维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道!

<p style="color:#222222; margin-left:16px; margin-right:16px; text-align:center"><span><span><strong><span style="color:#1d51ce"><span style="background-color:#ffffff">背景介绍</span></span></strong></span></span></p> 在云环境中,如何实现高效、准确的可观测性以保障系统的稳定性和性能成为一个重要问题,尤其在金融行业信创改造进入深水区,核心系统的全生命周期管理面临分布式架构演进、全栈国产化替代、安全合规强监管的三重攻坚挑战,传统的监控工具和方法已经难以满足当前复杂系统的需求。
挑战
某金融企业在信创改造过程中,首先就面临着数据格式不统一、数据源太复杂等难题,全栈可观测性涉及到从应用调用到底层基础设施的各个环节,包括应用性能指标、分布式追踪、网络性能指标、资源变更事件、函数性能剖析等,这些数据量庞大且复杂,需要综合多个维度进行分析和关联。这时传统的人工解读方法往往需要耗费大量的时间和精力,并且由于全栈可观测性的数据来源广泛,涉及到多个技术栈和领域的知识,非常容易出现遗漏或误解。
其次,目前大语言模型的训练和推理过程 GPU 利用率较低,现有工具例如 NVIDIA Nsight 无法提供 CPU 函数调用栈导致难以定位具体性能瓶颈函数,而 PyTorch Profiler 虽然能解决此问题但需要精心设计的插桩,性能影响很大。最后,由于云环境的规模和复杂性不断增加,系统需要具有良好的可扩展性,才能确保系统能够随着需求的变化进行平滑扩展和调整。
解决方案
综合以上因素,金融企业开始考虑借助自动化的工具和技术来实现智能分析 Agent 及 LLM 持续剖析。经过多方调研之后,决定采用 DeepFlow 可观测性分析平台。
PART 1 统一多源异构数据采集,打破数据孤岛
DeepFlow 依托 eBPF 内核级探针技术,实现从业务应用层(Python/Golang 推理引擎、vLLM 框架)、云原生基础设施(K8s 容器、Nginx 网关)到硬件底层(CPU/GPU/HBM)的全链路零侵扰数据采集,无需修改代码或重启进程即可捕获网络时延、服务异常比例、显存拷贝等关键指标。
通过内置数据模型自动标准化处理日志、指标、追踪数据,支持 Prometheus、OpenTelemetry 等协议接入,并兼容 NVIDIA DCGM、华为昇腾等异构硬件监控数据,解决多源数据格式不统一问题。
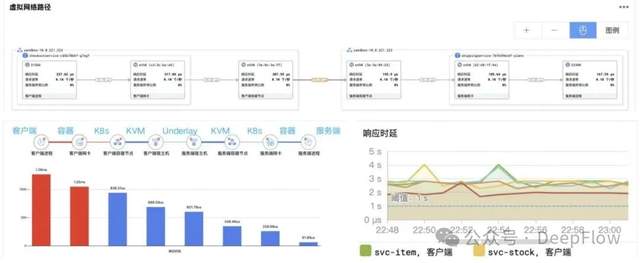
使用 eBPF 采集 LLM 推理服务的全栈性能指标
PART 2 全栈国产化可观测性架构,适配信创改造需求
DeepFlow 深度兼容华为昇腾 910B(正在适配昆仑芯、寒武纪)等国产 AI 芯片,通过 eBPF 实时采集 GPU 内核计算效率、显存分配策略、数据传输耗时等底层指标,为异构硬件选型、配比提供数据支撑。
已实现对麒麟操作系统、统信 UOS 及国产化容器引擎的全栈适配,基于 Kubernetes 架构构建数千节点集群的可观测性管理体系,支持训练 / 推理任务的国产化硬件资源监控与性能优化。

大模型训推平台的可观测性建设
PART 3 全栈函数级性能剖析,精准定位算力瓶颈
DeepFlow 基于 eBPF 技术实现零侵扰的 Python/C++ 函数性能剖析,无需修改代码或重启进程即可实时捕获训练 / 推理业务函数、PyTorch 框架接口、vLLM 推理引擎的底层调用链。通过 eBPF perf sampling 与 uprobe hooks 技术,自动采集 CPU/GPU 运算耗时(On-CPU/Off-GPU)、显存操作(HBM-Malloc/Inuse)、CUDA 内核调用(如 cudaLaunchKernel)等关键指标,生成火焰图与函数调用栈可视化视图。
例如在 vLLM 推理场景中,可精准定位 Python 运行时函数与 CUDA RT 函数的耗时占比,或通过 DWARF 符号恢复技术解析 C++ 库函数的资源消耗路径,为硬件的算力调优提供细粒度数据支撑。
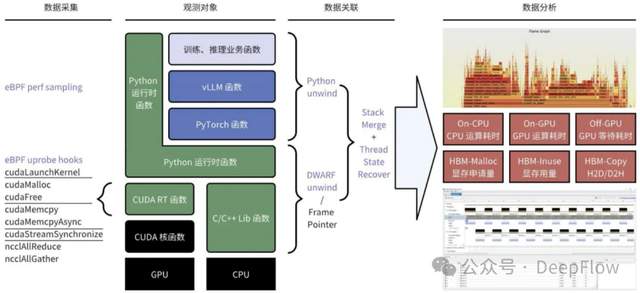
Tracing:使用 eBPF 零侵扰实现 Disk/OSS KV Cache IO 的追踪
PART 4 云原生分布式追踪,构建全链路性能视图
基于 eBPF 无插桩技术,DeepFlow 实现对 Python/Golang 推理引擎、分布式服务网格(如 Envoy)、KV 缓存 IO 的全链路调用追踪,自动关联客户端请求到服务端推理的全路径时延(TTFT/TPOT)、Pod 间网络通信损耗及文件读写耗时。
例如,在 DeepSeek API 场景中,通过追踪硬盘缓存读写链路,精准定位重复输入场景下的缓存命中率,助力降低推理时延 50% 以上。

PART 5 智能排障与自动化分析,提升故障定位效率
DeepFlow 智能体集成大语言模型与自动化运维能力,实现“分钟级巡检-秒级诊断-自动化决策”闭环:通过持续剖析 vLLM+Ray 推理服务的函数调用栈,预测 GPU 算力瓶颈与显存 OOM 风险;自动关联网络层 TCP 重传、硬件层 HBM 带宽占用、应用层推理错误率,生成根因分析报告,实现故障定位时间从小时级缩短至 5 分钟内。
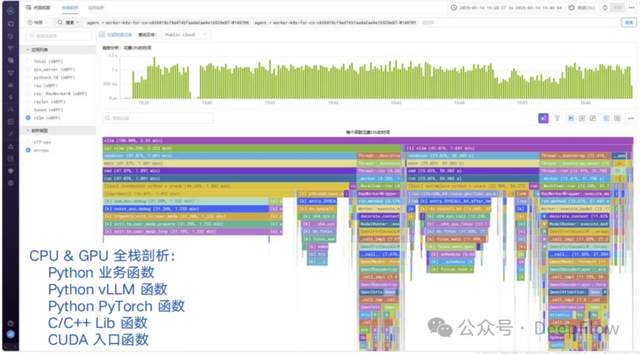
使用 Profiling 剖析 vLLM+Ray 推理服务 快速定位推理服务 GPU 算力使用瓶颈点
实践效果
以往,云内出现性能故障时,不仅需要排查应用调用环节,还需要排查关联的底层基础设施,且排查问题涉及到多个技术栈和领域的知识来判断诊断方向,人工解读往往需要具备广泛的专业知识和经验,导致过分依赖于专家,耗时耗力。以下是 DeepFlow 智能体的实践用例,为IT团队提供从日常巡检到快速诊断的全方位支持。
业务拓扑智能分析
利用 DeepFlow 业务全景图可以轻松观测到每个服务的性能,这是一个有异常的业务系统,获取到这个业务系统的拓扑,点击智能分析选项后得到排查结果,包括瓶颈分析、根因分析和优化建议。根据给出的提示,访问数据库服务时,建联指标异常,建议先检查数据库服务。在检查数据库服务后,发现确实是服务端服务异常,和 DeepFlow 智能分析结果一致。靠谱的分析能力,帮助用户节省了80%的分析诊断等待时间。
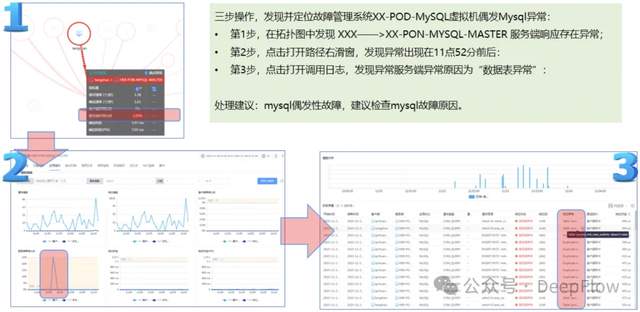
故障诊断/隐患挖掘——3步1分钟,诊断数据库偶发性异常
持续剖析诊断
利用 DeepFlow 调用链追踪可以获取到系统的火焰图,选择需要分析的系统进行智能分析,只需几分钟,同样能获取到这个应用的性能分析、根因分析和优化建议。可以看出,智能分析降低了运维门槛,非专业人员也能快速获取信息,减少对专家的过分依赖和由人工操作引入的错误,快速提升系统管理员的运维诊断能力。
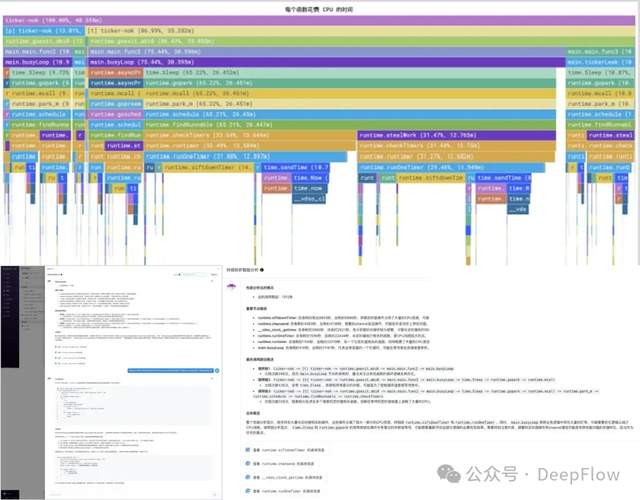
总结
通过部署 DeepFlow 智能体提升了云环境中的智能可观测能力,实现了对业务拓扑的智能分析和持续诊断,快速找到问题根因并提供优化方案,显著提升系统管理员的运维效率和诊断能力。
同时在不修改大模型应用代码、不重启大模型应用进程的情况下,使公司自有通义等大模型,对异构数据进行统一关联分析,实现故障场景的拓扑、追踪、剖析及智能分析,大幅提升数据分析及排障的效率,保障GPU相关业务连续性。
想了解更多可观测性+AI 的实战经验,欢迎报名6月28日的《觉醒!当 AI 获得系统感知力》线下活动~看看腾讯、OpenAIOps社区、中国DevOps社区、金山办公的顶尖实践者的精彩分享! https://mp.weixin.qq.com/s/9VSsV2iMhmTyrUGbkYBc3Q
</div>

