编者按: 如果你正在为边缘计算、本地部署或资源受限场景寻找高效的语言模型解决方案,你是否曾困惑:在众多小型语言模型(SLM)中,哪一个才是微调的最佳起点?是否真的存在”小而强”的模型,能在微调后媲美甚至超越规模大数十倍的教师模型?
近期,distil labs 团队进行了一项严谨的基准研究,或许能为你提供数据驱动的答案。他们在 8 类任务(涵盖分类、信息抽取、开卷与闭卷问答)上,对 12 个主流小型模型(包括 Qwen3、Llama、Gemma、Granite、SmolLM 等系列)进行了统一微调与评估,并对比了其与 120B 参数教师模型(GPT-OSS-120B)的性能差异。
作者 | Distil Labs
编译 | 岳扬
01 TL;DR
经过微调的小型语言模型(SLM)可以胜过规模大得多的模型:微调后的 Qwen3-4B 在 8 项基准测试中的 7 项上表现能够超越或战平 GPT-OSS-120B(一个比它模型规模大 30 倍的教师模型),剩下的一项差距也不到 3 个百分点。在 SQuAD 2.0 数据集上,微调后的学生模型甚至比教师模型高出 19 分。这意味着你只需极低的成本,就能在自己的硬件上实现前沿模型级别的准确率。
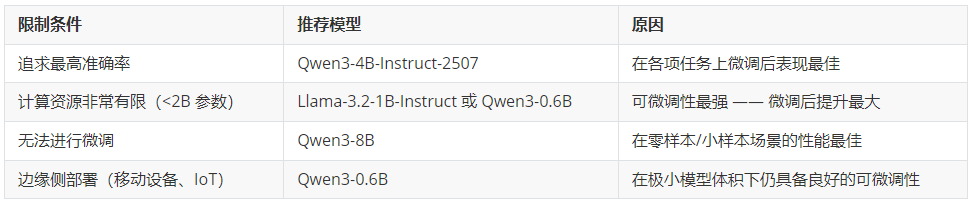
微调后性能最佳的模型:Qwen3 系列模型在微调后始终表现最强,其中 4B 版本整体表现最优。如果你的目标是在特定任务上获得最高准确率,Qwen3-4B 就是你的首选。
最具可微调性(🐟-ble)(微调收益最大):小型模型从微调中获得的提升远超大型模型。 如果你受限于使用非常小的模型(1B–3B),也不必担心 —— 它们能从微调中获益最多,能够大幅缩小与更大模型之间的性能差距。
02 引言
如果你正在构建需要在设备端、本地或边缘侧运行的 AI 应用,你很可能问过自己:我该微调哪个小型语言模型(SLM)?目前 SLM 领域选择众多(Qwen、Llama、Gemma、Granite、SmolLM),每个系列都提供多种模型规模的版本。选错基础模型可能意味着有数周时间在浪费计算资源,或者得到的模型始终无法达到生产质量要求。
我们进行了一项系统的基准测试,用数据来回答这个问题。借助 distil labs 平台,我们在 8 个不同的任务上(分类、信息抽取、开卷问答、闭卷问答)微调了 12 个模型,然后将它们的性能相互比较,并与用于生成合成训练数据的教师大模型进行对比。
本文回答了四个实际问题:
- 哪个模型在微调后效果最好?
- 哪个模型最具可微调性?(即微调后提升最大)
- 哪个模型的基础性能最强?(即未经微调前)
- 我们表现最好的学生模型,真的能媲美教师模型吗?
03 实验方法
我们评估了以下模型:
- Qwen3 系列:Qwen3-8B、Qwen3-4B-Instruct-2507、Qwen3-1.7B、Qwen3-0.6B。注意,我们关闭了该系列的”thinking”功能,以保证实验的公平。
- Llama 系列:Llama-3.1-8B-Instruct、Llama-3.2-3B-Instruct、Llama-3.2-1B-Instruct
- SmolLM2 系列:SmolLM2-1.7B-Instruct、SmolLM2-135M-Instruct
- Gemma 系列:gemma-3-1b-it、gemma-3-270m-it
- Granite:granite-3.3-8b-instruct
针对每个模型,我们测量了:
- Base score:仅使用提示词(prompting)的小样本(few-shot)场景下的性能
- Finetuned score:在由我们的教师模型(GPT-OSS 120B)生成的合成数据上微调后的性能
我们的 8 项基准测试涵盖分类 (TREC、Banking77、Ecommerce、Mental Health)、文档理解 (docs)以及问答任务(HotpotQA、Roman Empire QA、SQuAD 2.0)。
为了实现公平测量,我们分别计算了每个模型在各个基准测试上的排名,然后计算所有任务上的平均排名,并以 95% 置信区间作为误差棒(error bars)绘制在图中。平均排名越低,表示整体性能越好。
04 问题一:哪个模型在微调后效果最好?
冠军:Qwen3-4B-Instruct-2507(平均排名:2.25)
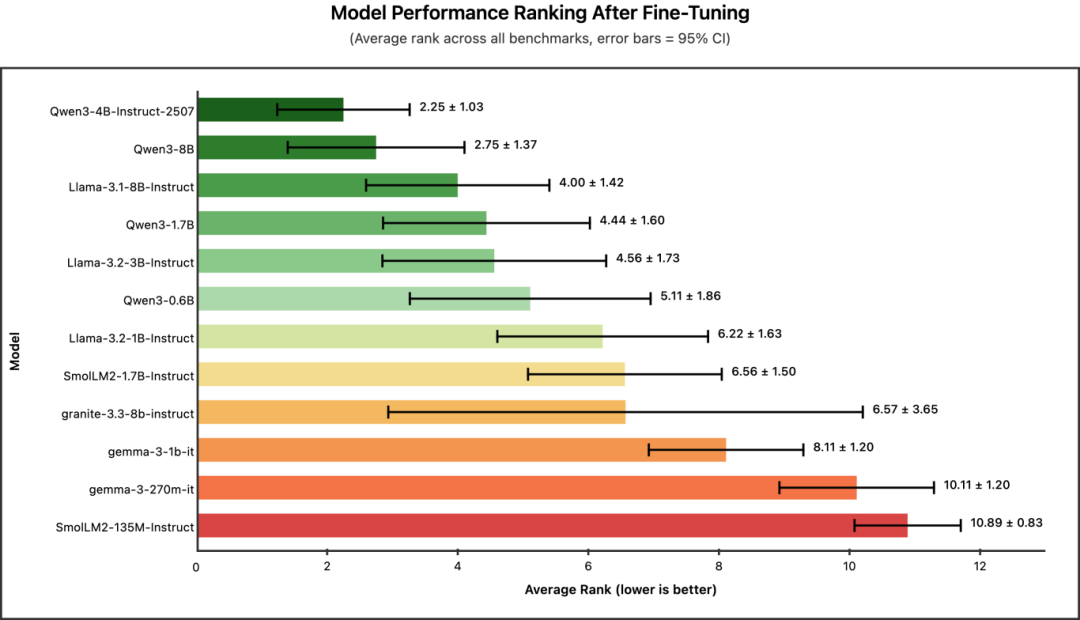
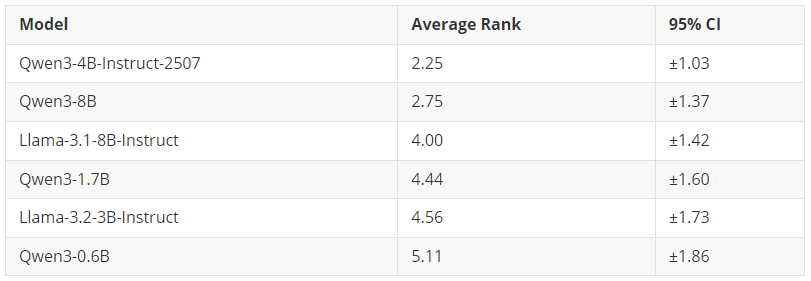
Qwen3 系列占据了排行榜前列,其中 Qwen3-4B-Instruct-2507 摘得桂冠。值得注意的是,这款 4B 模型的表现甚至超过了更大的 Qwen3-8B,这表明在蒸馏任务中,Qwen3 的较新版本(2025 年 7 月 25 日更新的版本)比之前的 8B SLM 效果更好。
核心结论:如果你希望获得效果最好的微调模型,并且拥有支持约 4B 参数规模模型微调的 GPU 显存,那么 Qwen3-4B-Instruct-2507 是你的首选。
05 问题二:哪个模型最具可微调性?(即微调后提升最大)
冠军: Llama-3.2-1B-Instruct(平均排名:3.44)
这里我们测量的是可微调性(tunability) —— 即从基础性能到微调后性能的提升幅度(finetuned_score – base_score)。一个高度可微调的模型初始表现可能较弱,但经过微调后提升显著。
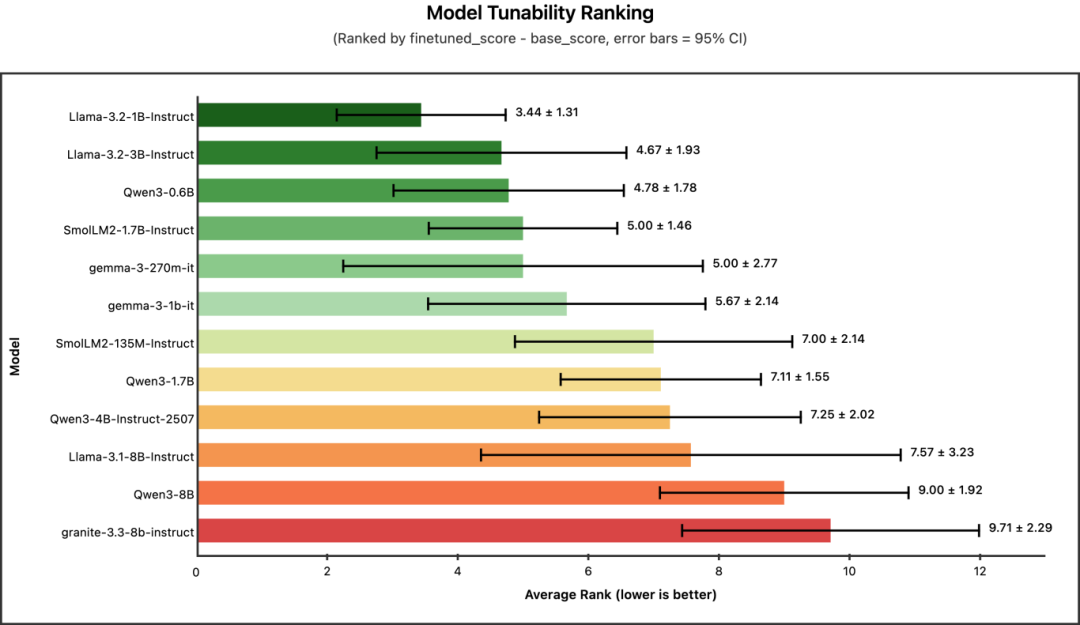
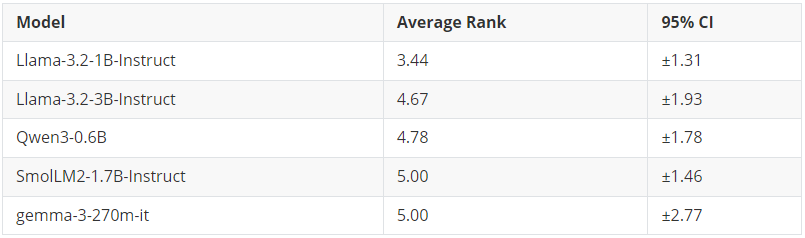
有趣的是,可微调性排名与模型大小的排序正好相反。像 Llama-3.2-1B 和 Qwen3-0.6B 这样的小型模型,从微调中获得的提升最大。而规模最大的模型(如 Qwen3-8B、granite-3.3-8b)在可微调性排名中接近垫底 —— 这并非因为它们表现差,而是因为它们起点相对较高,进步空间相对有限。
核心结论:如果你受限于使用极小的模型(<2B 参数),不必灰心。这些模型从微调中获益最大,并且能够显著缩小与更大模型之间的性能差距。
06 问题三:哪个模型的基础性能最强?(即未经微调前)
冠军: Qwen3-8B (平均排名: 1.75)
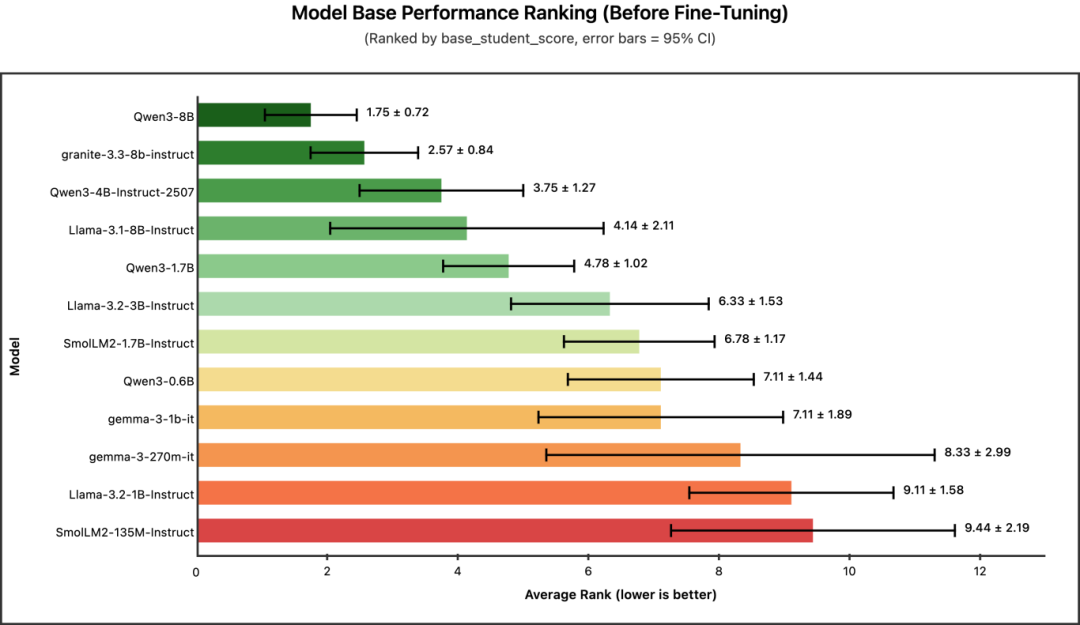
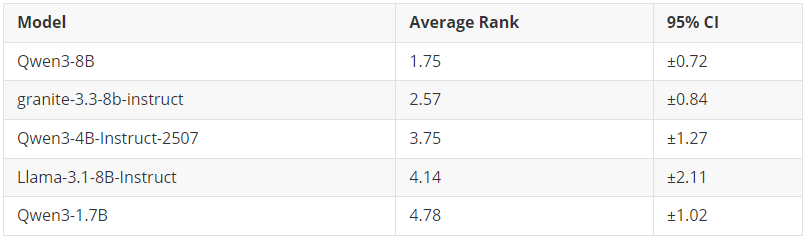
在未经任何微调的情况下,哪个模型开箱即用的表现最好?
正如预期,基础性能与模型大小呈正相关。8B 模型占据了榜首位置,其中 Qwen3-8B 在所有基准测试中都展现出非常稳定的性能(标准差最低)。
核心结论:如果你需要在不进行微调的情况下在零样本/小样本场景下也获得较优的性能,大模型仍是你的最佳选择。但请记住 —— 经过微调后,这种优势会减弱。
07 问题四:我们表现最好的学生模型,真的能媲美教师模型吗?
是的。Qwen3-4B-Instruct-2507 在 8 项基准测试中的 7 项上达到或超越了教师模型。
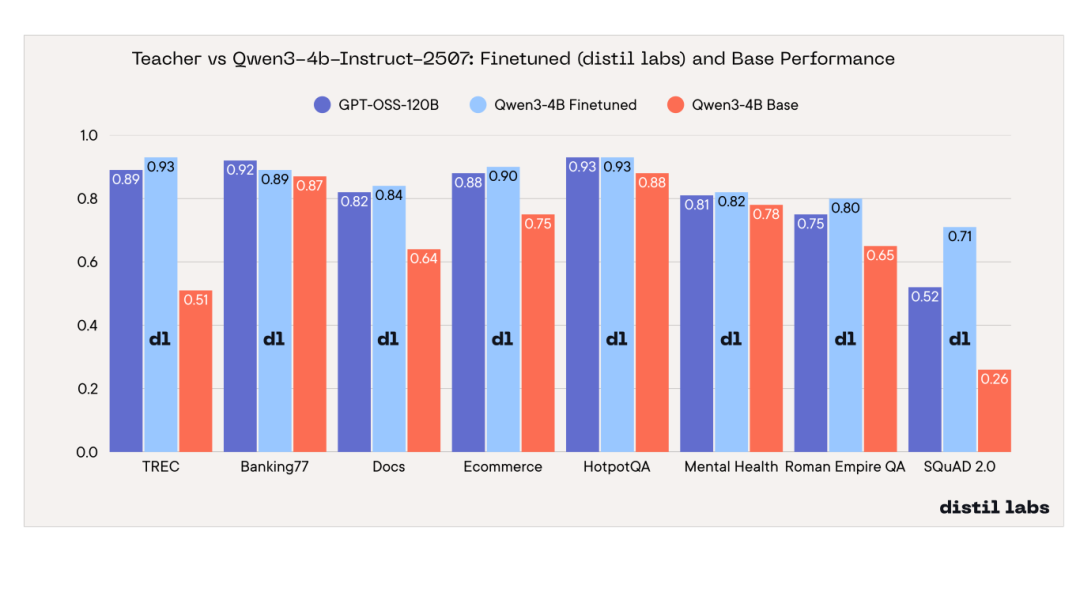
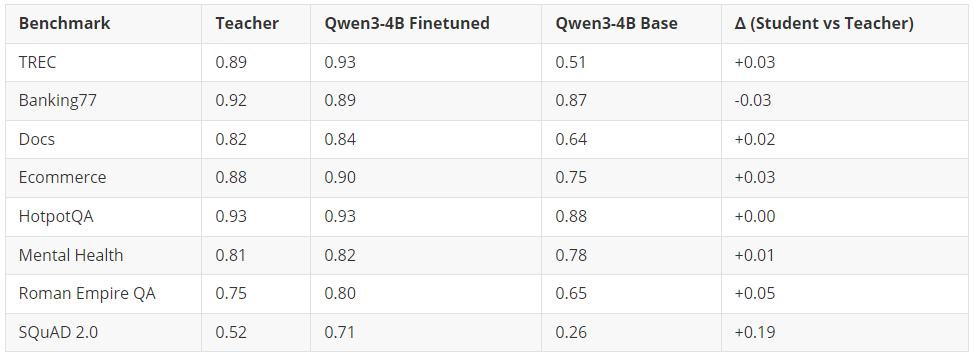
经过微调的 4B 学生模型在 6 项基准测试上超越了 120B+ 参数的教师模型,在 1 项(HotpotQA)上持平,仅在 1 项(Banking77)上略微落后(差距在误差范围内)。提升最显著的是 SQuAD 2.0 闭卷问答任务,学生模型比教师模型高出 19 个百分点 —— 这充分证明,微调比单纯依赖提示词(prompting)能更有效地将领域知识注入模型。
核心结论:一个经过适当微调的 4B 参数模型,可以媲美甚至超越规模达其 30 倍的模型。这意味着推理成本可降低约 30 倍,并且能够完全在本地部署运行。
08 实用建议
基于我们的基准测试结果,以下是选择基础模型的建议:
09 后续我们将进行的工作
本次基准测试只是一个起点,我们正在积极努力让这些结果更加可靠:
- 评估更多模型:SLM 领域发展迅速。我们计划在 Qwen3.5、Phi-4 和 Mistral 系列等新模型版本发布后及时纳入评测。
- 增加运行轮次:目前我们的结果基于有限次数的运行取平均。我们将为每项基准测试增加更多运行轮次,以缩小置信区间,确保排名具有统计可靠性。
- 扩展基准测试覆盖范围:我们希望纳入更多任务类型,如文本摘要、代码生成和多轮对话,从而更全面地反映模型能力。
10 训练细节
每个模型都在使用我们蒸馏流程生成的合成数据进行微调(有关数据合成过程的详细信息,请参见《Small Expert Agents from 10 Examples》[1])。针对每个基准测试,我们使用教师模型(GPTOss-120B)生成了 10,000 条训练样本。
微调采用 distil labs 的默认配置[2]:训练 4 个 epoch,学习率 5e-5,使用线性学习率调度器,以及 rank 为 64 的 LoRA。
所有模型均使用完全相同的超参数进行训练。评估在训练和合成数据生成过程中均未接触过的预留测试集上进行。
11 结论
并非所有小型模型的性能都差不多,但经过微调后,它们之间的差距会大幅缩小。我们的基准测试表明,Qwen3-4B-Instruct-2507 在整体微调性能上表现最佳,不仅能媲美 120B+ 参数的教师模型,还能在单块消费级 GPU 上部署运行。在资源极度受限的环境中,像 Llama-3.2-1B 这样的小模型展现出卓越的可微调性,能够大幅缩小与大模型的性能差距。
核心结论:微调比基础模型的选择更重要。一个经过良好微调的 1B 模型,可以胜过仅靠提示词(prompting)驱动的 8B 模型。
END
本期互动内容 🍻
❓你在微调小型语言模型时,最看重的是”开箱即用的强基础能力”,还是”微调后巨大的提升空间”?为什么?
文中链接
[1]https://www.distillabs.ai/blog/small-expert-agents-from-10-examples
[2]https://docs.distillabs.ai/how-to/input-preparation/config
原文链接:
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


