
<span id="OSC_h2_1"></span> 引言:流批一体,理想与现实的鸿沟
在数据驱动的今天,“实时”二字仿佛拥有魔力,驱使着无数企业投身于流批一体架构的建设浪潮中。我们渴望实时洞察业务变化,实时响应用户需求。以 Apache Flink 为代表的流处理引擎,以其强大的功能和极低的延迟,为我们描绘了一幅美好的实时数据蓝图。
然而,理想通往现实的道路往往布满荆棘。对于许多企业,尤其是IT能力和研发资源并非顶尖的公司而言,构建和维护一套基于 Flink 的流批一体平台,往往意味着一场“甜蜜的烦恼”:我们得到了实时性,却也背上了高昂的复杂度和成本。
有没有一种更简洁、更优雅的方式来实现流批一体?答案是肯定的。随着数据库技术的“文艺复兴”,Cloudberry 数据库中实现的增量物化视图(Incremental Materialized View, IVM)为代表的“库内流处理”技术,正成为一把剃除繁杂、直达问题核心的“奥卡姆剃刀”。本文将深入探讨这一技术,以及它为何可能成为更多企业流批一体实践的主流选择。
传统流批一体的“重”:Flink 的强大与负担
在我们探讨新范式之前,必须正视现有主流方案的挑战。以 Flink 为核心的流批一体架构通常遵循下图中的模式,本次我们主要探讨的是有业务状态变更的场景,这种场景是需要提供源端数据库的事务保证的,必须提供“单一事实来源”;而事件类的场景,如日志、行为数据、IOT数据则可以直接由应用将消息数据推送给Kafka,这种场景并非数据库的主战场,故不在本次讨论范围内。
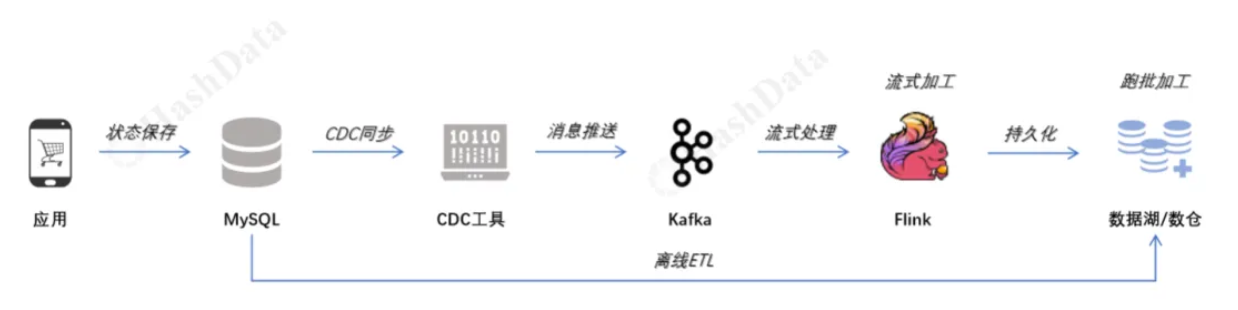
这个架构功能强大,但其“重量”也体现在多个方面:
-
架构的“缝合感”与高昂运维:整个数据链路需要“缝合”多个独立的分布式系统:应用、MySQL、CDC工具、Kafka、Flink,以及最终的数据湖/数仓。每一个组件都需要专业的知识进行部署、监控和维护,任何一个环节的故障都可能导致整个链路的中断。
-
开发的“双重负担”:在经典的 Lambda 架构中,为了保证结果的最终一致性,团队往往需要维护两套异构的代码:一套 Flink 的流处理逻辑,和一套 Spark/Hive 的批处理逻辑。相同的业务口径,双份的开发和测试工作,这不仅成本高昂,也极易导致逻辑不一致。
-
技术的“陡峭曲线”:精通 Flink 绝非易事。其背后的状态管理、时间语义(事件时间/处理时间)、水印(Watermark)、窗口机制以及性能调优,都需要一个高度专业化的团队来驾驭,这对很多企业来说是一种奢侈。
化繁为简:增量物化视图如何重塑流批一体?
面对传统方案的复杂性,Cloudberry 等现代数据平台提出了一个新的思路: 为什么不让最擅长管理数据的数据库,自己来处理流式计算呢? 这就是“库内流批一体”的核心思想,其实现如下图所示。

增量物化视图(IVM)是实现这一范式的核心武器。它本质上是一个“活”的、能自动更新的查询结果缓存。
-
“批”处理:当你首次执行 CREATE INCREMENTAL MATERIALIZED VIEW 时,Cloudberry 数据库会对所有存量历史数据进行一次全量计算,生成视图的初始状态。这,就是批处理。
-
“流”处理:创建完成后,IVM 引擎开始工作。任何对源表(通常是实时数据流入的 Heap 表)的 INSERT, UPDATE, DELETE 操作,都会被 IVM 捕捉到。引擎只会计算这些“增量”数据对结果的影响,并以准实时的方式(延迟在亚秒到秒级)更新物化视图。这,就是流式处理。
这一切带来的改变是立竿见影: 原本复杂的数据流,需要定义Kafka的数据结构和难以复用的Flink的数据结构,以及各种复杂的Flink SQL 代码(包括定义数据源、窗口、聚合逻辑、维表关联、结果表等)才能完成的任务,如:
//Kafka数据结构
<span>{</span>
<span> "sales_id": 8435,</span>
<span> "event_type": "+I",</span>
<span> "event_time": "2025-06-27 07:53:21Z",</span>
<span> "ticket_number": 8619628,</span>
<span> "item_sk": 6687,</span>
<span> "customer_sk": 69684,</span>
<span> "store_sk": 238,</span>
<span> "quantity": 6,</span>
<span> "sales_price": 179.85,</span>
<span> "ext_sales_price": 1079.1,</span>
<span> "net_profit": 672,</span>
<span> "event_source": "CDC-TO-KAFKA-FIXED"</span>
<span>}</span>
CDC同步给Kafka的数据结构必须由原本的SQL形态转换成Json形态,但这又无法避免,因为Flink在处理流式数据之前需要这些数据是能持久化的,避免数据在传输中丢失,从而影响数据处理的正确性,并且也便于出现问题后的重新执行。
下面的代码只是呈现Flink在做流式计算的示例,而在实际应用中CDC -> Kafka,和Kafka ->Flink的过程中还要做大量的代码和配置。
//创建TPC-DS店铺业绩聚合结果输出表(输出到控制台)
<span>CREATE TABLE store_daily_performance (</span>
<span> window_start TIMESTAMP(3), -- 窗口开始时间</span>
<span> window_end TIMESTAMP(3), -- 窗口结束时间</span>
<span> s_store_sk INT, -- TPC-DS店铺代理键</span>
<span> s_store_name STRING, -- TPC-DS店铺名称</span>
<span> s_state STRING, -- TPC-DS州/省份</span>
<span> s_market_manager STRING, -- TPC-DS市场经理</span>
<span> sale_date STRING, -- 销售日期</span>
<span> -- TPC-DS核心业务指标</span>
<span> total_sales_amount DECIMAL(10,2), -- 总销售额</span>
<span> total_net_profit DECIMAL(10,2), -- 总净利润</span>
<span> total_items_sold BIGINT, -- 总商品数量</span>
<span> transaction_count BIGINT, -- 交易笔数</span>
<span> avg_sales_price DECIMAL(7,2), -- 平均销售价格</span>
<span> -- 统计时间</span>
<span> process_time TIMESTAMP_LTZ(3) -- 处理时间</span>
<span>) WITH (</span>
<span> 'connector'='print',</span>
<span> 'print-identifier'='TPCDS-STORE-PERFORMANCE'</span>
<span>);</span>
//核心聚合查询:实现类似增量聚合效果
<span>INSERT INTO store_daily_performance</span>
<span>SELECT</span>
<span> -- 时间窗口信息</span>
<span> window_start,</span>
<span> window_end,</span>
<span> -- TPC-DS维度信息</span>
<span> s.ss_store_sk,</span>
<span> COALESCE(sd.s_store_name, CONCAT('Store #', CAST(s.ss_store_sk AS STRING))) as s_store_name,</span>
<span> COALESCE(sd.s_state, 'Unknown') as s_state,</span>
<span> COALESCE(sd.s_market_manager, 'Unknown Manager') as s_market_manager,</span>
<span> DATE_FORMAT(window_start, 'yyyy-MM-dd') as sale_date,</span>
<span> -- TPC-DS核心业务指标聚合</span>
<span> SUM(CASEWHEN s.event_type="+I" THEN s.ss_ext_sales_price </span>
<span> WHEN s.event_type="-D" THEN -s.ss_ext_sales_price </span>
<span> ELSE 0 END) as total_sales_amount,</span>
<span> SUM(CASEWHEN s.event_type="+I" THEN s.ss_net_profit </span>
<span> WHEN s.event_type="-D" THEN- s.ss_net_profit </span>
<span> ELSE 0 END) as total_net_profit,</span>
<span> SUM(CASEWHEN s.event_type="+I" THEN s.ss_quantity </span>
<span> WHEN s.event_type="-D" THEN -s.ss_quantity </span>
<span> ELSE 0 END) as total_items_sold,</span>
<span> COUNT(DISTINCT s.ss_ticket_number) as transaction_count,</span>
<span> AVG(s.ss_sales_price) as avg_sales_price,</span>
<span> -- 处理时间戳</span>
<span> LOCALTIMESTAMP as process_time</span>
<span>FROMTABLE(</span>
<span> TUMBLE(TABLE sales_events_source, DESCRIPTOR(event_time), INTERVAL '1'MINUTE)</span>
<span>) s</span>
<span>LEFT JOIN store_dim sd ON s.ss_store_sk = sd.s_store_sk</span>
<span>WHERE s.event_type IN ('+I', '-D', 'U') -- 处理插入、删除、更新事件</span>
<span>GROUP BY</span>
<span> window_start, </span>
<span> window_end,</span>
<span> s.ss_store_sk,</span>
<span> sd.s_store_name,</span>
<span> sd.s_state,</span>
<span> sd.s_market_manager;</span>
而如果使用Cloudberry IVM,可能只需要一句CREATE INCREMENTAL MATERIALIZED VIEW 即可。
<span>CREATE INCREMENTAL MATERIALIZED VIEW tpcds.store_daily_performance_enriched_ivm</span>
<span>AS</span>
<span>SELECT</span>
<span> -- 维度信息 (从维度表中关联得到)</span>
<span> ss.ss_store_sk store,</span>
<span> s.s_store_name store_name,</span>
<span> s.s_state state,</span>
<span> s.s_market_manager manager,</span>
<span> d.d_date sold_date,</span>
<span> -- 核心业务指标 (与之前相同)</span>
<span> SUM(ss.ss_net_paid_inc_tax) AS total_sales_amount,</span>
<span> SUM(ss.ss_net_profit) AS total_net_profit,</span>
<span> SUM(ss.ss_quantity) AS total_items_sold,</span>
<span> COUNT(ss.ss_ticket_number) AS transaction_count</span>
<span>FROM</span>
<span> -- 核心事实表与维度表的 JOIN</span>
<span> tpcds.store_sales_heap ss</span>
<span>JOIN</span>
<span> tpcds.date_dim d ON ss.ss_sold_date_sk = d.d_date_sk</span>
<span>JOIN</span>
<span> tpcds.store s ON ss.ss_store_sk = s.s_store_sk</span>
<span>GROUP BY</span>
<span> -- 所有非聚合的维度列都需要出现在 GROUP BY 中</span>
<span> ss.ss_store_sk,</span>
<span> s.s_store_name,</span>
<span> s.s_state,</span>
<span> s.s_market_manager,</span>
<span> d.d_date</span>
<span>DISTRIBUTED BY (ss_store_sk);</span>
状态管理、数据一致性、计算触发等所有复杂工作,都由数据库内核透明地完成了,自此告别了中间大量的数据流作业的调度,大幅减少了开发运维成本。
“黄金搭档”:IVM 与动态表(Dynamic Table)的场景辨析
在 Cloudberry 的工具箱中,除了 IVM,还有另一个强大的武器——动态表。两者虽都是物化视图的变体,但应用场景截然不同,是一对完美的“黄金搭档”。

何时选择增量物化视图 (Incremental Materialized View)?
选择 IVM 的核心决策依据是: 您对数据的“新鲜度”和“低延迟”有极致的要求。
场景1:实时监控与分析仪表盘 (Real-time Dashboards)
-
描述:想象一下“双十一”作战指挥室里的大屏,需要以秒级刷新展示全国各个区域的实时GMV、订单量、支付成功率。
-
为何适合IVM: 每一个新的订单 (
<span><span>INSERT</span></span>到<span><span>store_sales</span></span>表)都需要被立刻反映到大屏的聚合指标上。IVM 事件驱动的特性完美匹配这个需求,它可以紧随源表事务,提供秒级的视图更新,确保决策者看到的是最新的战况。动态表5分钟一次的刷新在这里会显得“太慢了”。
场景2:在线分析与交易一体化 (HTAP / OLAP on OLTP)
-
描述:在一个繁忙的交易系统中(例如我们的
<span><span>MySQL + CDC</span></span>场景),业务方希望在不影响交易性能的前提下,对最新的业务数据进行复杂的分析查询。 -
为何适合IVM: IVM 将昂贵的聚合和关联计算与前端查询进行解耦。它在后台悄悄地、增量地处理着每一笔交易变更,将结果预先算好。分析师的查询可以直接命中这个预计算好的 IVM,避免了直接用复杂的分析查询去冲击宝贵的在线交易数据库。
场景3:需要物化复杂中间结果的ETL/数据处理链路
-
描述: 在一个数据处理流程中,需要将多张频繁变更的表进行关联,并将这个中间结果作为下游多个任务的输入。
-
为何适合IVM: IVM 可以将这个复杂的中间结果物化下来,并保持准实时更新。下游的所有任务都可以直接从这个稳定、高效的 IVM 中读取数据,而无需重复进行昂贵的关联操作,极大地提升了整个数据处理链路的效率。
何时选择动态表 (Dynamic Table)?
选择动态表的核心决策依据是:业务可以容忍分钟级或更长的数据延迟,且主要目标是加速复杂查询或避免对源系统造成持续压力。
场景1:加速数据湖查询 (Lakehouse Acceleration) – 它的“主场”
-
描述:这是动态表文档中明确提出的核心场景。您的公司将海量的(TB/PB级)用户行为日志以 Parquet 格式存储在 S3 数据湖中。您在 CloudberryDB 中创建了一个指向这批数据的外部表。直接对这个外部表进行聚合查询非常缓慢,因为每次都需要通过网络从 S3 拉取大量数据。
-
为何适合DT: 您可以创建一个动态表,
<span><span>SCHEDULE '*/30 * * * *'</span></span>(每30分钟)对这个外部表进行一次聚合计算,并将结果物化到 Cloudberry 的本地存储中。分析师们现在可以直接查询这个本地的动态表,查询速度将从几十分钟缩短到几秒钟,体验与查询内部表无异。
场景2:常规商业智能与报表 (Periodic BI & Reporting)
-
描述:业务方需要一份“每日销售总结报表”、“每周用户活跃度报告”或“每月财务对账报表”。
-
为何适合DT: 这些报表对数据的要求不是“实时”,而是“T+1”或“周/月度”的准确性。使用动态表,配置一个每天凌晨
<span><span>SCHEDULE '0 1 * * *'</span></span>运行的刷新任务,自动生成前一天的报表数据。这相当于一个内置的、无需维护的、轻量级 ETL 作业,非常高效且优雅。
场景3:保护高并发写入的源系统
-
描述:我们之前讨论过,IVM 会给源表的
<span><span>INSERT/UPDATE</span></span>带来额外的事务开销。现在假设您的源表是一个写入并发极高的日志表,任何一点写入延迟的增加都是不可接受的。 -
为何适合DT: 动态表完美地解决了这个问题。它的刷新任务与源表的写入事务是完全解耦的。您的日志表可以毫无压力地进行高频写入。动态表只会在调度点(例如每5分钟)对该表发起一次集中的读取操作,将计算负载与写入负载在时间上完全错开。
结论:互补的“黄金搭档”
通过以 上分析,我们可以清晰地看到:
-
增量物化视图 (IVM) 和 动态表 (DT) 并非互相替代的竞争关系,而是一对功能互补的“黄金搭档”。
-
IVM 是您工具箱里的“手术刀”,用于对需要低延迟、高新鲜度的内部数据进行精准、实时的分析。
-
动态表 (DT) 则是您工具箱里的“搬运车”和“预制工厂”,用于将外部的、或计算昂贵的数据,以周期性的方式高效地“搬运”和“预制”到数据库内部,供您随时享用。
直面现实:Cloudberry 增量物化视图的性能与当前限制
任何技术都不是银弹。透明地看待其成本与限制,是做出正确架构选择的前提。
性能开销
:IVM 的即时维护特性,会给源表的
<span><span>INSERT/UPDATE/DELETE</span></span>
操作带来额外的开销。我们的测试显示,这种开销与基表上建立的IVM数量基本成正比。对于写性能极其敏感的场景,需要审慎评估或采用动态表等其他模式。
关键限制 :当前版本的 Cloudberry 增量物化视图还存在一些功能限制,例如:
-
不支持
<span><span>MIN</span></span>、<span><span>MAX</span></span>聚合函数。 -
不支持
<span><span>CTE</span></span>、 窗口函数、<span><span>LEFT/OUTER JOIN</span></span>等复杂查询和连接。 -
不支持分区表。
我们期待并相信,在开源社区的共同努力下,这些 限制将在未来的版本中得到逐步完善。
结语:拥抱简单,回归本质
对于全球顶尖的互联网公司而言,用一个庞大的团队去驾驭 Flink 这样的“重器”,追求极致的性能和灵活性是值得的。但对于更广泛的企业来说,其绝大多数的实时分析需求,并不需要如此复杂的“屠龙之技”。
Apache Cloudberry 数据库提供的增量物化视图,正是这样一把返璞归真的“奥卡姆剃刀”。它让我们回归数据处理的本质,用最简洁、最通用的语言(SQL),在一个统一、自洽的系统内,解决了流批一体的核心难题——数据一致性、开发复杂性和高昂成本。这或许正是能让实时数据能力在更多企业中真正普及和落地的、最务实的一条路径。
Github Demo库代码(用于理解并比对IVM与Flink流式加工的区别):https://github.com/darkcatc/Stream-Batch-IVM
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


