来源:DeepTech深科技
网上匿名评论或匿名发帖真的是“隐藏”模式吗?现在,AI 能以九成的精确率扒下你的“马甲”。并且,整个过程只需要几分钟,单次成本仅几美元。
来自瑞士苏黎世联邦理工学院、Anthropic 等机构的研究人员在一项研究中得出了惊人结论:他们在 Hacker News、Reddit 等平台开展测试后发现, 大模型通过匿名账号的零散帖子,在特定数据集与实验中能以 90% 的精确率(precision)识别出这些匿名的网络账号对应的真实用户 [1]。
可以将大模型看作一名 AI 侦探。过去,想要获得匿名用户的相关信息,通常需要人工花费数小时去翻阅帖子、搜索线索,再进行对比分析。现在,这个 AI 侦探自己就能完成这项任务,还能一次规模化查多个账户。你只需要向它提供匿名账号的相关发言,它就会在几分钟后告诉你用户大概率是谁。
这个研究就是针对 AI 侦探的性能进行的实验。研究人员开发了四步攻击流程:特征身份提取、语义匹配搜索、推理筛选最优候选结果、置信度评分校准。结果表明,在 90% 精确率条件下召回率(recall,指被正确识别出的目标用户占比)达 68%。与之对比的是,传统方法的召回率接近于 0%。
 图丨相关论文(来源:
arXiv
)
图丨相关论文(来源:
arXiv
)这项研究还警告说, AI 很可能重新识别在网上留下痕迹的用户,这让互联网隐私问题再次成为人们讨论的焦点。
网络匿名,是一种保护参与话题讨论发言者隐私的措施,旨在让他们能够畅所欲言。但现在一切都改变了,所谓的“匿名”发帖模式已被 AI 颠覆,你以为的匿名处处指向“你是谁”。
AI 能以低成本在短时间内,快速找到这些匿名账户背后的真实用户 ,使后者面临隐私、人肉搜索以及广告推销等风险 。这意味着,在论坛上随口吐槽的内容、家乡美食、公司工牌、行文习惯……都可能成为大模型锁定发展者真实身份的关键线索,包括居住地、职业和其他个人信息。
研究人员在论文中提到:“我们的发现对网络隐私意义重大。长期以来,网民一直遵循防御假设,他们认为匿名性足以提供充分的保护,因为传统去匿名化方法需要耗费大量精力,还需要投入高成本。然而,大模型推翻了这一假设。”
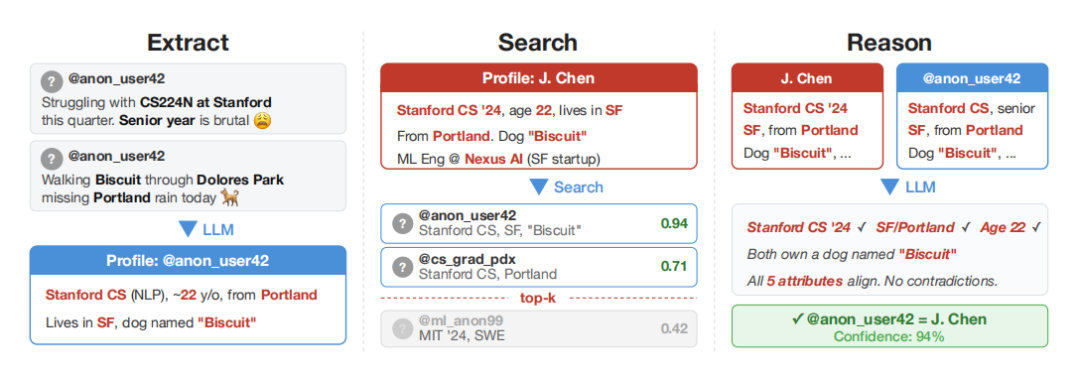 图丨大规模去匿名化框架的总体流程(来源:
arXiv
)
图丨大规模去匿名化框架的总体流程(来源:
arXiv
)为了验证技术的有效性,同时保护发言者的隐私,研究人员从公共社交媒体网站收集了多个数据集。其中,一个数据集收集于 Hacker News 和 LinkedIn 个人资料中的帖子,然后再基于用户资料中出现的跨平台引用将它们关联起来。之后,研究人员从帖子中移除了所有识别信息,并让大模型开始工作。
第二个数据集来自 Netflix 发布的用户身份信息,包括个人偏好、推荐和交易记录等。从历史上的去匿名化先例来看,美国德克萨斯大学奥斯汀分校团队于 2008 年发表的论文中提到 [2],利用 Netflix Prize 技术能够识别匿名用户,并确定他们的政治取向和其他潜在的个人信息。
而第三种数据集的构建方式,则是将单个用户的 Reddit 历史记录做时间拆分处理。
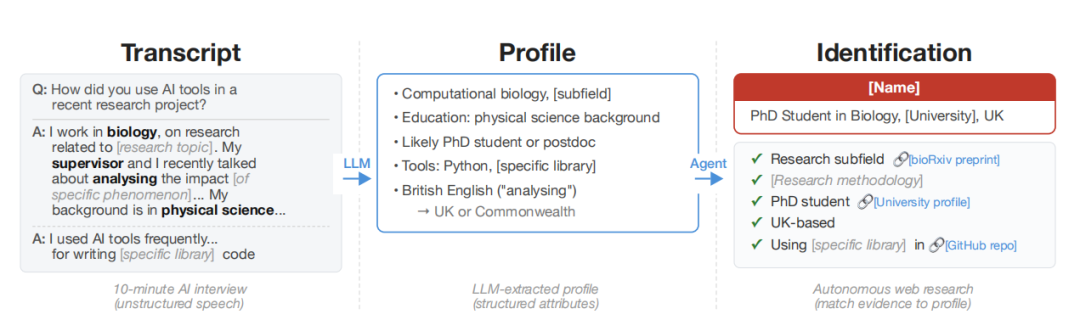
图丨从单次访谈记录进行端到端去匿名化处理(为保护受试者身份信息已对细节进行修改)。AI 智能体从对话中提取结构化身份特征信号,自主检索网络以识别候选个体,并验证该个体是否符合所有提取特征(来源: arXiv )
“我们发现,这些 AI 智能体可以做到以前非常难实现的事情:从自由文本(例如匿名访谈记录)出发,它们可以逐步还原出一个人的完整身份。” 该论文作者之一 Simon Lermen 在接受媒体采访时表示,“这是一项全新的能力,以前的身份重识别方法通常需要结构化数据,以及两个具有相似模式且可以链接在一起的数据集。”
他指出,与传统匿名识别方法最大的不同在于,AI 智能体能够像人类一样浏览网络、与网络内容互动,并通过类人推理逐步缩小候选范围。
为系统验证该能力,研究团队设计了三组实验。在第一项实验中,研究人员分析了 Anthropic 公司关于不同人群在日常生活中如何使用 AI 的问卷调查结果。然后,他们利用这些信息成功识别出 125 名参与者中的约 7%(9 人)。
尽管 7% 的召回率相对较低,但这表明 AI 已实现了能力的跨越:即便信息极其有限且非结构化,大模型也可基于有限信息识别用户身份。研究团队认为,未来随着 AI 技术的进一步发展,有望越来越擅长识别更多身份。
在另一项研究实验中,研究人员收集了 2024 年 Reddit 平台 r/movies 子版块以及 r/horror、r/MovieSuggestions、r/Letterboxd、r/TrueFilm 和 r/MovieDetails 五个社区中至少一个社区的评论。结果表明,用户讨论的电影越多,就越容易识别出他们的真实身份。
从数据的平均值来看,在分享一部电影的用户中,AI 能以 90% 的精确率实现去匿名化 3.1%,能以 99% 的精确率识别其中 1.2% 的用户;当用户分享 5 到 9 部电影时,90% 和 99% 的精确率对应的识别用户分别上升到 8.4% 和 2.5%;而当用户分享超过 10 部电影时,这两个比例进一步提升至 48.1% 和 17%。
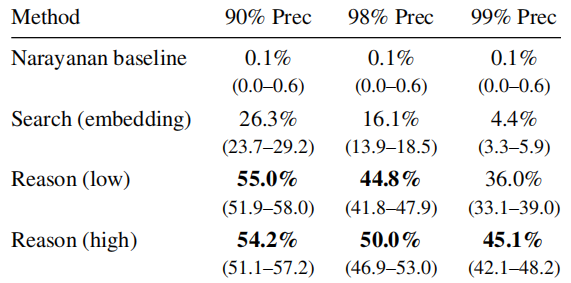 表丨在不同精确率阈值下,HNLinkedIn 跨数据集用户匹配任务的召回率(共 987 条查询)(来源:
arXiv
)
表丨在不同精确率阈值下,HNLinkedIn 跨数据集用户匹配任务的召回率(共 987 条查询)(来源:
arXiv
)在第三项研究实验中,研究人员选取了 5,000 名 Reddit 用户,并对这些用户添加了“干扰”身份。研究人员将新方法与前文提到的 Netflix Prize 攻击技术进行比较。
然后,他们向 10,000 个候选用户列表中添加了 5,000 个查询干扰项,这些干扰项包含仅出现在查询集中的用户,这些用户在候选池中没有真正的匹配项。结果显示,新方法显著优于模仿 Netflix Prize 攻击的经典基线。
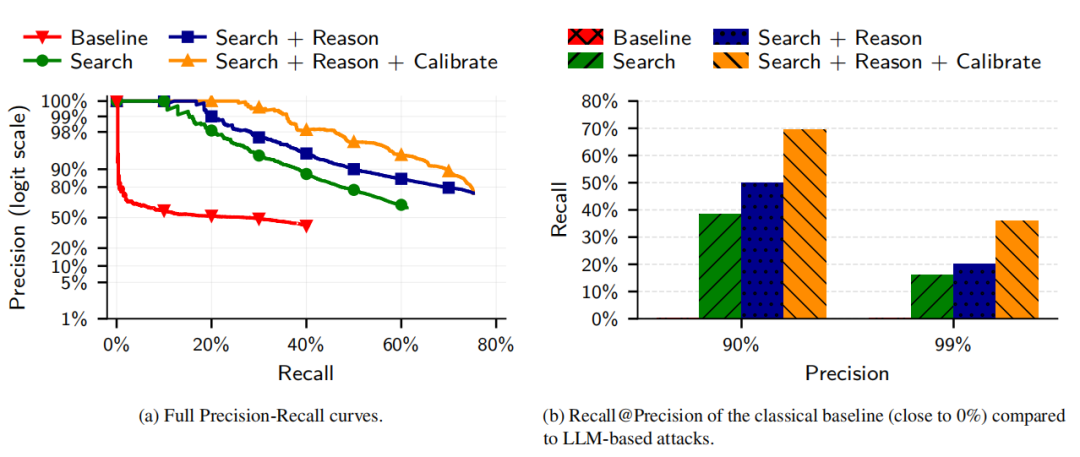
图丨传统攻击方法无法对分割后的 Reddit 个人资料进行去匿名化处理,而基于大模型的攻击方法则具有高度有效性(来源: arXiv )
尽管大模型仍然容易出现误报和其他缺点,但从结果中可以看出,它在识别在线用户方面正迅速超越更传统的、资源密集型方法。随着大模型在去匿名化方面成功率的提高,政府部门可能会用这些技术揭露网络不法分子或诈骗人员的身份,企业则可能会利用这种技术进行个性化广告推荐。
研究人员提出了一系列应对措施,包括平台应限制 API 对用户数据的访问速率、检测自动抓取行为以及限制批量数据导出。大模型提供商还可以监控模型在去匿名化攻击中的滥用情况,并建立防护机制,以让模型可拒绝去匿名化请求。
这项研究指引我们思考一个新的问题: 当你在互联网的每条痕迹都有可能成为 AI“扒”出你真实身份的线索,还会选择继续匿名发帖吗? 当匿名已从默认安全变为不安全,对于用户来说最稳妥的方案是大幅减少使用社交媒体,或者定期删除帖子来防止那些历史痕迹被利用。
参考资料:
1.https://arxiv.org/pdf/2602.16800
2.https://arxiv.org/pdf/cs/0610105
3.https://arstechnica.com/security/2026/03/llms-can-unmask-pseudonymous-users-at-scale-with-surprising-accuracy/
运营/排版:何晨龙
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

