
西南财经大学在读硕士、上智院实习生胡澳,是本文第一作者,其主要研究方向为多变量长时序预测; 西南财经大学教授、成都恒图科技创始人段江 ,为共同第一作者。西南财经大学副教授温良剑,上智院 AI 科学家、复旦大学教授徐增林,为本文通讯作者。
长期时间序列预测(Long-term Time Series Forecasting, LTSF)是能源管理、金融市场和交通预测等领域的核心任务。现有基于 Patch 的 Transformer 模型面临一个根本性挑战: 非平稳时序数据中,Patch 之间的尺度差异会严重干扰注意力机制对形状相似性的捕捉,导致模型学习到错误的相关关系,预测精度受限。
为此, 西南财经大学、上海科学智能研究院(下称上智院)、复旦大学、成都恒图科技等机构最新联合提出 PMDformer —— 一种基于 Patch 均值解耦(PMD)的创新时序预测框架。 通过三大核心模块的协同设计,它在多项权威基准上全面超越现有最优方法。

论文地址:https://openreview.net/forum?id=rfJ41gK9Ct
代码地址:https://github.com/aohu1105/PMDformer
目前,该成果已被 ICLR 2026 接收。
现有方法的痛点:尺度差异如何「扭曲」形状建模?
长期时序预测中,研究者常用 Patch 分割策略来捕捉长序列中的局部语义,但时序数据的非平稳性带来显著挑战 —— 同一序列在不同时段的数值尺度差异悬殊。这一特性带来了两个关键问题:
尺度偏差遮蔽形状相似性: 注意力权重受 Patch 均值影响,导致形状相似但尺度不同的 Patch 被错误地判为不相关,而形状迥异的 Patch 反而获得高注意力权重。模型捕捉到的并非真正的模式,而是由尺度「幻觉」造成的误导。如论文图 1 所示,P1 与 P2 形状高度相似,但在解耦前,P1 与 P3 的注意力权重反而更高。
跨变量依赖建模失准: 变量间的相关性随时间演变,历史早期的相关关系对预测近期走势的参考价值有限,但现有模型通常在全局历史窗口上计算变量交互,引入大量噪声,容易过拟合。
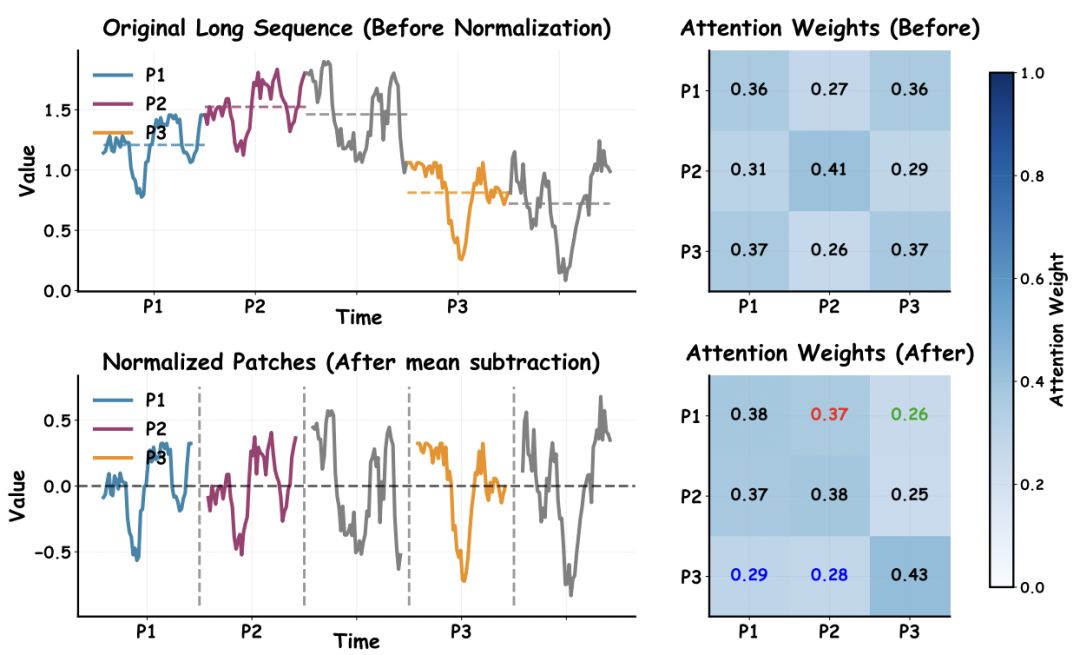
图 1:PMD 解耦前后的注意力权重对比。上:原始序列中,尺度差异导致注意力偏向 P3;下:均值解耦后,注意力正确反映形状相似性
PMDformer:三位一体的解决方案
PMDformer 由三个协同工作的核心模块组成,分别解决上述不同层面的问题,形成完整的技术闭环。
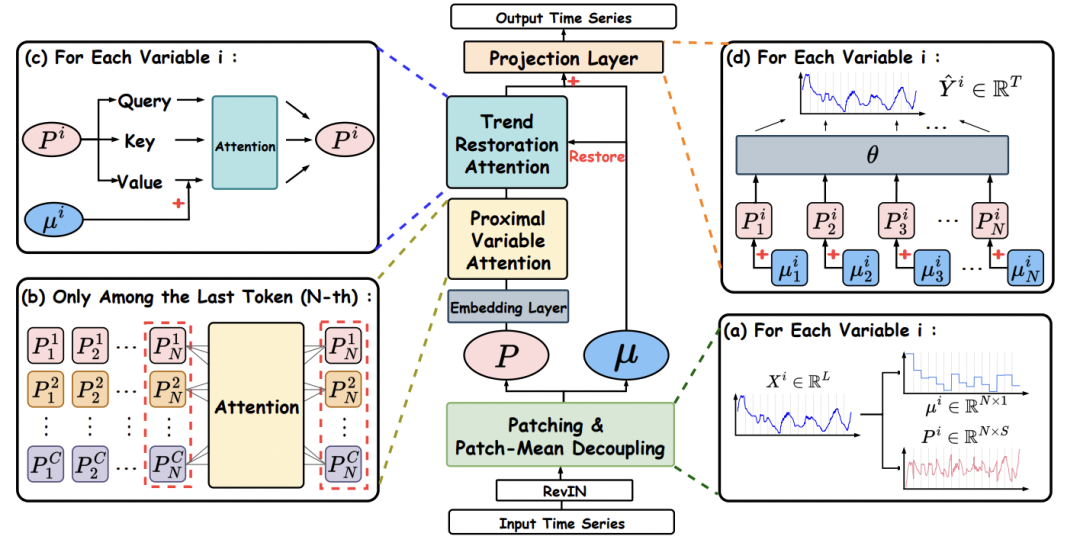 图 2:PMDformer 整体架构图
图 2:PMDformer 整体架构图一、Patch 均值解耦(PMD):还原形状本质
PMD 的核心操作简洁而高效: 对每个 Patch 减去其时间均值,将原始 Patch 分解为长期趋势(均值)和残差形状两部分。与现有 Normalization 方法不同,PMD 仅做均值减法,完整保留了 Patch 内部的振幅变化和形状结构。
二、近邻变量注意力(PVA):聚焦最相关的跨变量依赖
PVA 模块基于一个直觉洞察: 预测目标序列时,变量间在最近时间段的交互关系最具参考价值。因此,PVA 将跨变量的自注意力计算严格限制在最近一个 Patch(第 N 个 Patch)的时序词元(Tokens)上,而非全局历史序列。
这一设计带来双重优势:
一是捕捉最相关的近期跨变量形状相似性, 避免早期弱相关或虚假相关对预测的干扰;
二是将计算复杂度从 O (C²N) 降低至 O (C²), 显著提升计算效率。
三、趋势恢复注意力(TRA):兼顾形状与趋势
PMD 在提升形状相似性建模的同时,客观上削弱了长期趋势信号。TRA 模块专门针对此问题设计:在注意力计算中,Query/Key 通道仅使用形状嵌入(确保注意力分数反映形状相似性),而 Value 通道则通过加法注入 PMD 分离出的 Patch 均值(趋势信息)。
这种分离式设计使模型能够同时编码局部形状模式和全局趋势动态,输出更稳定的预测结果。
实验结果:在 8 个权威基准上全面领先
研究团队在 8 个广泛使用的真实世界数据集上进行了系统评估,涵盖电力、天气、能源、交通等多个应用领域。与 8 个最新基线方法的比较表明,PMDformer 在 7/8 个数据集上取得最低 MSE 和 MAE,展现出稳定且全面的性能优势。
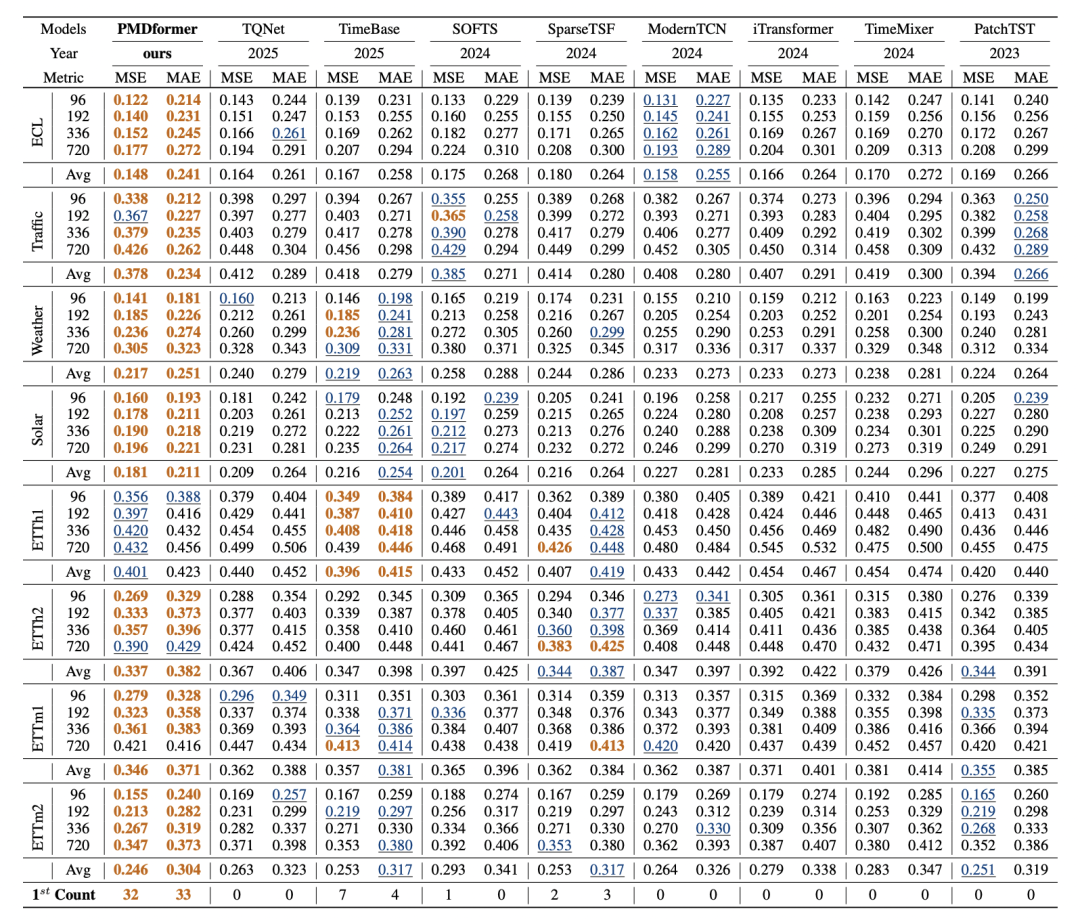
表 1:长时间序列预测任务结果对比。包含 8 个数据集、4 个预测长度(96/192/336/720 步)、MSE 与 MAE 双指标的完整对比数据
计算效率:以更少资源实现更高性能
PMDformer 在计算效率方面同样表现突出。在变量数量从 100 增至 3000、以及序列长度从 144 增至 5400 的两组扩展实验中,PMDformer 相比 PatchTST、iTransformer、ModernTCN 均需要更少的 GPU 显存。这一优势源于 PVA 模块将跨变量注意力复杂度从 O (C²N) 压缩至 O (C²),在高维多变量场景下尤为显著。
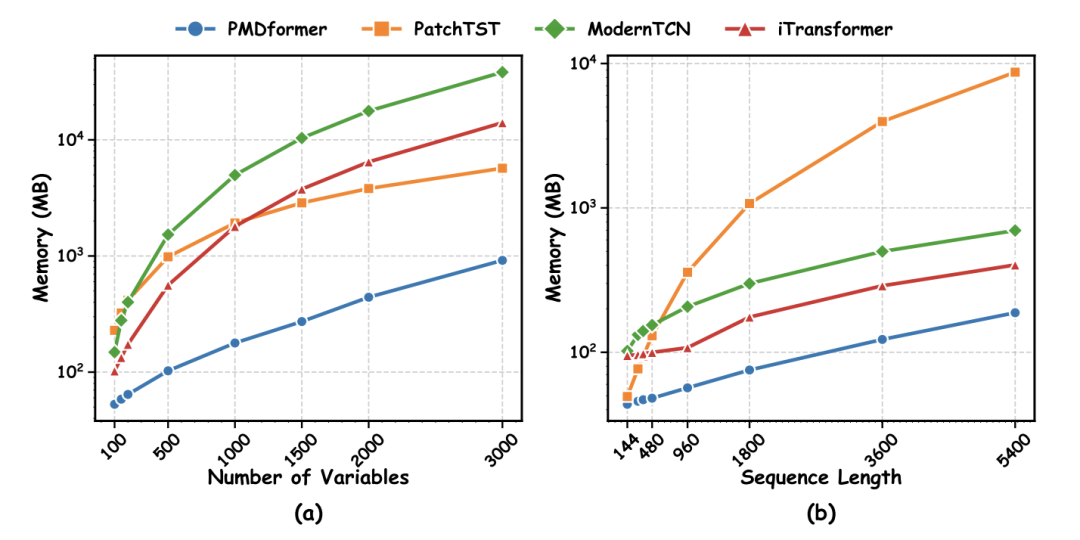 图 3:计算效率对比:不同变量数量(左)与不同序列长度(右)下,各模型 GPU 显存占用对比
图 3:计算效率对比:不同变量数量(左)与不同序列长度(右)下,各模型 GPU 显存占用对比总结与展望
PMDformer 的成功揭示了时序预测领域一个长期被忽视但至关重要的问题: Patch 的均值(趋势)与残差(形状)耦合在一起,会系统性地损害注意力机制对形状相似性的建模能力。
通过一个简洁的均值减法操作,配合精心设计的趋势恢复机制和近邻变量注意力, PMDformer 在不增加模型复杂度的前提下,全面提升了预测精度与计算效率。
接下来,研究团队计划将 PMDformer 扩展至更高维度的多变量时序数据建模,并探索与多模态数据(如文本、图像)的融合应用,为能源、金融、交通等领域的智能预测持续提供新动力。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

