编辑|张倩
导读:黄仁勋刚在 GTC 上放话:Token 就是 AI 时代的新货币,谁能把每瓦特电力榨出更多高价值的 Token,谁就能称王。几乎同时,奖金池高达 600 万元的腾讯广告算法大赛开启报名,为全球算法人才搭建了一座验证这套规则的实战沙盘。

「Token」「推理成本」「智能体」「工作流程自动化」…… 这些原本只在技术圈里流转的词,最近因为一场「龙虾热」开始频繁出现在公众视野中。
与此同时,很多人也从另一个侧面感受到变化:手机、电脑陆续宣布涨价,而厂商给出的理由几乎一致 —— 存储芯片价格正在明显上涨。
其实,这两件事指向同一个背景:应用层面的 AI 需求正在迅速爆发,而在基础设施层面,整个行业还没有完全准备好。算力、芯片、系统效率,这些原本隐藏在幕后的问题,正在被突然放大的 AI 需求推到台前。一个比较明显的表现是,算力租赁行业已经出现涨价潮,而且可能持续一段时间。对于想要搭上「龙虾」快车的企业来说,这无疑是一个切身相关的变化。

但对想在 AI 领域有所作为的人来说,这里面蕴含着机会。当越来越多的公司开始意识到一件事:在算力供应短期内持续紧缺的情况下,真正限制 AI 普及的,可能并不是模型不够强,而是算力用得还不够高效。如何用更少的计算资源,跑出同样甚至更强的智能,会成为接下来一段时间的重点。
一旦问题变成这样,需求也会随之变化。 能够同 时理解算法 、系统和算力效率的人才,自然会变得越来越抢手。
这种对「高效能人才」的渴求,也催生了一个有趣的现象:科技公司开始尝试把这一方向真实的工程问题拿出来做成公开竞赛,让外部的人一起参与解题 —— 这不仅是招募人才的方式,也是在测试自己的命题有没有解法。 2026 年腾讯广告算法大赛 就是这样一场活动。

和往年一样,今年的比赛依然围绕真实业务场景展开,(脱敏)数据来自每天服务数十亿用户的广告系统。换句话说,这不是一道纸面上的算法题,而是一次接触真实 AI 基础设施问题的机会,它代表了每家大厂都面临、但还没有人真正系统性解决的工程难题。
和往年相比,今年这届比赛还有两个明显的变化:
一个是,它时隔多年再次与 KDD 国际顶级学术会议官方联动,回到了更大的国际舞台上。
另一个变化是赛道的打开。过去这类比赛大多面向在校学生,今年则首次单独设立工业赛道,在职算法工程师、技术团队也可以参与进来。
比赛的奖金池以及其他收益自然也是非常可观, 学术赛道冠军可拿到 30 万美元(约合 200 万元)奖金 ,这在国内几乎是天花板级别的存在。
这个级别的比赛,对应的自然是足够前沿、足够复杂的问题,连出题人都在等着看答案。如果找到了足够优秀的解法,它可能直接改写国内大厂技术基础设施的底层逻辑。
全新挑战:探索推荐系统的 Scaling Law
今年的赛题为什么重要?因为这道赛题,本质上是在问一个颠覆性的问题:推荐系统,能不能像被 AI 大模型影响的其他领域一样,被「重做一遍」?
过去十几年,推荐系统一直是科技公司最重要的基础设施之一。它从海量信息中,筛选出最契合用户需求的信息,并屏蔽信息爆炸带来的噪音。
但随着 AI 领域进入大模型时代,甚至是 Agent 时代,推荐系统的演进也来到了一个新的拐点:一边是像大模型那样的「统一架构 + GPU 高效计算」已经被证明可以吃掉一切;另一边却是 推荐系统还停留在「拼装式工程」,结构割裂、 算力利用效率还有大量提升空间 。
为什么这么说呢?一般来说,在广告推荐系统里,模型通常要解决两件完全不同的事情。
第一件是理解用户的行为序列。比如一个人最近看了什么视频、点了哪些商品、搜索过什么。这些行为是按时间排列的,所以模型要理解「顺序」。这一类问题一般叫序列建模。
第二件是理解各种特征之间的组合关系。比如「女性 + 买过婴儿推车」,这些特征组合起来,可能更应该推荐「安全座椅」。这类问题叫特征 交互 。
问题在于,在工业界,现在这两件事是分开做的 —— 一部分网络专门处理行为序列,另一部分网络专门做特征 交互 ,最后把结果合并。
这在早期 CPU 时代问题不大,但到了 GPU 时代,这种拼接式架构带来了很多问题。首先,信息在中间是断开的,很多复杂关系捕捉不到。其次,整个系统结构复杂,很多小模块,GPU 算不满。而且 CPU/GPU 要来回搬数据,效率很低。
主办方希望参赛者尝试做一件事: 把两套东西,彻底合成一个模型 。所以赛题被命名为「大规模推荐系统中序列建模与特征 交互 的统一」。
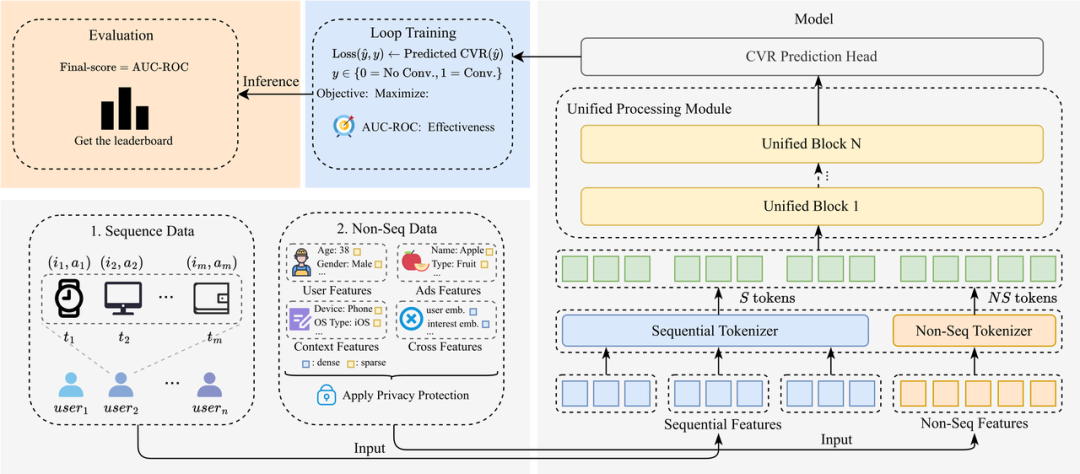 本次竞赛的核心任务架构。
本次竞赛的核心任务架构。这并不是拍脑袋想出来的赛题,而是顺着大模型已经验证过的那条路在走。像 Transformer 这种统一架构已经证明了一件事:只要把各种数据用同一种方式表示、交给同一套模型处理,就能更高效地利用算力,而且规模越大效果越好,也就是所谓的 Scaling Law。但推荐系统还停留在东拼西凑的老结构里,很难享受到这种提升。这道题,其实就是在试一件事:推荐系统能不能也换成这一套,更简单、更统一,而且越做越强。
当然,这件事做起来没有那么容易。核心难点在于,广告推荐场景的数据极其复杂 —— 既有用户当下的静态信息,也有带时间戳的行为流水,你需要在一个统一架构里把这两种完全不同的数据「翻译」成模型能懂的语言并深度融合。同时,工业级数据规模海量且极度稀疏,模型必须足够鲁棒。更苛刻的是,你既要预测准,又要跑得快,得在高端 GPU 上支持大批量高效训练和推理。需要注意的是,比赛严禁用「model ensemble」这种刷榜技巧,只能凭真本事靠单一模型硬碰硬。
不过,从主办方给到的支持来看,这次比赛并不是「丢一道题就让选手自己摸索」。为了降低门槛,他们提供了一套可复现、起点很高的 Baseline—— 不只是简单示例,而是基于 Transformer 的完整统一架构,连 Token 化思路和核心网络都搭好了,还会提供免费算力支持。
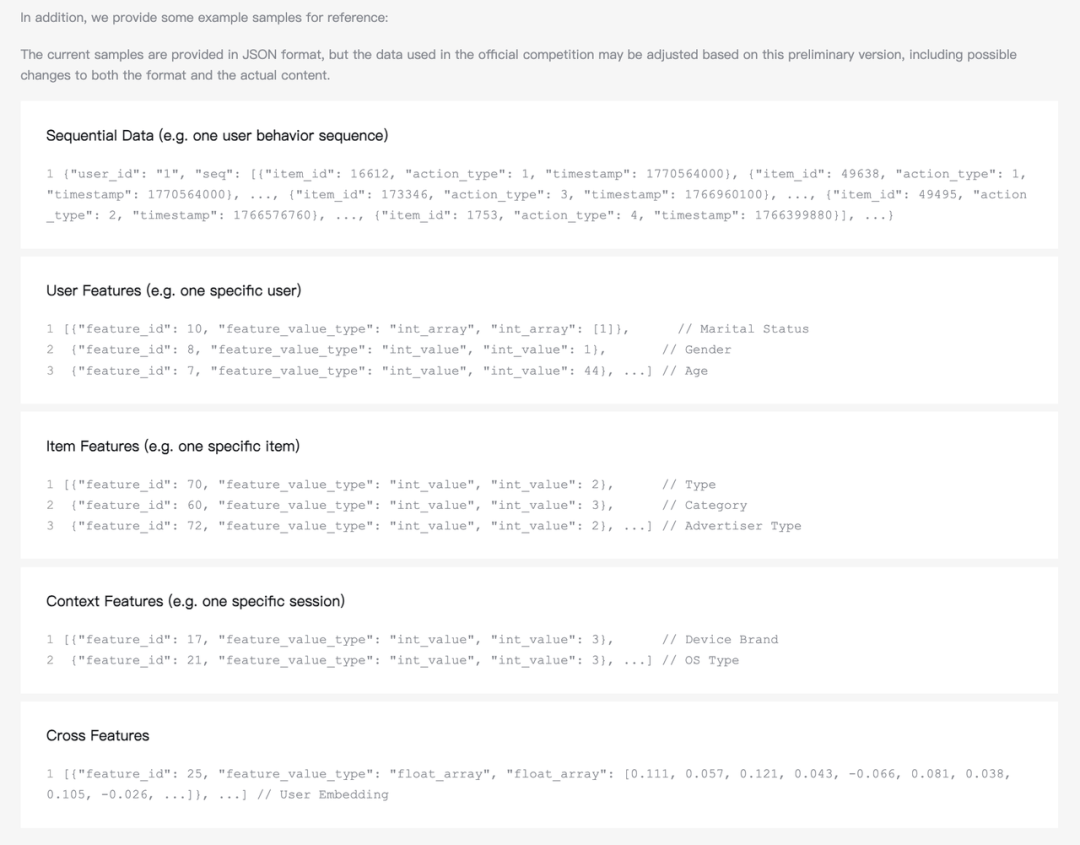
数据方面也不用担心,他们提供的数据直接来自腾讯广告的真实工业日志,规模和复杂度都接近真实生产环境,同时又做了严格的不可逆的匿名化处理。
客观来讲,题确实难,但也足够真实、足够前沿。如果能花 1-2 个月时间挑战一下,相信无论接下来是打算在工业界做推荐系统,还是继续深挖大模型与系统架构,这段经历都会成为少有的「触碰过真实一线问题」的证明。
为什么值得参加?
前面提到,这次比赛有两个值得关注的变化,一是与 KDD 联动,二是在职人士也能参加。
众所周知,KDD 在顶会圈的地位和 ICML、NeurIPS 齐平。这次大赛能和 KDD 联动,本质上也是因为 赛 题本身已经具备了顶会级别的学术价值 。所以,如果能在大赛中脱颖而出,你简历上就多了一个全球认可的加分项。而且,你的成果会被大会的 Workshop Proceedings 收录,颁奖典礼也将在今年 8 月份的 KDD 会议现场举行。
「学术 + 工业」双赛道的并轨则是出于两方面考虑。一是赛题本身不是一个 toy problem,而是每家大厂都面临的工程难题,必须有真实系统落地经验的工程师带入更接地气的工业约束和实现视角。二是在这个技术日新月异的时代,高校学术派和行业实战派需要一个直接对话的契机,从而加速前沿算法从论文到生产系统的转化。
这项比赛从 3 月 19 日开启报名。总奖金池高达 88.5 万美元(约合 610 万元)。其中学术赛道冠军奖金为 30 万美元(约合 200 万元),工业赛道冠军奖金为 15 万美元(约合 100 万元)。
值得一提的是,为了奖励选手在 Scaling Law 与统一架构方面的原创突破,大会还设置了两项 技术创新奖 ,即便排名不在前列也有机会获奖,每项奖金为 4.5 万美元(约合 31 万元)。

比赛结束之后,Top 队伍选手将有机会加入腾讯,亲手把方案落地广告系统验证实际效果。
看到这里,相信很多同学已经跃跃欲试了,但也会有人担心:自己从来没碰过推荐系统,现在上车来得及吗?
其实完全不用慌。翻翻腾讯广告算法大赛历年的获奖名单,你会发现不少选手都是报名之后才从零开始啃,边赛边学。最后不仅拿了奖,还顺便摸清了自己的职业方向。比赛本身就是一个寻找赛题答案和人生答案的过程:既能验证自己是不是吃这碗饭的,也能在高压下快速摸清这个领域的真实样貌。
随着 Token 逐渐成为 AI 时代的基础货币单位,一个全新的价值交换体系正在我们面前展开。对每一个个体而言,这或许正是那个稍纵即逝的窗口期。当新秩序初具雏形,率先参与其中的人,往往能拥抱最大的红利。如果能抓住机会参与其中,未来的你可能会感谢今天的这个选择。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

