维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道!

<span id="OSC_h1_1"></span> 导读
BaikalDB作为服务百度商业产品的分布式存储系统,支撑了整个广告库海量物料的存储和OLTP事务处理。随着数据不断增长,离线计算时效性和资源需求压力突显,基于同一份数据进行OLAP处理也更为经济便捷,BaikalDB如何在OLTP系统内实现适合大数据分析场景的查询引擎以应对挑战?
01 BaikalDB应对OLAP场景的挑战
BaikalDB是面向百度商业产品系统的需求而设计的分布式存储系统,过去多年把商业内部几十套存储系统全部统一到BaikalDB,解决了异构存储带来的各种问题,支撑了整个广告库的海量物料存储和复杂的业务查询。BaikalDB核心特点包括:
-
兼容mysql协议,支持分布式事务:基于Raft协议实现三副本强一致性,通过两阶段提交协议保障跨节点事务的原子性与持久性。
-
丰富检索能力:不仅支持传统的结构化索引、全文索引等,为解决LLM应用的向量需求,BaikalDB通过内置向量索引方式实现向量数据的存储和检索,一套系统支持结构化检索、全文检索、向量检索等丰富的检索能力,综合满足LLM应用的各种记忆存储和检索需求。
-
高可用,弹性扩展:支持自动扩缩容和数据均衡,支持自动故障恢复和迁移,无单点。当前管理数千业务表与数十万亿行数据,日均处理百亿级请求。

△BaikalDB架构
随着业务发展,离线分析难以满足诉求,实时多维分析需求对BaikalDB大数据处理能力的要求显著提高。BaikalDB的查询引擎主要面向OLTP(联机事务处理)场景设计的,以下双重关键瓶颈使其应对OLAP (联机分析处理)有很大的挑战:
-
计算性能瓶颈:传统火山模型使用行存结构破坏缓存局部性、逐行虚函数调用风暴频繁中断指令流水线、单调用链阻塞多核并行扩展等等弊端,导致大数据分析性能呈超线性劣化。
-
计算资源瓶颈:Baikaldb单节点计算资源有限,面对大规模数据计算,单节点CPU、内存使用容易超限。
BaikalDB从OLTP向HTAP(混合事务/分析处理)架构演进亟需解决当前OLTP查询架构在面向大规模数据的计算性能瓶颈、计算资源瓶颈,并通过如向量化查询引擎、MPP多机并行查询、列式存储等技术手段优化OLAP场景查询性能。
02 BaikalDB OLAP查询引擎的目标
2.1 向量化查询引擎:解决OLTP查询引擎性能瓶颈
2.1.1 火山模型性能瓶颈
设计之初,由于BaikalDB主要面向OLTP场景,故而BaikalDB查询引擎是基于传统的火山模型而实现。
如下图所示,在火山模型里,SQL的每个算子会抽象为一个Operator Node,整个SQL执行计划构建一个Operator Node树,执行方式就是从根节点到叶子节点自上而下不断递归调用next()函数获取一批数据进行计算处理。 由于火山模型简单易用,每个算子独立实现,不用关心其他算子逻辑等优点,使得火山模型非常适合OLTP场景。
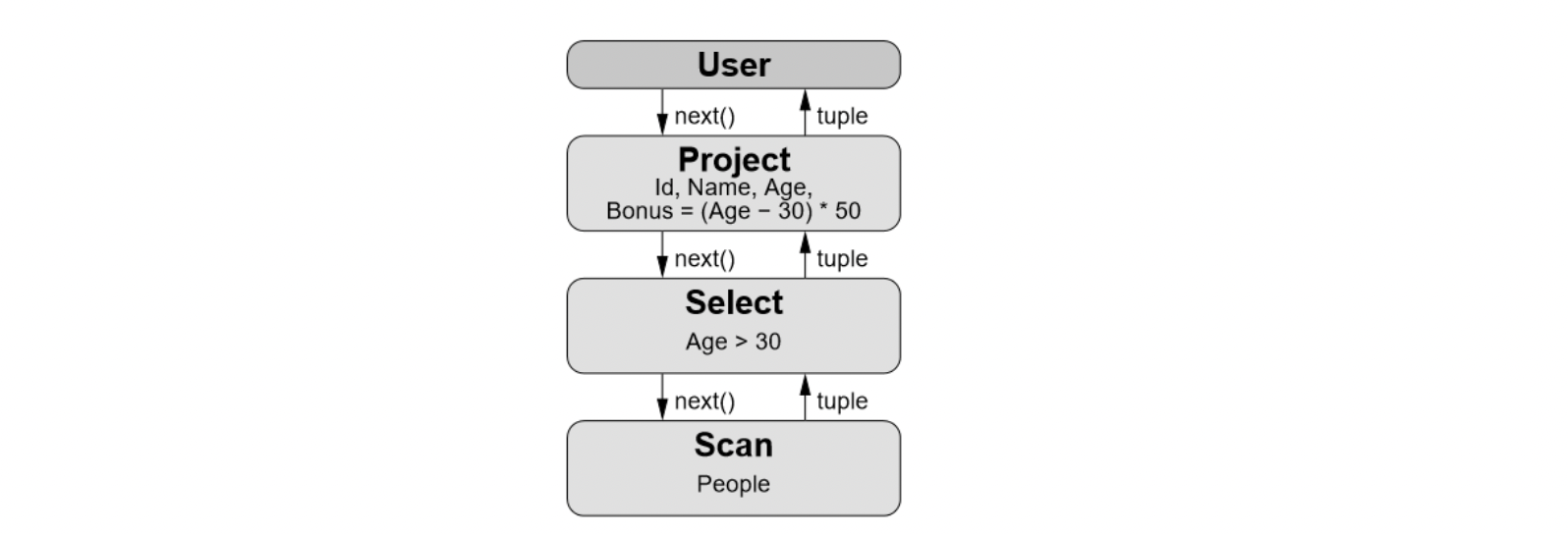
△select id, name, age, (age – 30) * 50 as bonus from peope where age > 30 火山模型执行计划
但当火山模型处理大量数据时有着以下三大弊端,这些弊端是导致火山模型面对大数据量分析场景查询性能差的元凶。
-
行式存储引发的缓存失效问题
-
数据局部性缺失:行式存储(Row-based Storage)将整行数据连续存放,当查询仅需部分列时,系统被迫加载整行冗余数据,容易造成Cache Miss。
-
硬件资源浪费:现代CPU三级缓存容量有限,行存结构导致有效数据密度降低。
-
-
逐行处理机制的性能衰减
-
函数调用过载:火山模型要求每个算子逐行调用 next() 接口,处理百万级数据时产生百万次函数调用。
-
CPU流水线中断:频繁的上下文切换导致CPU分支预测失败率升高。
-
-
执行模型的多核适配缺陷
-
流水线阻塞:Pull-based模型依赖自顶向下的单调用链,无法并行执行相邻算子。
-
资源闲置浪费:现代服务器普遍具备64核以上计算能力,单调用链无法充分利用多核能力。
-


