
<span id="OSC_h1_1"></span> 一、项目背景
在社区场景中,我们积累了丰富的用户互动数据。这些历史互动信息对CTR/CVR预估建模具有重要参考价值,用户的每次互动都反映了其特定维度的偏好特征。当前,已在多个业务实践中验证,基于用户历史互动特征进行未来行为预测是有效的。用户互动序列越长,包含的偏好特征就越丰富,但同时也带来了更大的技术挑战。
目前社区搜索领域已经在序列建模方向取得了一些应用成果,显著提升了搜索效率,但在该方向上仍有优化空间,主要体现在:
算法精排模型现状:长周期的用户互动特征尚未被充分利用,现有模型仅使用了基础标识信息,泛化能力有待提升。我们计划引入SIM方案来增强个性化序列建模能力,推动搜索效率提升。
迭代效率优化:当前互动特征优化依赖于实时数据采集链路,新增特征需要长时间数据积累(2个月以上)才能验证效果。我们计划建设用户特征离线回溯服务,降低算法优化对实时数据的依赖,加快项目迭代速度,提高实验效率。
离线回溯主要解决迭代效率问题,本文重点探讨在社区搜索场景下开发离线回溯,并做离线一致性验证过程中发现的一些问题,针对这些问题做了哪些优化措施及思考。
二、架构设计
全局架构
序列产出流程链路
※ 在线流程链路
在线链路通过实时数仓提供全量表和实时流两种数据源,在特征平台下构建1w长度的实时用户画像,召回阶段SP,将画像传给SIM引擎,在引擎中完成对用户序列hard/soft search等异步加工,最终传给Nuroe,完成在线序列dump落表。
※ 离线流程链路
离线链路通过仿真在线的处理逻辑,利用请求pv表和离线数仓提供的10w原始序列,模拟在线序列10w->1w->100的过程,最终产出离线回溯序列。
最终通过在线/离线全链路数据的一致性验证,确认全流程数据无diff(或diff可解释),序列流程可靠性达标,可交付算法团队用于模型训练。
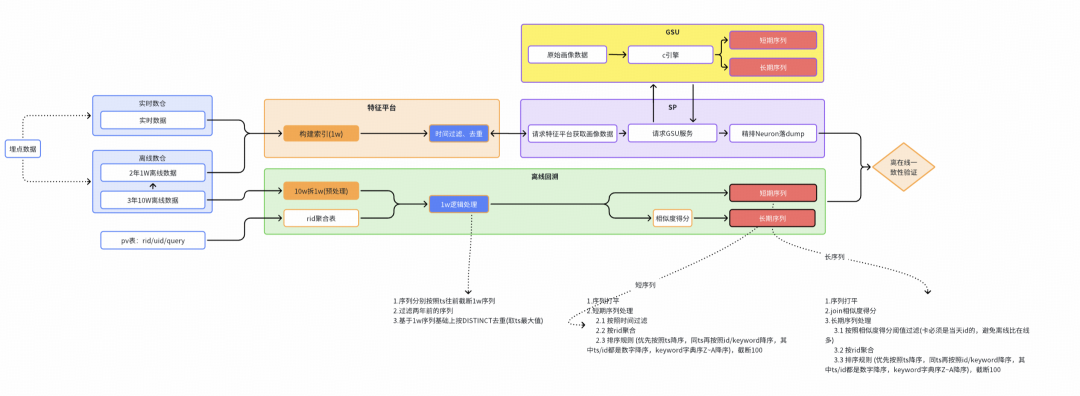
序列产出全局架构
在线架构
在线侧抽象GSU模块支持社区搜索和增长搜索等多场景复用。该模块在QP(Query Processing)阶段后,通过外调基于DSearch构建的SIM引擎进行用户序列处理。SIM引擎内完成hard/soft search等用户序列加工,在精排阶段前获取topk序列特征及对应sideinfo,并将其透传给精排模块,最终实现用户序列的落表存储。

在线通用GSU模块
离线链路
数据产出三阶段
※ 原始序列预处理阶段
通过收集一个用户,按照 [月初ts+1w, 月末ts] 将序列进行预处理。
※ pv表合并序列表阶段
按照user_id将画像和pv表合并,将每个request_id的数据按照request_time过滤处理。
※ 用户序列加工阶段
完成hard/soft search等用户序列加工逻辑处理,包括对长期序列按照相似度过滤,对短期序列按照时间过滤等。
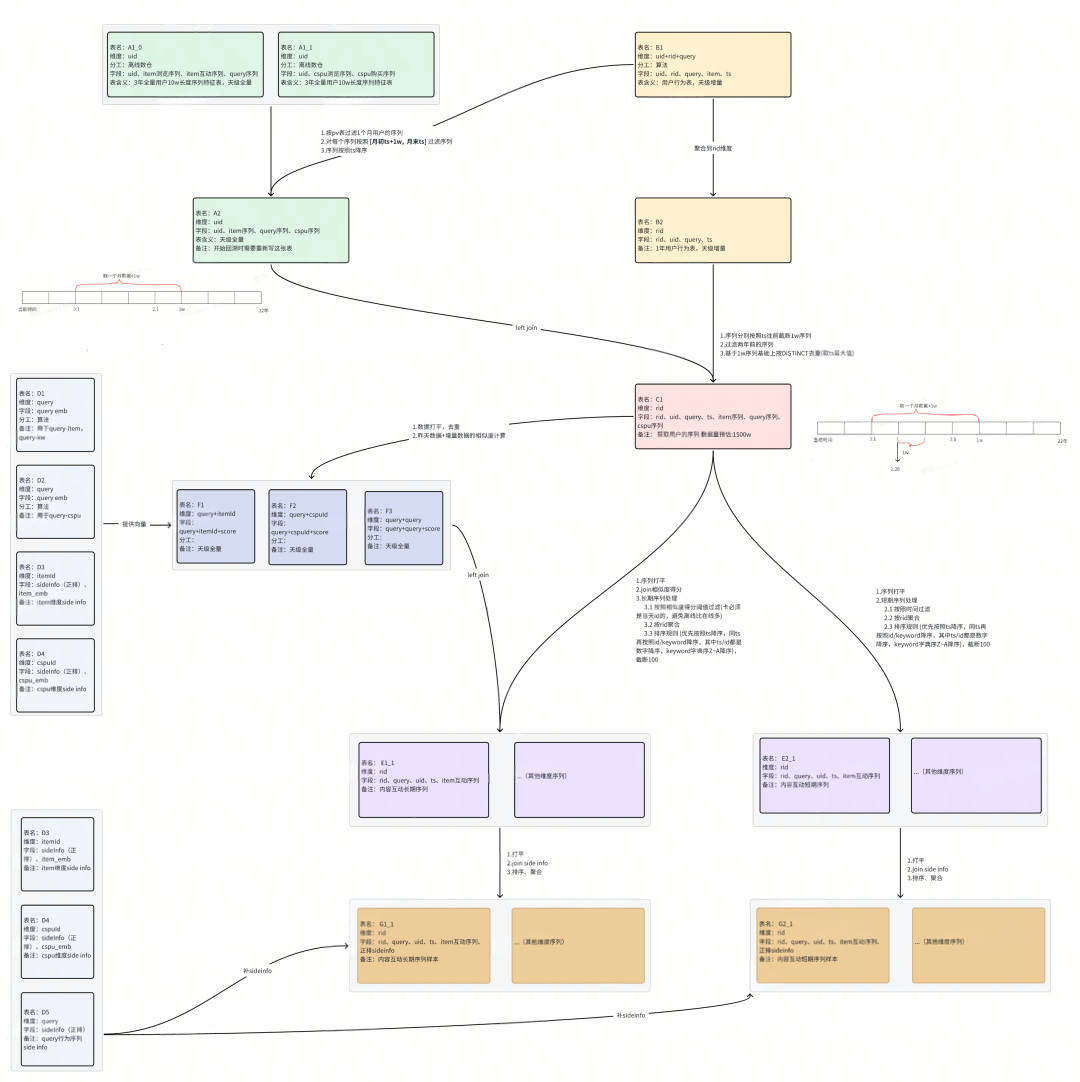
离线回溯链路图
三、问题与挑战
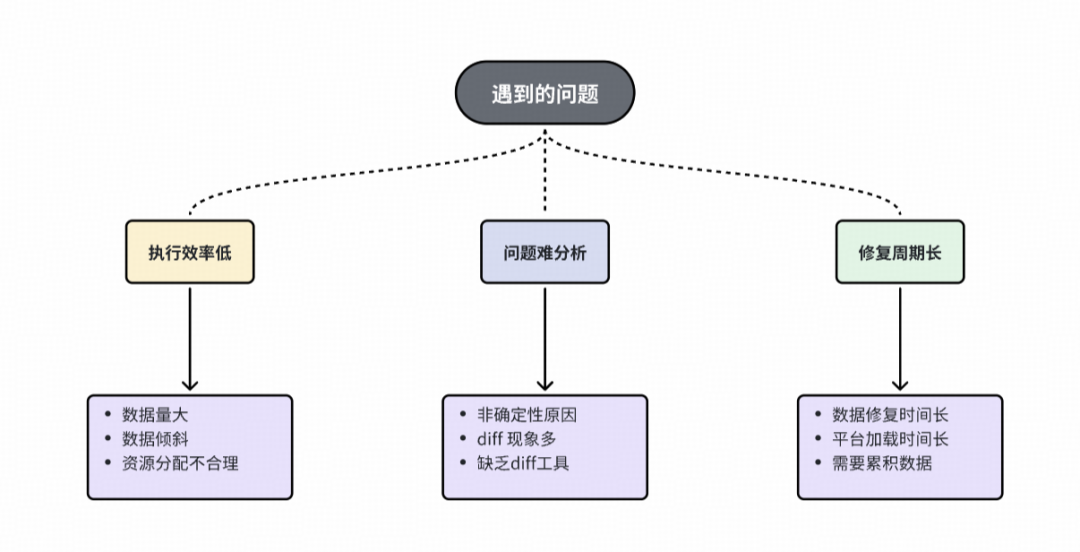
在离线回溯开发阶段,主要面临以下挑战。
挑战
※ 任务执行问题
任务频繁失败或执行效率低下,数据规模达单表数TB级别,且序列分布不均,部分长尾用户序列过长导致严重数据倾斜;
※ 一致性校验阶段问题
异常类型复杂多样,累计发现25+种异常原因,导致数据diff形态复杂,一致性原因分析困难。修复链路冗长,涉及问题修复、在线索引重建、数据累计和离线数据回补,单次修复周期约需一周。
四、从踩雷到填坑的实战记录
离线任务运行耗时长的问题
问题说明
初步方案运行时存在两大问题:
1.任务处理延迟显著,单个任务运行3-8小时。
2.任务处理无法运行成功频繁OOM。
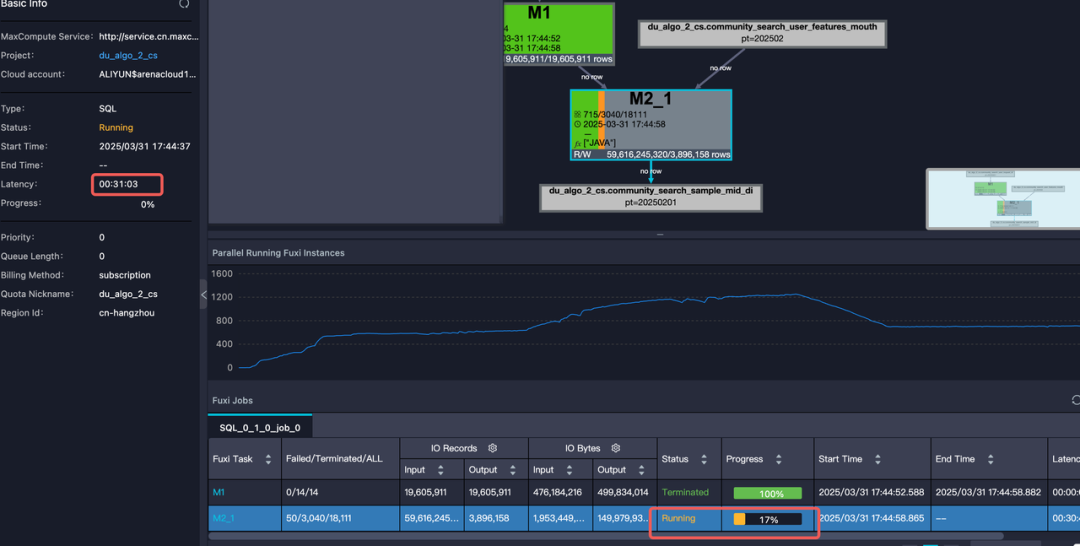
任务执行慢
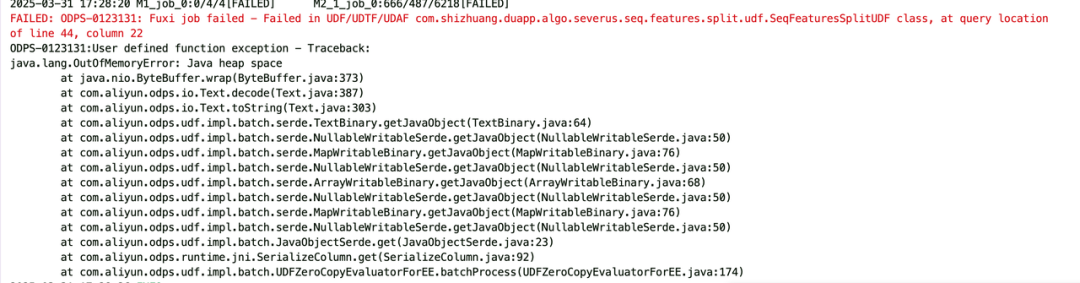
任务频繁OOM
解决方案
※ 方案优化
任务执行慢主要是有长尾用户打满10w长序列,出现数据倾斜问题甚至oom。
通过对链路优化,先将原始10w长序列做预处理,由于回溯一般按照一个月跑数据,可以利用pv表先统计有哪些有效用户,对有效用户按照 【月初ts+1w, 月末ts】截取原始序列,获取相对较短的预处理队列。
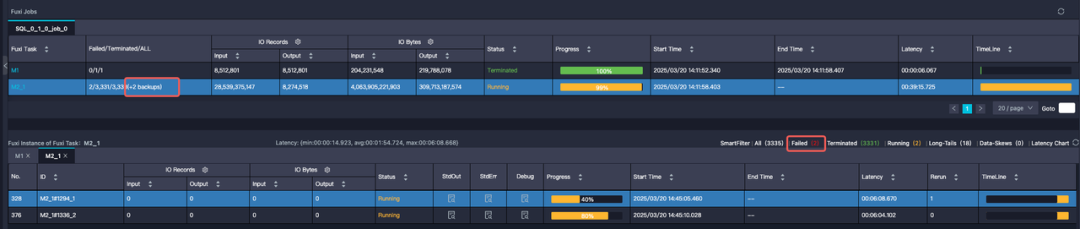
任务倾斜
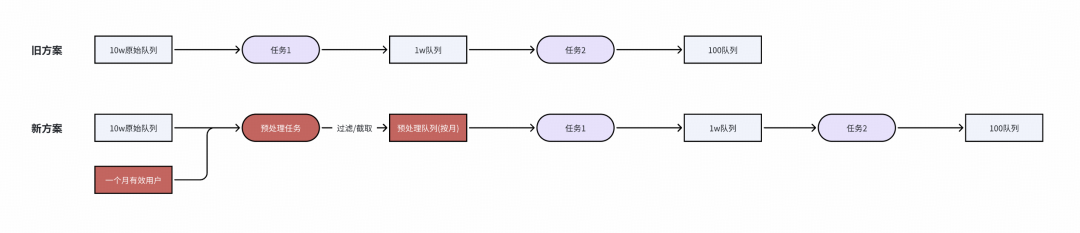
原始序列预处理
※ ODPS任务性能调优
a. 按照 CPU : MEM = 1 : 4 调整计算和存储的比例,可以最大化利用资源,因为我们申请的资源池都是按照这个固定比例来的。

资源没有最大化使用
b. 在固化计算/存储比例参数后,可以通过xxx.split.size 和 xxx.num 共同调优。xxx.split.size可以实现输入分片大小,减少oom机会。xxx.num可以实现扩大并发数,加快任务的执行(xxx代表mapper、reducer、joiner几个阶段)。

分批次完成阶段处理
c. 减少自定义UDF使用。在离线任务中有部分逻辑比较复杂,可能需要数据平铺、聚合、再内置函数等。最好的使用原则是内置函数>“数据平铺+内置函数”>自定义UDF。由于自定义UDF运行在Java沙箱环境中,需通过多层抽象层 (序列化/反序列化、类型转换),测试发现大数据量处理过程性能相对最差。
一致性验证归因难的问题
问题说明
在线/离线全链路数据的一致性验证过程中,由于按照天级全量dump序列,需要验证15个序列,每个序列diff量在10w~50w不等,这种多序列大规模的diff问题人工核验效率太慢。
解决方案
※ 整体diff率分析
通过统计全序列diff率并聚类分析高diff样本,定位共性根因,实现以点带面的高效问题修复。
※ diff归因工具
通过建立数据diff的归因分类体系(如排序不稳定、特征穿越等),并标注标准化归因码,实现对diff问题的快速定位与根因分析,显著提升排查效率。
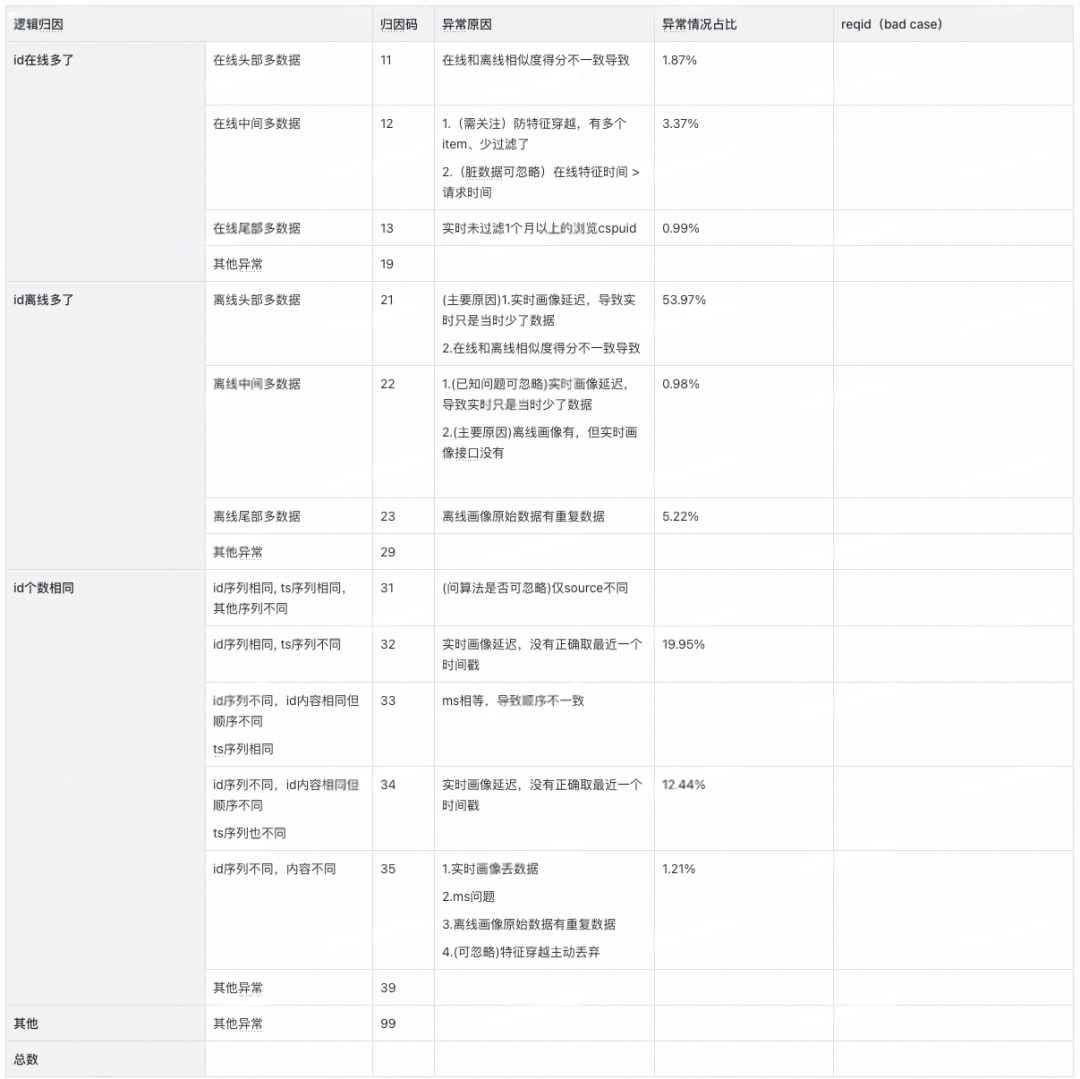
归因码分类
※ 重复度统计工具
由于在线受当时环境的影响,离线回溯无法100%复现原始序列,一致性差异在所难免。我们通过聚焦主要特征并统计其重复度,结合「diff率+重复度」双维度评估方案,为算法决策提供量化依据,有效减少无效迭代。
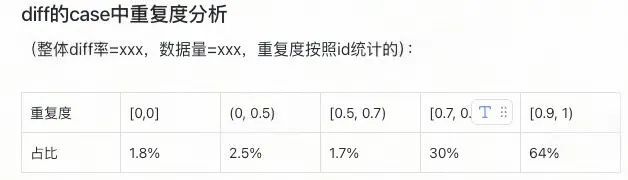
重复度统计
现状梳理不足的问题
问题说明
由于前期对业务场景理解不足(如用户行为模式、异常数据、测试账户等),部分潜在问题未在开发阶段充分识别,直至数据一致性验证时才集中暴露,导致需紧急调整数据处理逻辑。由于单次全链路修复需3-5天,进而对项目进度造成一定延迟。
问题case1:滑动图片:离线回溯数据分析时发现序列中大量重复且占比很高,后确定为滑动图片行为
解决方案:对滑动图片操作连续多次修改为只记录第一次
问题case2:合并下单:测试购买序列有id重复,实时数仓反馈购买有合并下单的情况,ts会相同
解决方案:为了保持离线回刷数据稳定性,将序列按照ts/id双维度排序
问题case3:异常数据:有行为时间戳超过当前时间的异常数据
解决方案:数仓对异常数据丢弃
问题case4:测试账户:数据不规范导致数据diff
解决方案:测试账户数据忽略
问题case5:query问题:取归一化后还是原始的query、空字符串问题
解决方案:query为空过滤修复
问题case6:数据穿越问题:画像原始数据request_time取neuron时间导致
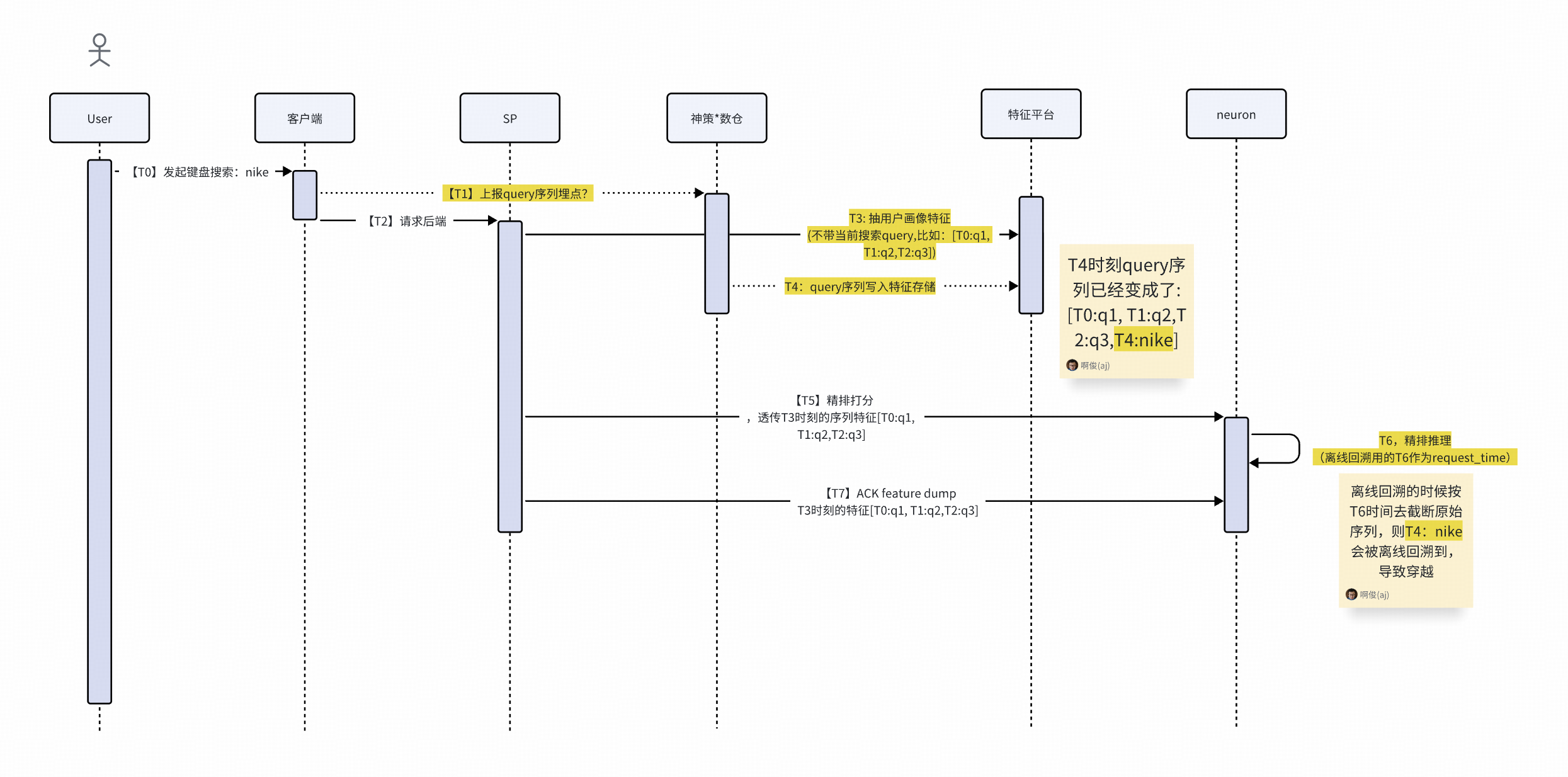
解决方案:在线修改request_time获取时间,离线回溯前置3s
修复周期长的问题
问题说明
数据问题的完整修复流程包含三个阶段,全流程通常需要5-7个工作日完成。

※ Diff归因阶段(1-3日)
-
需要定位数据差异的根本原因,区分是数据异常、处理逻辑错误还是业务规则变更导致
-
涉及多团队协作排查(数据/算法/工程)
-
复杂问题可能需要多次验证
※ 问题修复阶段(1-3日)
-
根据归因结果修改代码逻辑或数据处理流程
-
可能涉及历史数据修正
※ 数据迭代阶段(2-3日)
-
在线画像引擎部署新数据
-
累计在线数据
-
离线画像回补数据
解决方案
受限于初期人力投入,我们在当前方案基础上通过多轮版本迭代逐步完成数据一致性验证。后续将通过工具升级(数据边界划分+自动化校验框架)和数据采样策略,实现验证到修复的阶跃式提升。
※ 数据边界划分
现行方案离线链路都是算法工程来维护,排查链路太长,需要数据源有稳定的保障机制。后续将划分数据边界,各团队维护并保障数据模块在离线的一致性。

数据边界划分
※ 全链路采样方案减少验证时间
离在线一致性验证方面耗时较长,主要在于数据量太大,在数仓构建、特征平台构建、累计数据等流程消耗大量的时间,如果全链路先针对少量用户走通全链路,能快速验证流程可行性。
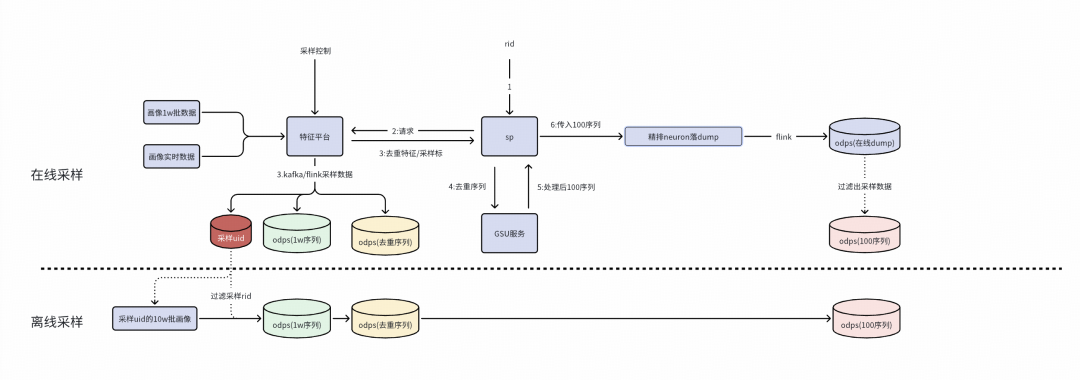
采样方案
平台基建的问题
问题说明
首次构建序列建模体系,由于缺乏标准化基础设施,被迫采用烟囱式开发模式,导致多链路验证复杂且问题频发。
平台待建能力
-
特征平台排序功能不足,只支持单一字段排序,不支持多字段联合排序,导致排序结果不稳定。
-
特征平台过滤功能限制,仅支持毫秒级时间戳过滤。
-
索引构建效率低,个性化行为序列表数据量过大(3TB),导致索引构建压力大,初始构建耗时约28小时。升级至FS3集群后,构建时间降至12小时左右,最短至7小时,但仍未达理想效率。
五、展望与总结
后续我们将深入研究行业内的优秀解决方案,并结合我们的业务特性进行有针对性的优化。
例如,我们会尝试实施离在线数据与逻辑一致性方案,这种方案包括以下几个特点:
-
数据一致性:离线与在线共用同一套原始画像,能够解决数据源不一致导致的差异问题。
-
逻辑一致性:离线与在线都调用GSU服务,实现统一的序列逻辑处理,避免逻辑差异。
-
技术架构复杂性:新方案带来了新的技术挑战,比如在线处理10万序列可能引发的I/O问题、离在线的sim引擎采用存算一体和存算分离架构。
综上,没有绝对完美的技术方案,最终都是在成本、性能和效率多方面权衡后的相对最优解。
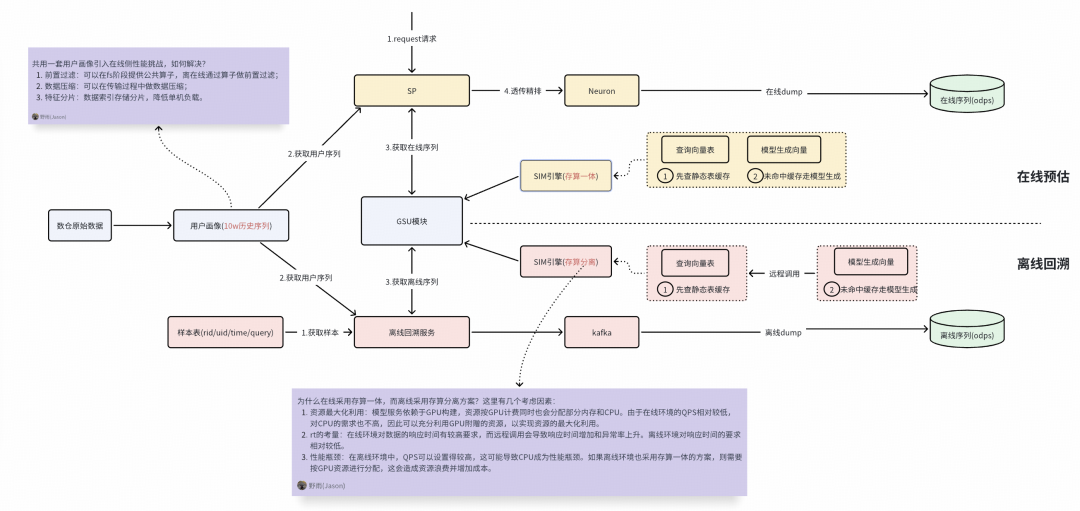
离在线数据与逻辑一致性方案
本次特征回溯虽面临性能与数据对齐等挑战,但团队通过攻坚积累了经验,为特征平台后续特征回溯工具化打下基础,也期待能为后续算法模型迭代带来质的飞跃。
往期回顾
1.从 “卡顿” 到 “秒开”:外投首屏性能优化的 6 个实战锦囊|得物技术
2.从Rust模块化探索到DLB 2.0实践|得物技术
3.eBPF 助力 NAS 分钟级别 Pod 实例溯源|得物技术
4.正品库拍照PWA应用的实现与性能优化|得物技术
5.汇金资损防控体系建设及实践 | 得物技术
文 / 野雨
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


