
强化学习的下一站:从监督到无监督
强化学习正在重塑大模型能力边界。OpenAI o3、DeepSeek-R1、Gemini 3 等顶尖模型都在用大规模 RLVR(可验证奖励强化学习)刷新推理任务的天花板。但所有人都知道, 纯监督式训练不可持续 。人工标注成本指数级增长,在专业领域获取可靠标注越来越难。当模型能力逼近甚至超越人类专家时,谁来给它打分?
从 TTRL 开始,无监督 RLVR(Unsupervised RLVR)应运而生, 让模型在没有人工标注的情况下持续进化 。这不仅是降本增效的需求,更是通往超级智能的必经之路。就像预训练用无标注数据 training 出了 GPT,无监督 RLVR 能否延续这一奇迹?

论文链接: https://arxiv.org/abs/2603.08660
GitHub: https://github.com/PRIME-RL/TTRL/tree/urlvr-dev
X Thread: https://x.com/HBX_hbx/status/2031406636930338828
清华团队一项最新研究,给这个看似美好的图景画出了第一条边界。研究者系统解剖了无监督 RLVR 的内在机制,发现所有基于模型自身信号的内在奖励方法,无论多数投票、熵奖励还是其他变体,都遵循着一条相似的轨迹:训练初期性能快速攀升,但到达某个临界点后,开始不可逆地滑落。 这不是某个方法的缺陷,而是机制的宿命:它们本质上都在锐化模型已有的偏好,像一个回声室,让模型不断重复自己最初相信的东西。如果初始自信恰好正确,效果惊人;如果错配,坍塌只是时间问题。
但这不意味着内在奖励没有价值。在小规模测试时训练中,它依然能稳定提升性能,即使模型一开始全是错的,也能在自我纠偏中进化。更重要的是,研究者找到了一个 “预言指标”,可以在大规模训练前预判模型的可训练性,无需跑完整条曲线。
当内在奖励受限于模型自身的回声时,外部奖励方法开始展现不同图景,比如让模型利用生成与验证的不对称性来锚定奖励。这类方法正在突破内在奖励的天花板,让无监督强化学习真正走向可扩展。
通往超级智能的路上,我们需要的不是盲目相信模型可以自我进化,而是知道什么时候该让它倾听自己的回声,什么时候该把它推向真实世界的验证。
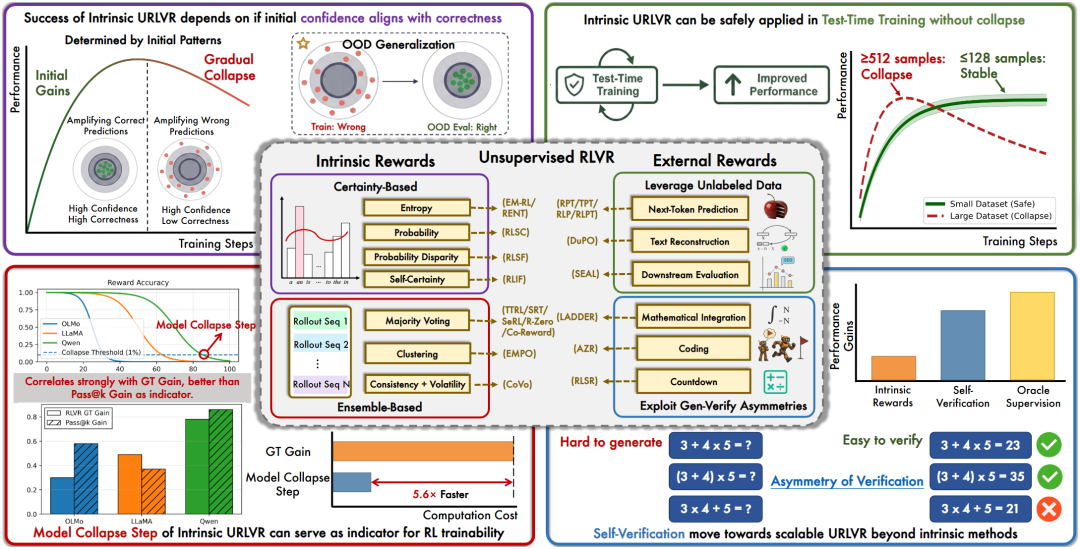
内在奖励方法:繁荣表象下的深层问题
过去一年,各种 “内在奖励” 方法密集涌现。从多数投票到基于模型自信度 / 熵的变体,它们利用模型内在信号来构造 proxy reward, 训练前期性能飙升,甚至一度超过有监督方法 。
研究者将这些方法根据奖励的来源归纳为两类:一类基于 certainty,直接取模型在推理轨迹上的置信度指标作为奖励;另一类基于 ensemble,用多次 rollout 后的集成结果(如多数投票)来锚定正确。

虽然奖励的来源是免费的,但是代价却是昂贵的。在早期训练性能飙升之后,继续训练会触发典型的 reward hacking:
proxy reward 还在持续上涨,真实 performance 却在崩溃
模型越来越自信,但答案却越来越离谱
不同内在奖励方法在不同模型上表现天差地别
更关键的是, 没人说得清为什么 work,又为什么 fail 。
我们做了什么:拆开黑箱,划清边界
我们不想只是 “提出新方法刷个点”,我们想回答那个没人说清的问题:
无监督 RLVR 的 scaling 上限在哪里?如果有上限,边界在哪里?
为此,我们做了五件事:
统一理论框架 :把看似五花八门的内在奖励方法归到同一个机制下,揭示它们殊途同归的本质 —— 锐化模型初始分布,并给出理论收敛边界。
大规模实证 :11 个模型 × 5 种内在奖励方法 × 超参数扫描,用数据说话,验证了 “先升后降” 不是偶然,而是普适规律。
画出安全区 :不是所有场景都会崩溃。我们发现,在小规模 test-time training 中,内在奖励可以安全使用,即使初始全错也能稳定进化。
化陷阱为路标 :rise and fall 不只是风险,它本身就是信息。我们用它提炼出模型先验指示器,无需跑完整条 RL 曲线,就能预判一个基模是否适合强化学习。
探路替代方案 :既然内在奖励有天花板,我们就看向外部。初步探索基于生成 – 验证不对称的外部奖励方法,看它能否真正突破内在奖励的 scaling 极限。
四个关键发现
🔍 发现一:成败取决于 “confidence-correctness” 对齐程度
我们建立了内在奖励方法的统一理论,揭示所有内在奖励方法的本质: 锐化分布,即放大模型已有偏好,而非创造新知识 。这个机制有个特性:
如果模型初始倾向正确 → 锐化有效,性能提升
如果模型初始倾向错误 → 锐化有害,加速崩溃
我们定义模型初始倾向(或者称为 模型先验 )为 confidence-correctness 对齐程度 ,即当我们仅提升模型的自一致性时,有多大可能就能直接做对更多的题目。换句话说,一个先验比较强的模型,本身已经掌握了解决问题的大部分知识,只是不够自信以至于说不出正确的答案。
我们测试了 11 个模型、5 种方法、4 个常用的超参数,结论似乎是残酷的: 崩溃不可避免,只是时间问题 。即使最稳定的配置也撑不过几个 epoch。这说明可能不是工程问题,是数学必然。
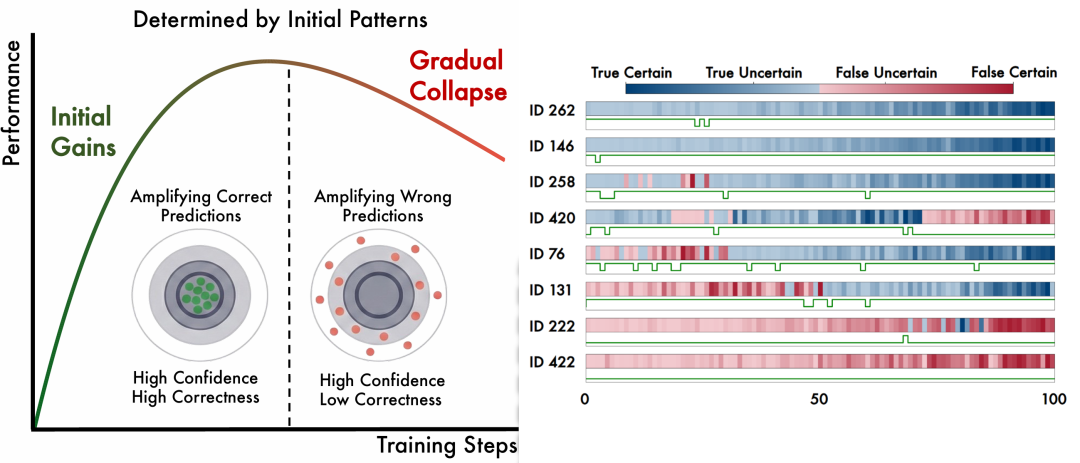 左:成败取决于置信度 – 正确性对齐程度;右:单条数据上置信度与正确性随训练的演化
左:成败取决于置信度 – 正确性对齐程度;右:单条数据上置信度与正确性随训练的演化✅ 发现二:小场景里反而安全
Rise and fall 是宿命,但宿命有它的适用范围。
当训练数据足够少,比如 Test-Time Training 这种特定领域场景,内在奖励方法反而展现出难得的稳定。原因很朴素:只在少量样本上优化自信度,模型跑不了多远就到头了。即便它在这些样本上变得 “超级自信”,也难以引发全局的策略偏移,OOD 任务上的准确率依然稳稳守住。
更有意思的是一个极端实验:研究者刻意选了 32 条模型全错的样本作为训练集。也就是说,内在奖励给出的 proxy reward 从一开始就是错的。结果呢?OOD 测试集上的性能依然在稳定提升。
这说明,内在奖励不是在教模型 “什么是对的”,而是在教它 “更相信自己”。即使信错了,这种自我强化也被牢牢锁在局部,翻不起大浪。
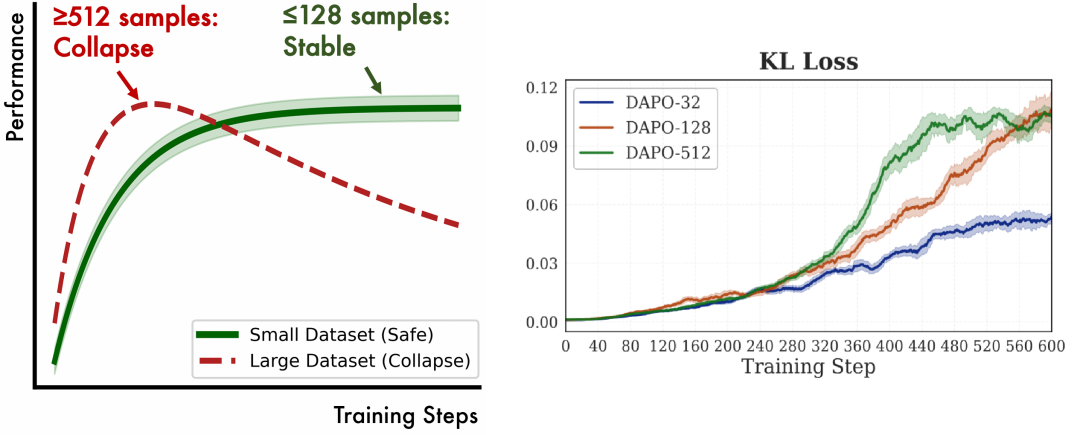 左:小规模 TTT 稳定提升,不崩溃;右:不同训练集规模下策略的 KL 偏移
左:小规模 TTT 稳定提升,不崩溃;右:不同训练集规模下策略的 KL 偏移🎯 发现三:判断模型适不适合做 RL
Rise and fall 不只是风险,它本身就是信息。
既然内在奖励的成败取决于模型初始的 “置信度 – 正确性” 对齐程度,那能不能用这个对齐度,提前判断一个基模是否适合做 RL?毕竟,跑一次大规模 RL 的成本太高了,而学界一直缺一个轻量级的预判指标。
研究者找到了一把尺子: 模型坍塌步数(Model Collapse Step),去测量一个模型在内在奖励训练下,能撑多少步才完全崩溃 。逻辑很简单,如果崩溃越晚,说明模型的初始先验越好,它本身就掌握更多正确知识,只是不够自信;而这种先验,恰恰是标准有监督 RL 能够放大的东西。换句话说,内在奖励的崩溃点,就是模型 “RL 可训练性” 的天然指示器。
结果也印证了这一点。Qwen 这种公认 “适合 RL” 的模型系列,在内在奖励下撑得更久。更有意思的是,这个指标无需任何 ground truth 标注,预测准确率超过传统的 pass@k。
把失败变成路标,把昂贵的试错变成轻量级的预判。
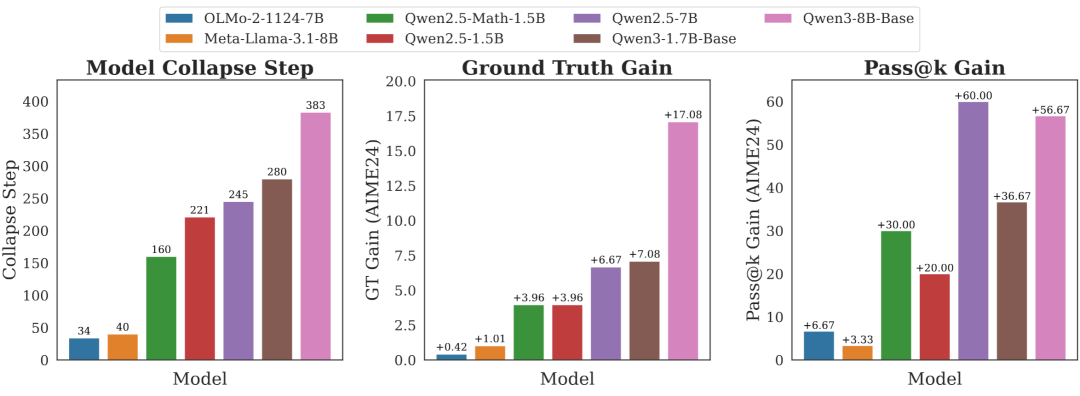
左:不同基模在无监督内在奖励训练下的模型坍塌步数;中:对应基模有监督 RLVR 的性能提升。无监督内在奖励下崩溃越晚,有监督 RLVR 之后效果越好,预测准确率超过传统的 pass@k。
🚀 发现四:外部奖励才是 scalable 的方向
如果内在奖励注定有天花板,那路在何方?
问题的根源在于奖励的来源。内在奖励方法用模型自己的置信度来训练模型自己,这就像一个闭环回声室,奖励信号永远受限于模型已知的东西。你无法用它教会模型真正不知道的知识。
但无监督 RLVR 不止于此。我们把外部奖励方法归纳为两类:
利用无标注数据:从海量语料中挖掘奖励信号。数据越多,奖励信号越丰富,不会因为模型变强而枯竭。
利用生成 – 验证不对称性:让模型自己生成答案,再用外部工具(编译器、证明助手、模拟器)验证并提供环境反馈。这些验证器不会因为模型变强而失效,它们的判断永远客观。
我们初步测试了自验证方法,结果展现出一条截然不同的曲线:持续改进,没有崩溃。原因很朴素,奖励不来自 “模型有多自信”,而来自 “答案能否通过客观验证”。想出解法可能很难,但检查对错往往简单;这种不对称性,把模型的进化锚定在真实世界的铁律上,而不是自己的回声里。
内在奖励追问 “你相信自己吗”,外部奖励追问 “这是真的吗”。通往 scalable 的无监督强化学习,答案或许就在后者。

写在最后:边界之外
我们花了许多篇幅去描绘无监督强化学习的边界。但这张地图的价值,从来不在于告诉你 “此路不通”,而在于回答: 在什么条件下,哪条路通 。
一个系统能否通过审视自己而变得更好,取决于它最初的判断有多准确。 内在奖励方法失败的原因,恰恰是它们成功的原因,都是同一个机制:自我强化。区别只在于,被强化的是真理还是偏见。
当我们认清内在奖励的宿命,才真正看清外部奖励的星辰大海。通往 scalable 的无监督强化学习,需要的不是盲目相信模型可以自我进化,而是知道什么时候该让它倾听自己的回声,什么时候该把它推向真实世界的验证。
内在与外部不是对立,而是工具箱里的不同工具。认清边界,不是为了止步,而是为了 在边界内自由创造,在边界外寻找新的可能 。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

