来源:DeepTech深科技

最初相同的 DNA ,为何最终有的长成神经元,有的成为血细胞,有的是胰岛细胞?
数十年来,生物学家理解细胞会分化,但一个长期来很难准确预测的问题是:如果改动一个关键基因,细胞命运将发生怎样的改变?
现在,一个新型 AI 模型开始尝试回答这个问题: 作为可操作的计算机模拟 “ 细胞模型 ” ,模拟调控扰动并生成可验证、解释细胞命运决定机制的假说。
近期,德国亥姆霍兹慕尼黑中心 Fabian J. Theis 教授和英国牛津大学 Tatjana Sauka-Spengler 教授团队合作,开发了一种端到端的深度学习模型 RegVelo ( Regulatory Velocity ),首次将神经网络与细胞动态变化过程融合在同一框架中。
具体而言,研究人员通过结合微分方程和神经网络建模细胞内部的调控方式,对细胞的动态表达数据进行拟合,这样可以通过计算机模拟改变基因调控关系(例如敲除某个转录因子、下调调控特定回路),来预测细胞的命运将如何改变。
值得关注的是,研究团队将 RegVelo 应用于多个复杂的多谱系分化系统, 无论在小鼠胰腺内分泌发育、人类造血分化,还是斑马鱼神经嵴发育,该模型都表现出稳定且相对准确的终端状态识别能力。
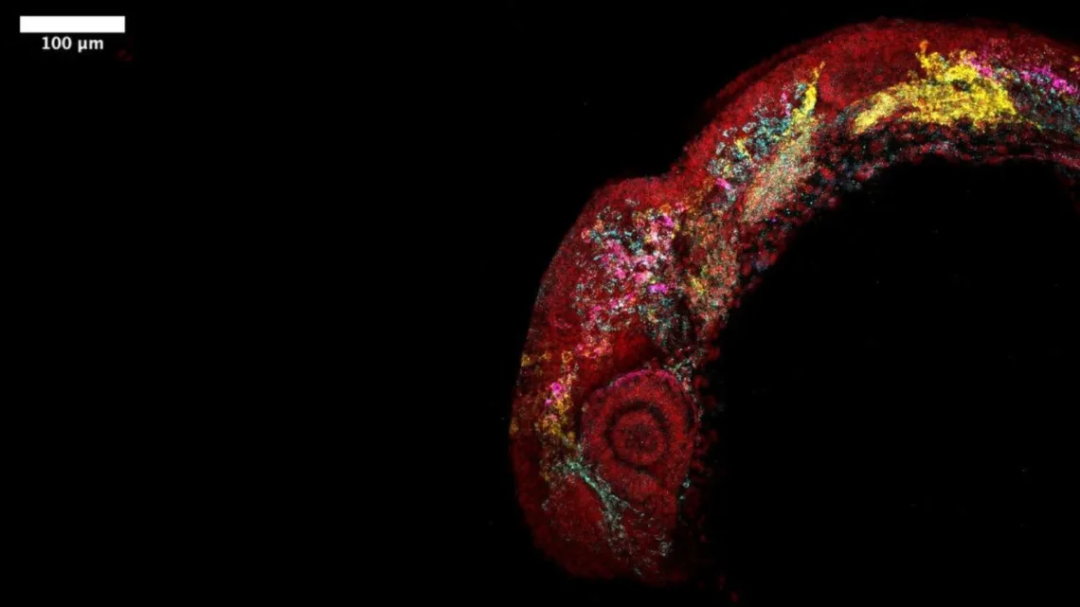
RegVelo 测试动态生物系统类型,图为斑马鱼胚胎的荧光成像显示早期发育过程中的细胞群(来源:受访者)
可以这样来理解这项研究: RegVelo 从观测细胞运动的轨迹,同时推断驱动运动的内在调控逻辑,并用这个逻辑预测干预调控后的新轨迹。
该论文第一作者、亥姆霍兹慕尼黑中心博士生汪伟旭的研究方向是从调控网络预测细胞的分化的构建过程,他对 DeepTech 解释道: “ 这就像我们考驾照科目三时,不同的考生(目标基因)和考官(转录因子)的组合会有不同的行车结果,我去理解考官去调控考生的机制,最后可以告诉你,如果换一个考官或干脆不要考官了,科目三能不能过(即你的行车轨迹是满分)。 ”
电脑模拟实验是 RegVelo 的应用方向之一。汪伟旭认为,更令人兴奋的场景是类器官研究。 类器官领域最大的瓶颈并非能否长出细胞,而是分化效率不稳定、细胞成熟度不够、某些关键细胞类型难以诱导出现,这三个问题背后都指向同一个核心问题:哪些转录因子在哪个时间窗口驱动了正确的分化,而这恰好适合 RegVelo 来回答的问题。
具体来说,可在现有类器官单细胞数据上建模调控动态,然后在计算机预测 “ 如果在某个发育窗口激活或抑制某个转录因子情况下,最终的细胞组成会如何变化 ” ,再把最有希望的几个预测进行实验验证,把分化协议的优化从纯粹的实验试错压缩到计算引导的定向验证。
更进一步,对于类器官疾病模型,可以用患者来源的诱导多能重编程干细胞( iPSC )建立模型,在计算机里模拟不同的基因干预,预测哪些干预能把异常的细胞命运纠正回正常轨道,这让 RegVelo 有潜力成为药物靶点筛选的前端计算平台。
总体来说,这项技术为发育生物学、再生医学和疾病机制研究提供了一种具有预测扰动和分析扰动后结局的工具,有望显著减少功能筛选实验的盲目性,通过优先验证计算预测排名靠前的候选因子,进而加速关键调控因子的发现进程。

Cell )
近日,相关论文以《 RegVelo :基于基因调控信息的单细胞动态变化建模》( RegVelo: Gene-regulatory-informed dynamics of single cells )为题发表在 Cell [1] 。亥姆霍兹慕尼黑中心博士生汪伟旭和武汉大学胡致远教授,纪念斯隆 – 凯特林癌症中心 Philipp Weilier 博士是共同第一作者,姆霍兹慕尼黑中心 Fabian J. Theis 教授和牛津大学 Tatjana Sauka-Spengler 教授担任共同通讯作者。
细胞命运,究竟是谁决定的?
要理解用最基础的功能单元做虚拟细胞的意义,我们要先从虚拟细胞的历史演进讲起。 1943 年,埃尔温·薛定谔( Erwin Schrodinger )在都柏林高等研究院期间的演讲,后来被总结成一本书《生命是什么》。
很多人不知道的是,这本书的副标题是《活细胞的物理学方面》( The physical aspect of the living cell ),这也是最早思考活细胞底层的物理学原理:细胞作为最小功能单元是有序的,而彼时统计热力学正探讨如何从无序产生有序。
这与格雷戈尔 ·约翰·孟德尔( Gregor Johann Mendel )豌豆杂交实验揭示的遗传决定论存在冲突,即存在 “ 有序到有序 ” 的过程。薛定谔提出两个推测:一是遗传物质如果要稳定并储存信息,必须是非周期性晶体;二是生命依靠负熵而活,即我们通过外界的食物和其他负熵体来维持自身的有序性。
此外他还推测,应该有新物理或新理论解释遗传秩序(即基因里的秩序)如何放大到整个有机体。这套想法为现代分子生物学和生物信息学奠定了重要的基础,他较早将信息概念引入生物学,并为细胞观提供了一种机械论视角。
非周期性晶体的思想启发了科学家,最终促成了 DNA 双螺旋的发现, “ 从有序到有序 ” 的认识则为弗朗西斯 ·克里克( Francis Crick )提出中心法则( central dogma )提供了重要的思想基础。
但细胞尺度的有序性如何建立仍待回答:相同遗传物质如何决定不同细胞类型? DNA 序列改变如何产生新细胞类型?外部信号能否转换细胞状态? 2024 年,斯坦福大学教授、著名研究机构陈 – 扎克伯格倡议( Chan Zuckerberg Initiative, CZI )的科学主管斯蒂芬·奎克( Stephen Quake )将此称为 “ 细胞法则 ” ,它被看作虚拟细胞的真正母题,而并非简单的扰动预测。
1957 年,英国发育生物学家康拉德·沃丁顿( Conrad Waddington )提出了著名的景观隐喻模型 Waddington 景观:细胞发育的过程就像小球(细胞)从山顶滚入山谷,其中山顶分化势能最高,最终进入山谷并分化成当不同的终末细胞类型。他认为,景观之所以被塑造是复杂的遗传物质之间的调控网络塑造决定了细胞分化的方向。
该理论也启发了系统生物学家们从 21 世纪初开始研究基因调控回路问题,但受限于理论和硬件方面的约束,当时由于缺乏解数千个基因的动力学方程模型的数值求解器,只能用经典动力学研究相关过程。
随着 2010 年代单细胞测序技术( scRNA-seq )成熟,首次为全基因组尺度观测数据提供了支持。并且 GPU 和深度学习技术也开始发展,出现了混合模型( hybrid model ):常微分方程提供动力学骨架,神经网络从数据中学习未知调控关系, GPU 求解器使高维计算可行。
因此,从 “ 细胞作为信息处理单元 ” 的历史发展演进来看, Waddington 的景观提供了隐喻,系统生物学把它变成方程,而混合模型则将其进一步发展为可以从数据学习的计算问题。
为什么之前的模型会 “ 看反 ”
如何检验模型真实有效,并在生物数据中具备一定泛化能力,这是 AI for Biology 的常见问题之一。 RegVelo 想要解决的核心问题是: 细胞的分化是如何被基因调控回路确定下来的?
如果从目前的 AI 系统去看,不难发现其最擅长的是有明确信息流动的,即 “ 从有序到有序 ” 的过程。比如蛋白质折叠问题,从一级氨基酸序列到三维空间结构,有着明确的带边界的状态空间。
所以,对于 AI 系统来说要在生物数据中能走通,有时候问题能否被解决,不只取决于数据规模或模型架构,更根本的是问题本身是否被正确地表达——能否找到一个有明确信息流动方向的有序框架来定义输入和输出。特别是当问题的输出并不是有序时,能否放在一个有序的框架下进行检验。
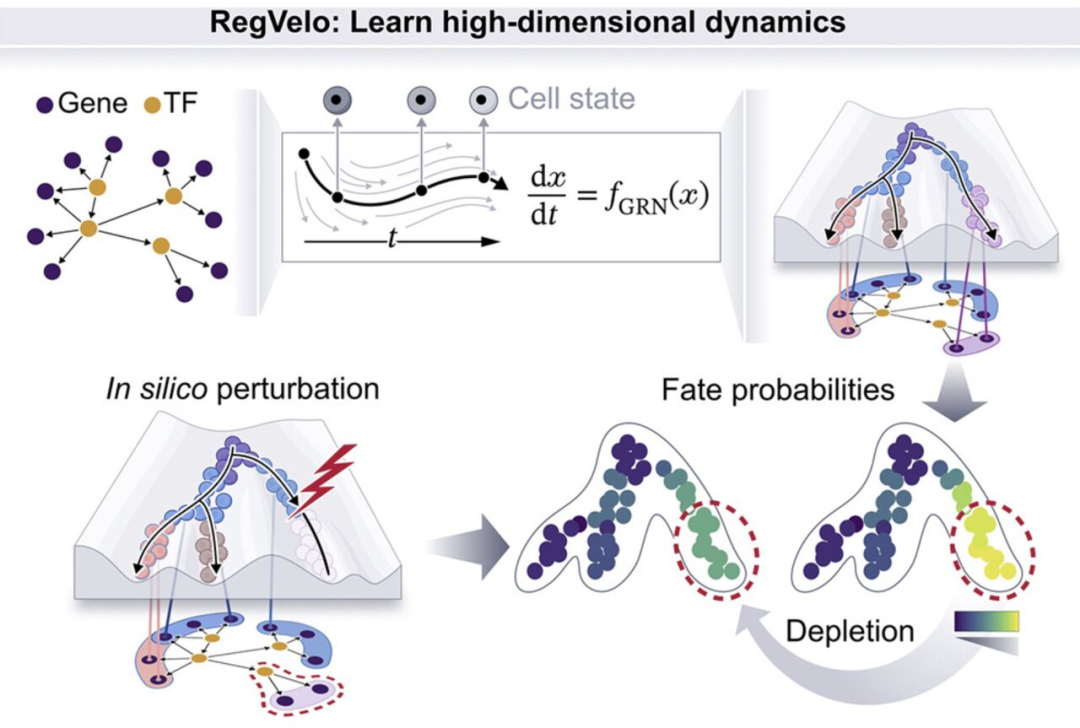
RegVelo 通过将单细胞 RNA 测序数据与先验知识相结合来推断调控动态;将转录过程建模为可实现基因动态耦合的受调控过程;结合 CellRank 技术可实现计算机模拟中的调控扰动及细胞命运预测;神经嵴发育模型研究证实 elf1 是色素命运的调控因子(来源: Cell )
在这项研究中, RegVelo 在得到速度场后,研究人员可以预测细胞分化的终态在哪,从对分化终态的预测中来判断模型好坏。汪伟旭表示: “ 在这项研究中我最满意的设计,是结合我们课题组建立的一套描述细胞命运的框架 CellRank 。 ”
该框架提供了在给定速度场下描述细胞命运的分化概率,可以研究在扰动后不同细胞命运的概率变化,以得到最终去往某个状态的可能性高低的改变,甚至是估计最终成熟的细胞状态细胞密度的变化。在得到一个有序的、可被实验去直接检验的统计量之后,可直接和 Perturb-seq 实验对齐,来判断模型是否有效。
“ 所以, AI for Biology 在未来很长时间内的真正边界,可能不是算力,不是数据量,而是生命过程中有多少东西可以被合法地表达为有序到有序的映射。 ” 汪伟旭指出,这也是他认为目前 AI in life science 的研究者该做的事情,不是换一个模型架构,也不是 scale up 到更大的数据集,而是结合 AI 知识和对生物学实验的理解,判断出一个合适且可放在实验体系下证伪的问题,优先级高于前两者。
11 次敲除实验, AI 预测准确率接近翻倍
传统的 RNA 速度模型假设转录速率是恒定的或只有一次 “ 开关 ” ,但该假设在造血系统等场景下不成立。
在造血场景中,由于转录速率并非恒定不变,而是与细胞状态密切相关,因此经常会出现一种反常现象:当许多基因实际上处于极强的转录诱导状态时,模型却错误地判断它们处于抑制状态。这导致最终推断出的速度场与已有的生物学认知完全相反。
RegVelo 之所以能够改善这一问题主要基于两点:一是尝试拟合更灵活的动力学轨迹 ;二是认为每个基因的转录速率受上游的转录因子的影响,即建模每个基因的转录速率并非恒定,且表示成由转录调控网络介导的上游调控因子的作用,也可以理解为当前细胞状态来决定转录速率。
汪伟旭进一步补充道: “ 但是,在一些造血系统的数据集中, RegVelo 也不能完全解决,这背后可能是说转录速率不光受调控网络本身的影响,还有一些其他未能观测的部分。 ”
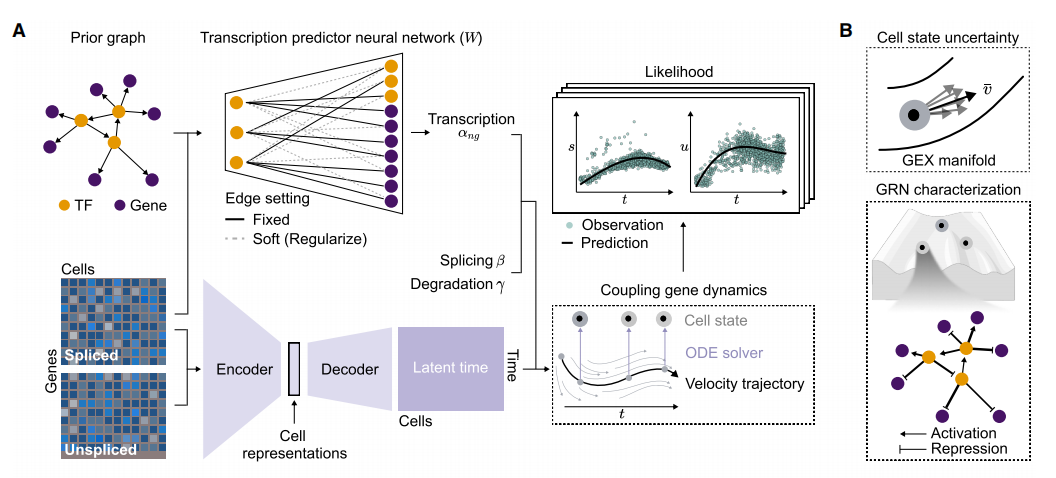
RegVelo 的核心模型(来源: Cell )
研究团队在斑马鱼上做了 11 种转录因子敲除, RegVelo 的预测结果与实际实验数据的斯皮尔曼相关性达到 0.52 ,而其他方法都低于 0.25 。
由于不同方法定义扰动输出的形式不同,研究人员提出了 “ 密度变化似然 ” ,以将所有的方法用同一种统计量来对其 Perturb-seq 实验的结果。在该实验中,他们通过观察终末分化细胞类型中扰动前和扰动后细胞密度的变化,来判断是否存在消耗或者富集。
具体而言,假如在模拟中有扰动前和扰动后的速度场,可以在计算机中模拟一个细胞如何沿着这个速度场,最终抵达终末分化的细胞类型,同时重复模拟该过程多次。
汪伟旭指出, 这就像有多个细胞不断迁移最终抵达终末的细胞类型,可以直接统计最终终末细胞类型中成功抵达的细胞数量在扰动前后的变化,这样能和实验统计的结果在定义上具备了可比的条件。
谈及能够实现接近翻倍准确率提升的原因,他坦言, “ 这要得益于我们的合作者胡致远教授和 Sauka-Spengler 教授在实验环节的巨大贡献。 我们做的斑马鱼实验是真正意义上在斑马鱼体内发育过程的扰动,这使得实验本身和 RegVelo 的计算模拟是对齐的。 ”

Fabian J. Theis 、 Tatjana Sauka-Spengler 和胡致远(来源:受访者)
在研究实验中, RegVelo 有个有意思的预测现象:它能识别发育过程中早期高表达、但在终末状态已经下调的谱系驱动因子。这类因子通常只在较早的发育窗口中表达,等到细胞抵达终末状态时,其 mRNA 信号可能已经减弱甚至消失。因此,依赖终末细胞类型高表达关系的方法容易将它们漏掉,或把其误归为早期或中间状态的标志基因。例如, ets1 、 nr2f5 、 sox9b 和 twist1b 等颅面间充质相关转录因子在神经嵴板和脱层阶段高表达,在终末状态中显著下调。
相关性方法和部分扰动预测方法将这些因子指向 mNC hox34 等状态; RegVelo 则通过基因调控网络( GRN )约束下的前向模拟,将它们识别为颅面间充质谱系的早期驱动因子。
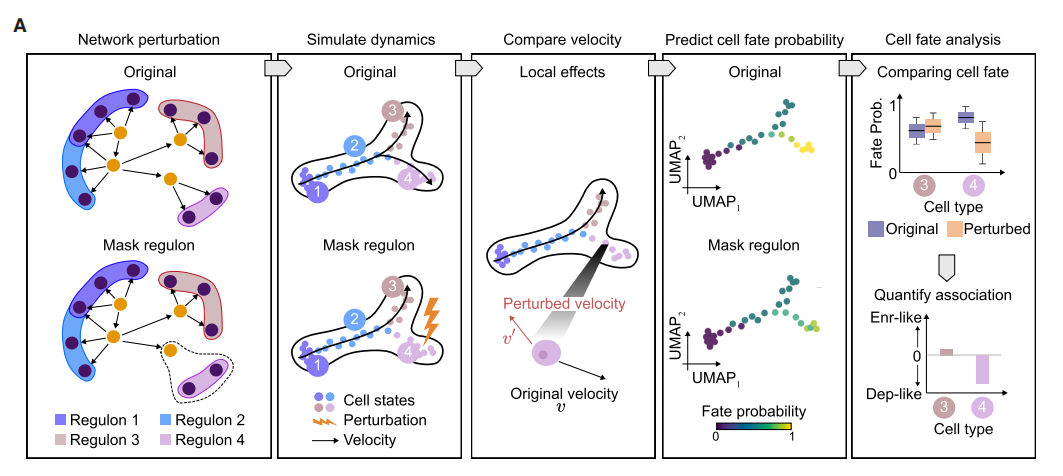
RegVelo 的扰动预测流程(来源: Cell )
但另一个问题是,生命体有复杂的冗余机制来维持其系统稳定。例如,研究人员在实验中观测到,有些转录因子在过去报道中与第二咽弓细胞的发育有关,但他们实验上发现,敲除这些转录因子并不会影响第二咽弓的发育。
“ 这背后一种解释是,会存在其他功能类似的转录因子通过复杂的反馈调节机制,来提高其产物丰度从而继续维持功能。 ” 汪伟旭表示。
当外部信号来敲门: CellFlow
在单细胞计算领域, Fabian Theis 课题组早期做了一系列奠基工作:从单细胞数据设计的数据结构标准 AnnData ,到 Python 单细胞分析主流的基础工具库之一 Scanpy ,再到单细胞深度学习 scGen 等。
在虚拟细胞方向,除了从物理细胞层面出发的 RegVelo ,研究团队还有另一项从生成模型出发的研究 CellFlow[2] ,这也是 首个基于流匹配的生成框架做表达扰动问题的方法 。
“ CellFlow 主要是回答我所提到 细胞学说( cellular dogma ) 的第三点:外部的一些信号刺激下,细胞状态能否实现转换。 ” 汪伟旭表示。实际上,这正是当下虚拟细胞问题主流的定义,即给定形态因子(例如 CRISPR 、细胞因子或药物)后,细胞的表达状态如何从 A 变成 B 。
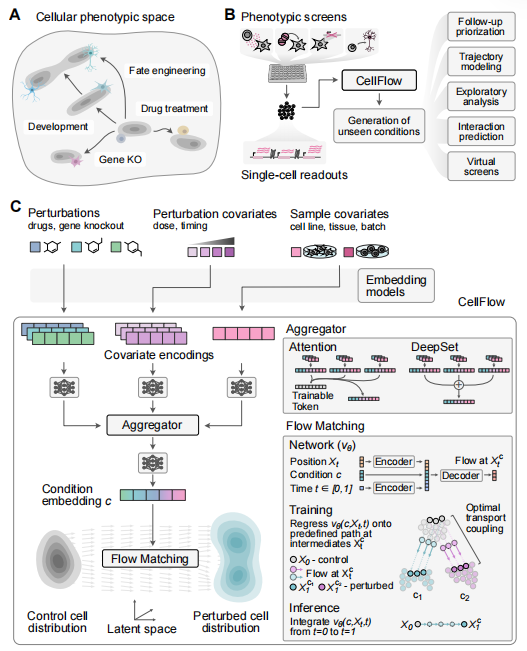
CellFlow (来源: bioRxiv )
虚拟细胞领域中最早的扰动模型,可以追溯到 Theis 课题组 2019 年发表在 Nature Methods 的 研究 scGen[3] ,这也是最早关于扰动问题的定义。但它是基于 VAE 的简单架构,且并未直接对外源的形态因子的信息作为输入直接建模。
随着单细胞测序技术通量越来越高,围绕大规模的扰动实验成为可能后,研究团队希望通过强大的生成模型,从扰动数据中学到扰动效应和形态因子的表征之间的统计关联。
应用流匹配模型的优势在于:首先,它具有可扩展性,能够进行十亿级别数据的训练;其次,在目前已知的很多场景中,它的生成效果优于很多其他模型。未来,可基于该生成模型做类似类器官的分化方案设计,或直接给定生成目标,基于该模型逆向地合成形态发生素,即用怎样的 CRISPR 来引导细胞去生成目标状态。
距离真正的虚拟细胞,还有多远?
目前, RegVelo 仍存在一些局限性:首先, RegVelo 对全局潜在时间的处理仍可能无法覆盖所有基因特异性的时间动态;其次,虽然模型可利用来自多组学数据的先验 GRN ,但当前调控模型仍较简化,对 TF 活性、染色质可及性和更复杂非线性调控的直接建模仍然有限;此外,对 GRN 调控边稳定性的重采样评估通常需要多次重复训练模型,计算成本较高。
未来如果进一步整合代谢标记 RNA 、染色质可及性、 TF 活性、 RNA 结合蛋白互作和蛋白层面的信息, RegVelo 对细胞状态变化的模拟维度还可进一步扩展。另一个重要的问题是,现阶段 RegVelo 尚未形成整合空间转录组数据的能力,而空间组织恰恰是类器官的核心特征之一。
在本次研究中仅考虑细胞内部调控机制,但并未回答当存在外部信号输入时,比如空间上的微环境或加药后如何修改内部的调控逻辑。在未来的研究阶段中,研究团队计划继续探索这些问题。
目前,该课题组与谷歌、英伟达等大型企业在 AI 科学家、虚拟细胞等方面进行项目合作。 RegVelo 和 AI 科学家的交叉点在于: RegVelo 提供的是一个有物理约束的专有模型,它生成的预测是结构化的、可解释的假设;而 AI 科学家提供的是对这些假设进行推理和优先级排序的能力。
两者的结合,正好对应了 AI for Science 最合理的分工方式:将模拟细胞功能的各种专有模型部署到智能体中,通过这些专有模型生成假设,同时通过智能体的推理能力,来判断这些假设是否和已知的知识冲突,从而生成可信的新假设进行验证。
这里涉及到一个更根本的问题:学界和工业界在 AI for Science 中应该如何分工?在汪伟旭看来, 学界 需要做的是在细胞的尺度上,找到并定义一些特定的场景,对应了某种有序到有序、信息流动方向明确的问题;而 工业界 可以通过更强的算力和新模型框架,从工程上把这个问题解决。
“ 不同的专有模型,就像在乐团中扮演不同的角色,有人弹钢琴、有人吹小号、还有人唱歌,进而各司其职去执行模拟细胞不同功能。智能体就像一个指挥家来协调不同的功能,来创造优美的旋律:通过产生合理的假设,引导后续的实验设计。 ”
另一个重要的问题是, RegVelo 所代表的细胞模型与目前 Evo 以及 AlphaGenome 代表的基因组学模型长期脱节。因此,未来研究团队希望能关联两者,直接耦合从基因组到细胞命运调控。希望届时 RegVelo 可以回答细胞学说的关键问题:当引入一些基因组上的突变,特别是调控元件上的突变后,最后如何影响细胞的命运。
参考资料:
1.https://www.cell.com/cell/fulltext/S0092-8674(26)00457-5
2.https://doi.org/10.1101/2025.04.11.648220
3. https://doi.org/10.1038/s41592-019-0494-8
排版:胡巍巍
注:封面/首图由 AI 辅助生成
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

