
本文作者分别来自香港理工大学以及四川大学。第一作者江奕飏是来自香港理工大学的博士生,指导老师为李青教授与魏骁勇教授。
长期以来,听障群体在信息获取、公共服务和社会交流中都处于相对边缘的位置。主流社会的大量信息传播方式默认建立在语音和文字之上,这意味着许多依赖手语进行表达和理解的人群,在教育、医疗、政务服务以及日常沟通中,往往天然面临更高门槛。与此同时,当人工智能正在快速改变内容生产、知识获取和人机交互方式时,这部分群体却并没有同等程度地享受到技术发展的红利。如何让 AI 真正服务更多人,而不是只服务于主流交互方式下的多数群体,已经成为一个越来越重要的问题。
也正是在这样的背景下,手语翻译(Sign Language Translation, SLT)的研究显得尤为重要。它不仅关乎一个具体的多模态任务,更关乎如何借助人工智能帮助听障群体更顺畅地接入主流社会,降低沟通壁垒,提升信息可达性与社会参与度。从这个意义上说,SLT 不只是「把视频翻译成文字」,而是在尝试搭建一座连接不同表达体系与社会环境的桥梁。
但从技术角度看,手语翻译远比想象中复杂。长期以来,许多方法默认手语视频中的局部片段可以直接对应到自然语言中的词语或短语,仿佛只要完成逐段对齐,就能得到正确翻译。然而,这一假设在真实场景中并不总是成立。手语表达往往依赖动作轨迹、空间位置、身体朝向以及上下文关系共同构成语义,同一个手型或动作在不同语境下甚至可能表达完全不同的含义。也正因如此,这篇论文提出:手语翻译本质上更接近一种跨模态推理问题,而不只是简单的视频到文本映射。
针对这一问题,研究团队提出了 SignThought。这是一种面向 gloss-free 手语翻译的全新框架,其核心思想是在视频理解与文本生成之间,引入一条有序的 latent thoughts 链条,让模型在生成翻译之前,先逐步组织中间语义表示,再根据这些中间语义去检索视频证据,最终完成更连贯、更忠实的翻译。与此同时,论文还提出了 plan-then-ground 的解码方式:模型先决定「要说什么」,再回到视频中寻找「证据在哪里」。
目前,该工作已被 ACL 2026 Main Conference 接收,并拟推荐为口头报告。

论文标题:Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language Translation
论文地址:https://arxiv.org/abs/2604.15301
代码地址: https://github.com/fletcherjiang/SignThought
研究背景
近年来,gloss-free 手语翻译逐渐成为研究热点。与传统依赖 gloss 标注的方案不同,这类方法希望直接从手语视频生成自然语言句子,避免昂贵而繁琐的中间标注成本。
但真正的困难在于,手语的语义往往并不是由某一个固定手势直接决定的,而是由动作轨迹、空间位置和上下文关系共同生成。如图所示,同样与「车辆」相关的手型,如果只做直接的视频到文本映射,模型可能只能识别出「车辆」和「树」这类表层元素,最终生成类似「一辆车在树旁边」这样的描述;但实际上,手语中真正的含义可能来自运动方向和空间关系本身,例如「车辆」从位置 A 朝位置 B 移动,并与「树」发生交互,这时更准确的语义应是「一辆车撞上了一棵树」。换句话说,同一个与车辆相关的手型,在不同动作方式和空间配置下,可能表达「停车」「撞击」或「行驶」等完全不同的含义。
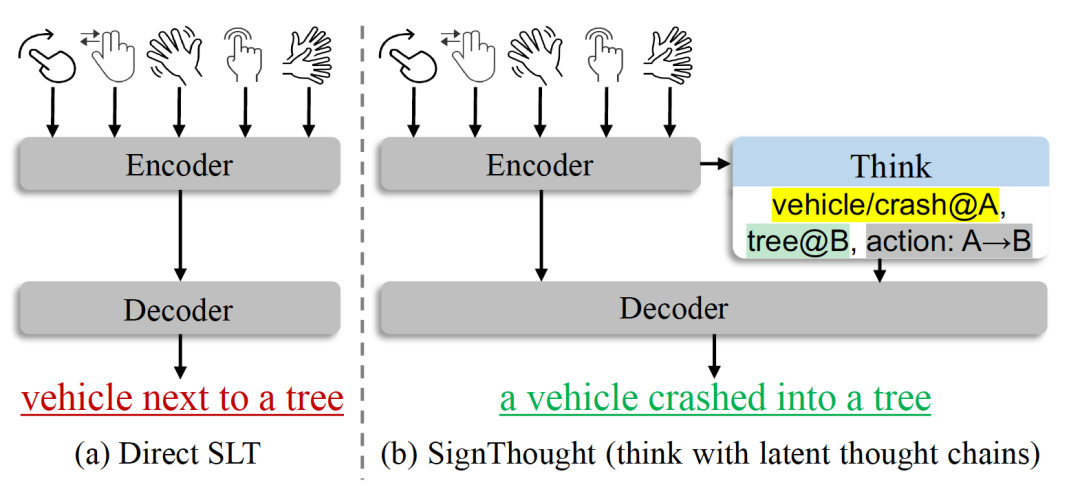
这也说明,现有 gloss-free 方法面临一个关键瓶颈:模型往往需要同时完成两件事。第一,它要决定当前到底应该表达什么语义;第二,它还要在长视频中定位支持这一语义的时序证据。这两件事被强行耦合在一起后,很容易造成语义规划不稳定、注意力分散,或者虽然生成的句子表面流畅,却没有真正对应到视频中的核心语义关系。
相比文本推理任务可以显式维护中间 reasoning steps,手语翻译中的推理更难,因为它横跨视觉与语言两种模态,缺乏天然离散、可直接操作的中间推理单元。也正因如此,这篇论文提出:手语翻译本质上更接近一种跨模态推理问题,而不只是简单的视频到文本映射。论文正是从这里切入,尝试为 gloss-free 手语翻译建立一个显式的中间推理接口。
核心方法
SignThought 的整体框架主要由三部分组成。第一部分是 Sign Encoder ,负责把输入的手语视频编码成稠密的时序证据特征;第二部分是核心的 Latent Chain-of-Thought Thinking Module ,它通过一组可学习的 thought slots,把长视频中的连续证据逐步压缩成一条有顺序的 latent thought chain;第三部分是 Dual-Stream Decoder ,先基于 thought chain 完成语义规划,再回到视频特征中做细粒度 grounding,最终生成翻译文本。
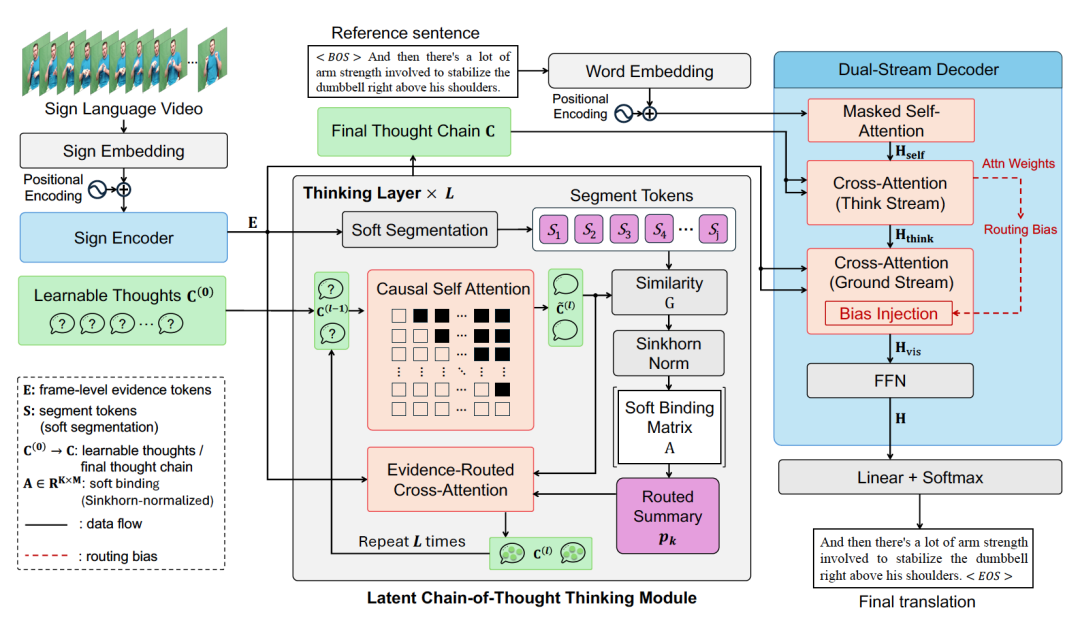
这套设计背后有三个关键点。首先,论文把 latent thoughts 视为视觉证据与自然语言生成之间的中间语义接口,不再把所有信息都压缩进一个黑盒 encoder 表示中。其次,模型通过 plan-then-ground 把「语义决策」和「证据检索」显式拆开,减少两者相互干扰。最后,latent thoughts 不只是内部状态,还能作为可追踪的中间锚点,把生成文本与输入视频中的特定时间区域对应起来,从而提升翻译的 faithful grounding 能力。
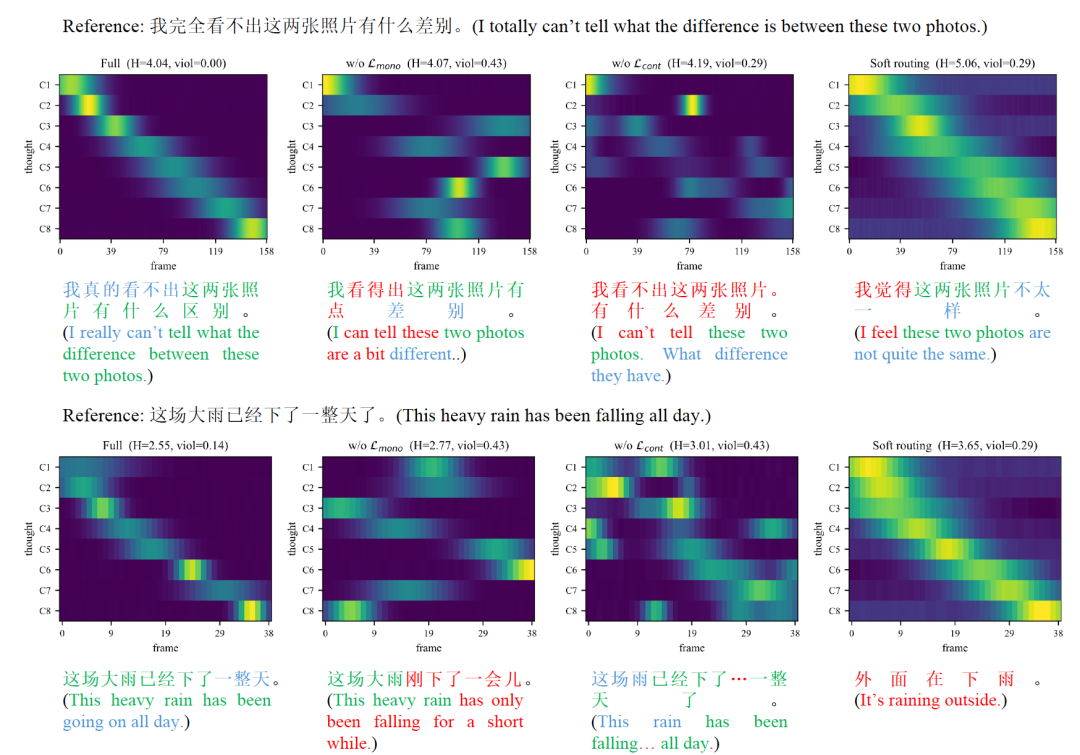 SignThought 的内部推理过程:完整模型能够形成沿时间顺序递进且较为集中的 thought-to-frame 对齐。
SignThought 的内部推理过程:完整模型能够形成沿时间顺序递进且较为集中的 thought-to-frame 对齐。更具体地说,在 thinking module 中,模型先用带有因果约束的 thought 更新机制,让前面的 thoughts 偏向表示较粗粒度的语义,后面的 thoughts 再逐渐补充细节;随后,通过结构化路由机制,把不同时间段的视觉证据分配给不同 thoughts;到了 decoder 阶段,模型会先查看当前最相关的 thought,再根据 thought 对应的时序先验去视频中查找证据。这使得「先想清楚,再去找依据」第一次以相对明确的方式写进了手语翻译模型结构里。
数据集构建
除了方法本身,这项工作还同步构建了一个新的大规模香港手语数据集 LC-HKSLT 。论文介绍,LC-HKSLT 主要来自公开视频场景中的播报式内容,具有持续可见的手语翻译员,并且只保留句子级监督信号,不引入 gloss 标注或 SLR vocabulary,更贴近真实部署环境。

从规模上看,LC-HKSLT 总计包含 1311 小时 的手语视频、 432K clips ,覆盖 14 位 signer ,SLT vocabulary 达到 125,833 。论文还特别说明,完整数据集是在大规模真实场景中收集而来,而本文实验主要使用其中一个精心整理的 30 小时子集 ,以便和现有中文手语翻译 benchmark 保持更可比的评测设置。

这个数据集的意义不只是「更大」。更重要的是,它提供了一种更真实的弱监督训练条件:模型拿到的不是干净、精细的人为对齐标注,而是更接近真实世界的数据形态。也正是在这样的设定下,显式的跨模态推理与证据组织能力才会真正变得重要。
实验结果
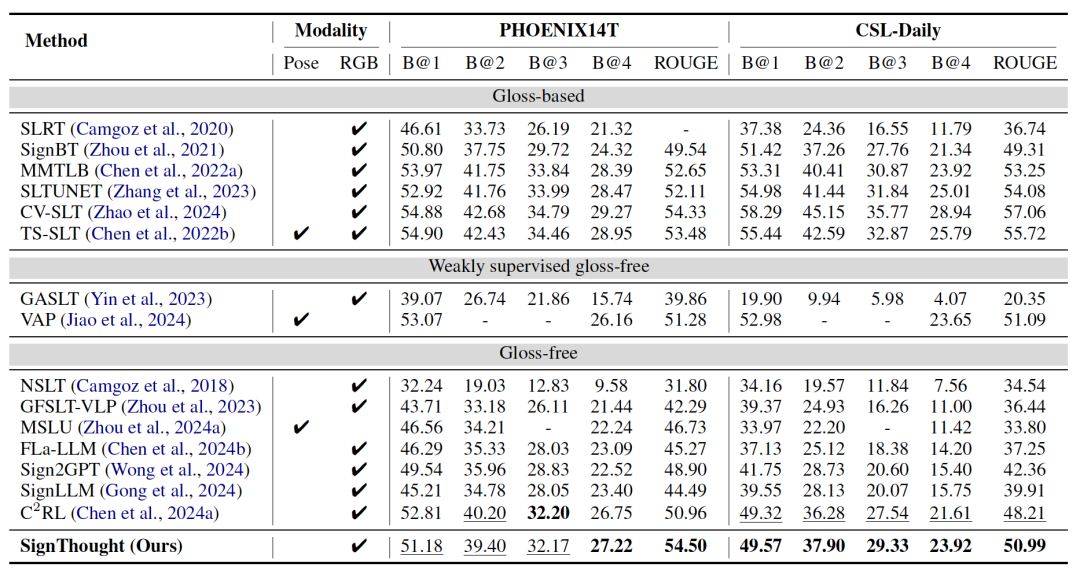
论文在五个手语翻译 benchmark 上进行了实验,包括 PHOENIX14T、CSL-Daily、How2Sign、OpenASL 以及新提出的 LC-HKSLT 。结果显示,SignThought 在这些数据集上都取得了最好的 gloss-free BLEU-4,并且在 PHOENIX14T、How2Sign、OpenASL 和 LC-HKSLT 上拿到了最高的 ROUGE,整体表现非常稳定。
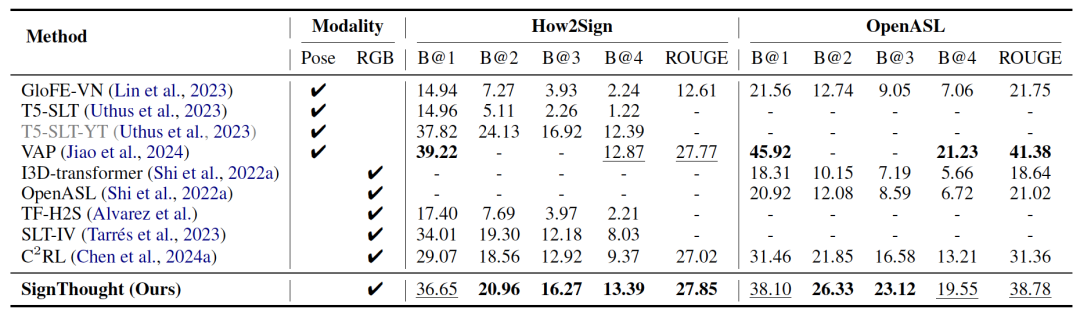
具体来看,在 PHOENIX14T 上,SignThought 达到 27.22 BLEU-4 / 54.50 ROUGE ;在 CSL-Daily 上达到 23.92 BLEU-4 / 50.99 ROUGE 。在更大规模的数据集上,提升更加明显: How2Sign 的 BLEU-4 从此前方法的 9.37 提升到 13.39 , OpenASL 从 13.21 提升到 19.55 。
在自建数据集 LC-HKSLT 上,SignThought 同样取得了很强结果。论文报告,公开设置下模型达到 21.15 BLEU-4 / 47.87 ROUGE ;进一步在其余 LC-HKSLT 数据上进行预训练后,再在 30 小时子集上微调,性能提升到 30.22 BLEU-4 / 60.01 ROUGE 。这也说明,对于手语翻译而言, 大规模、领域内一致的 sign-text 数据 仍然具有非常高的价值。
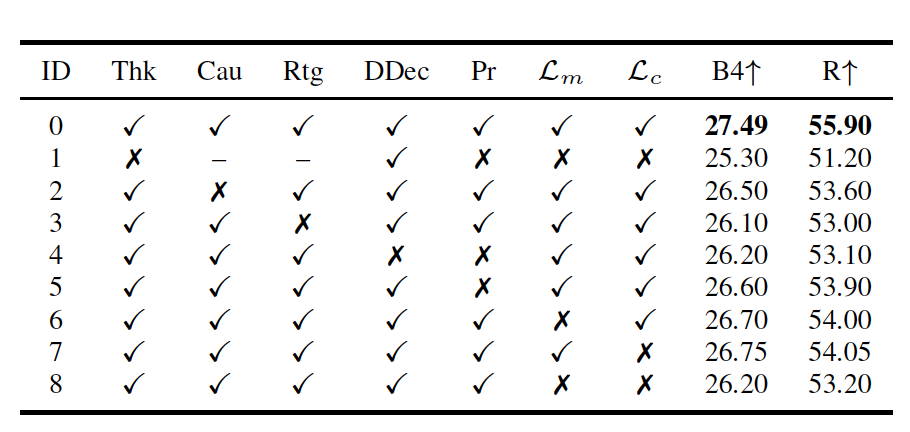
论文中的消融实验也支持了这套设计的有效性。结果表明,一旦去掉 latent thinking module,性能下降最明显;而去掉 causal thought 更新、结构化 routing、dual-stream decoder 或 thought-guided prior injection,也都会带来不同程度的退化。这说明 SignThought 的提升并不来自某个单独技巧,而是 来自「中间推理链 + 路由 + grounding」这一整套机制的协同作用。
总结与展望
这项工作的价值,不只是提出了一个新的手语翻译模型,更重要的是,它尝试重新定义这个任务: 手语翻译不应只被看成视频到文本的映射问题,而应被视作跨模态推理问题。 围绕这一判断,SignThought 给出了一个相对完整的答案:通过 latent thoughts 建立中间语义层,通过 plan-then-ground 解耦语义规划与证据检索,再借助大规模真实场景数据验证这一方向的可行性。
当然,目前模型中的「thinking」仍然是 latent 的,而不是完全显式、可读、可控的人类语言推理链。换句话说,这项工作并不是终点,但它向前迈出了一步:它让手语翻译第一次更明确地拥有了「先组织语义、再 grounded 生成」的中间过程。
对于整个手语语言技术领域来说,这个方向很值得期待。未来如果进一步把 latent planning 与更显式的语义结构、文本 rationale 或可控推理机制结合起来,手语翻译模型或许不仅能给出更准确的输出,还能更好地解释「为什么这样翻译」。而这,也可能成为下一阶段多模态理解与生成系统的重要突破口。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

