IT之家 5 月 30 日消息,英伟达昨日(5 月 29 日)发布博文,宣布携手香港理工大学、南京大学等,推出 LocateAnything 模型,主打高速、高精度检测对象。
该模型可以从照片或截图中找出指定对象,并用检测框标出位置,重点服务机器人感知、电脑自动操作等需要快速定位的场景。

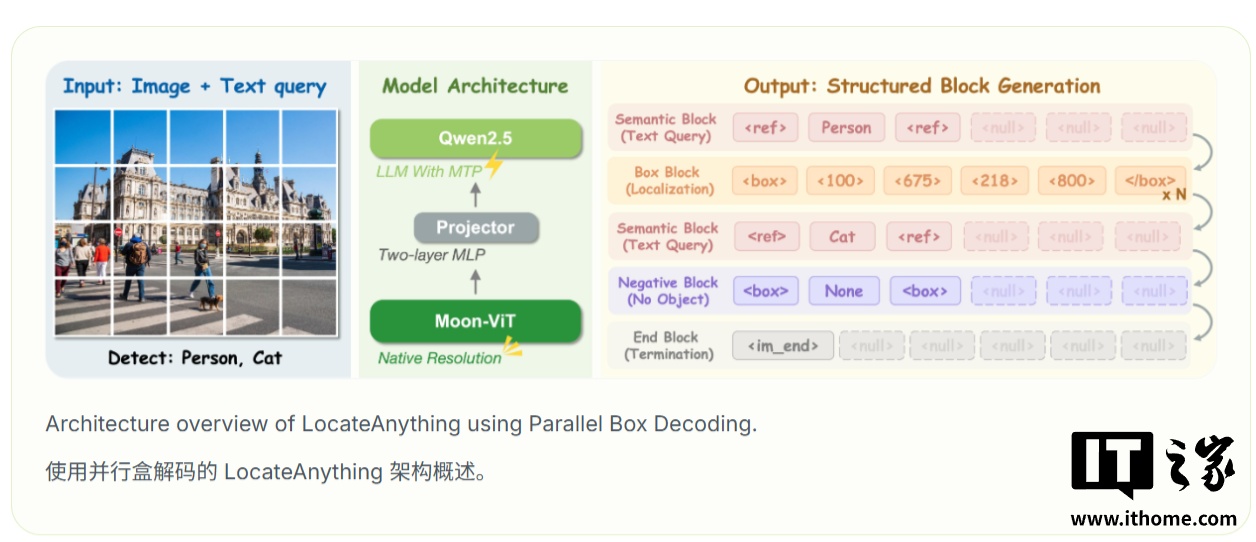
NVIDIA 在介绍中强调,机器人和 AI Agent(智能体)仅能“看见”还不够,还必须足够快地确认目标位置。LocateAnything 围绕检测框预测重新设计,让视觉语言检测更适合即时交互任务。

LocateAnything 提出 Parallel Box Decoding(并行框解码),把边界框或点作为固定长度原子单元,在 1 步内预测 x1、y1、x2、y2。
该框架提供 Fast Mode、Slow Mode 与 Hybrid Mode:
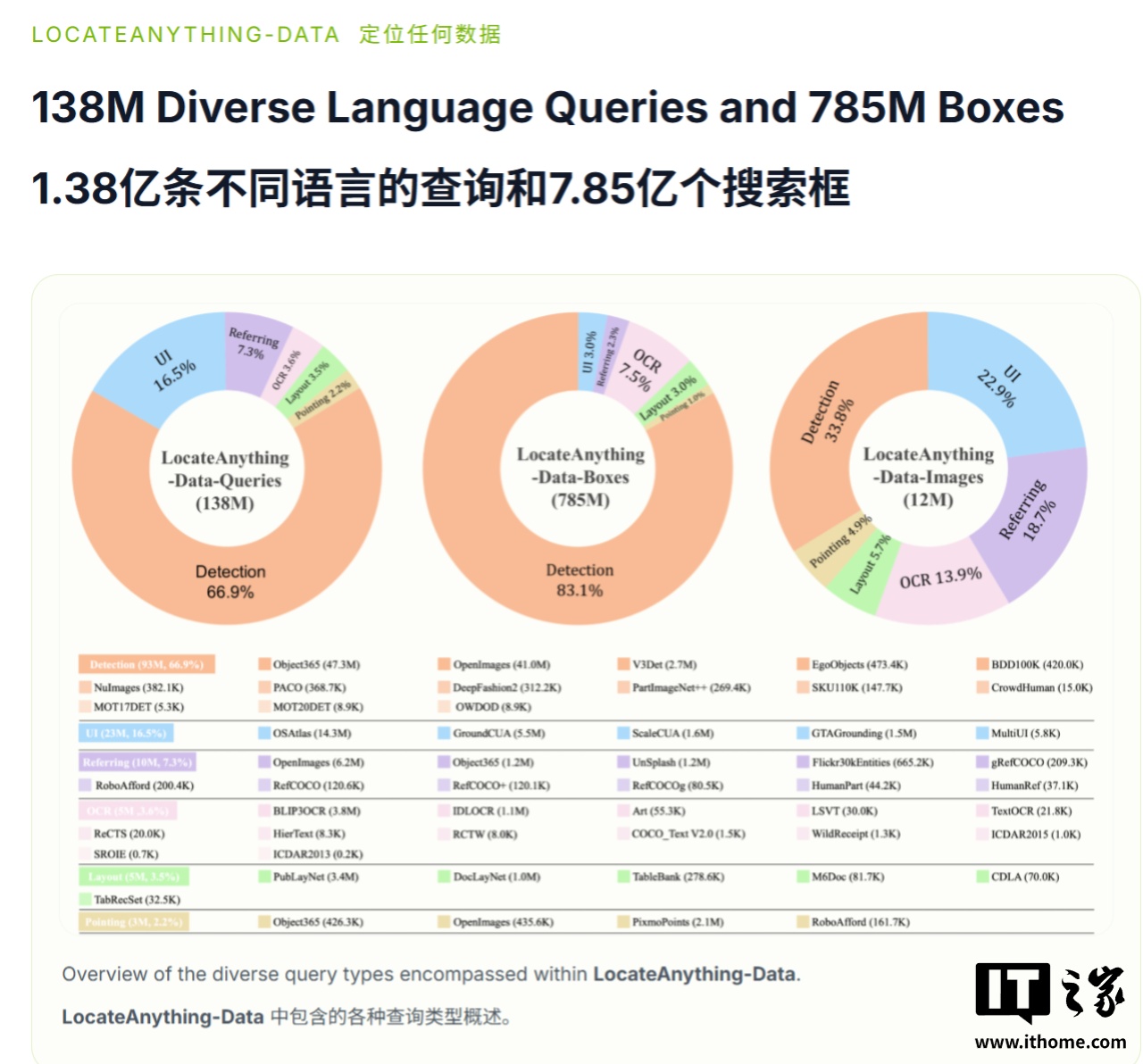
团队还构建 LocateAnything-Data,包含 12M 独立图像、138M 语言查询和 785M 边界框。数据覆盖通用检测、GUI 元素定位、指代表达理解、OCR 文字定位、版面定位和点定位,显著扩展训练场景。

在单张 NVIDIA H100 GPU 上,LocateAnything 默认 Hybrid Mode 达到 12.7 Boxes Per Second(每秒框数),超过 Qwen3-VL 的 1.1 BPS,也高于 Rex-Omni 的 5.0 BPS。
高精度任务中,LocateAnything 在 LVIS 的 IoU=0.95 下得分 31.1,高于 Rex-Omni 的 20.7;ScreenSpot-Pro 平均 F1 达 60.3;DocLayNet 和 M6Doc 分别达 76.8 与 70.1。
IT之家附上参考地址
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>未经允许不得转载:紫竹林-程序员中文网 » 英伟达推出 LocateAnything,主打 AI 高速、高精度检测对象


