为”可在单张 A100 上运行”。
因此,在 DigitalOcean GPU 服务器等云环境中,量化是实现高性价比部署的必要手段。
KV Cache 需求(动态显存)
如果说模型权重决定模型是否能够启动,那么 KV Cache 决定模型是否能够扩展。
KV Cache 往往被严重低估,这也是推理负载下最常见的 OOM 原因之一。
要准确评估部署规模,必须根据预期的上下文长度与并发请求数,估算 KV Cache 的显存消耗。
“现场经验法则”(快速估算)
在大多数实际业务场景中,精确公式并不适合即时计算。
因此通常采用”每 token 显存 系数”的方法进行估算,该方式足以支撑初步容量判断。
简化 KV Cache 公式:
KV Cache 总 显存(MB) = Token 总数 × 显存系数
其中:Token 总数 = 上下文长度 × 并发请求数
标准显存系数如下表所示:
示例
我们假设,某用户计划运行:
- 模型:Llama 3 70B
- 上下文长度:32k
- 并发用户数:10
计算 Token 总数: 32,000 × 10 = 320,000 tokens
套用标准系数(0.35): 320,000 × 0.35 MB = 112,000 MB ≈ 112 GB
FP8 选项验证: 若启用 FP8 量化缓存,显存占用将降至一半:约 56 GB
最终配置方案:
- FP16 缓存方案:112 GB KV 缓存 + 140 GB 模型权重 = 总计 252 GB(需 4 块 H100 GPU)
- FP8 缓存方案:56 GB KV 缓存 + 140 GB 模型权重 = 总计 196 GB (可部署于3 块 H100 ;若模型权重同步量化,2 块 H100 亦可勉强容纳)
精确计算工具与公式
针对边界场景或深度验证,请使用专业公式或在线计算器:
- 在线工具:LMCache KV Calculator
- 标准公式:
总KV缓存 (GB) = (2 × 模型层数 × 模型维度 × 序列长度 × 批大小 × 精度字节数) / 1024³
何时需要使用 Tensor Parallelism(张量并行)
Tensor Parallelism(TP)是一种将模型权重矩阵拆分到多张 GPU 上的技术。
它可以让 vLLM 将多张 GPU 视为一张”逻辑大卡”,共享显存资源。
为什么要使用张量并行?张量并行的主要目标是可行性,而非性能优化。
通常在以下场景中启用:
1、模型权重超限:模型体量超过单卡物理承载极限(例如:24GB 显存的 GPU 无法加载 Llama 3 70B 模型)
2、KV 缓存空间耗尽:模型权重虽可加载,但未预留任何 KV 缓存空间,导致无法处理长上下文或高并发请求
虽然张量并行(TP)能极大释放显存,但它也引入了通信开销。在每一层计算完成后,所有 GPU 必须同步它们的部分计算结果。
- 单 GPU 适配情况:如果一个模型能在单张 GPU 上运行,那么使用单 GPU 几乎总是比使用双 GPU 更快,因为它完全避免了通信开销。
- 互联依赖:TP 的性能高度依赖于高速的 GPU 间通信带宽。如果在没有 NVLink 的显卡上使用 TP(例如仅通过标准 PCIe 连接),由于同步延迟,推理速度可能会显著下降。
若需部署多 GPU 环境,可考虑使用 DigitalOcean Kubernetes 来编排 vLLM 服务。
数值实测:资源配置场景分析
在进入高级配置前,让我们将前几节的数学计算应用到实际场景中。这有助于验证我们对”适配性”的理解,并揭示纯计算中常被忽略的实际约束。
隐藏的显存开销
一个常见的错误是计算 ` 权重 + 缓存 = 总显存需求`,并假设可以达到 100% 的利用率。实际情况并非如此。
- CUDA上下文与运行时开销:GPU 驱动、PyTorch 和 vLLM 运行时本身就需要预留内存来初始化(通常为 2-4 GB)。
- 激活缓冲区:前向传播过程中用于存储中间计算结果的临时空间。
- 安全配置原则 :务必预留约 4-5 GB 的显存作为”不可用”的系统开销。如果你的计算结果显示仅剩 0.5 GB 可用,服务器很可能会崩溃。
场景 A:轻松适配(标准聊天)
- 硬件:1x NVIDIA L40S(48 GB 显存)
- 模型:Llama 3 8B(FP16 精度)
- 计算 :
- 权重:80 亿参数 x 2 字节 = 16 GB
- 系统开销:-4 GB
- 可供缓存的剩余显存:48 – 16 – 4 = 28 GB
- 缓存容量估算:28,000 MB / 0.15 MB 每 Token = 约 186,000Token
相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


