
<span id="OSC_h2_1"></span> 一,前言
volatile 作为 Java 的基础关键字,一直是个熟悉又神秘的存在。我们在日常做并发编程的过程中经常用到,我们知道在什么场景下需要用到,但却始终不清楚底层究竟做了什么。互联网上搜出来的大多数博客都在解释 volatile 关键字是为了解决指令重排序、内存可见性问题,或是什么内存屏障、缓存一致性协议一类“形而上的词汇”。而究竟什么是指令重排序,为什么要重新排序,什么是可见性问题,底层原理是什么,volatile 又是如何解决的却鲜有提及。引得 Java 开发者们如雾里看花,线上线下充满了疑惑的空气。
本文将浅浅探究一下这一切的底层原理,一起来学习“没有用”的知识,各位看官看懂了可以出去和面试官对线。
二,指令重排序
在了解指令重排序问题之前,我们先来看一个由指令重排序造成并发问题的例子:
static int x = 0, y = 0;
happens-before 八条原则
-
程序次序规则:在一个线程内,按照控制流顺序,书写在前面的操作先行发生于书写在后面的操作。
-
管程锁定规则:一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
-
volatile 变量规则:对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
-
线程启动规则:Thread 对象 start()方法先行发生于此线程的每一个动作。
-
线程终止规则:线程 A 等待线程 B 完成,在线程 A 中调用线程 B 的 join()方法实现),当线程 B 完成后(线程 A 调用线程 B 的 join()方法返回),则线程 A 能够访问到线程 B 对共享变量的操作。
-
线程中断规则:对线程 interrupt() 方法的调用先行,发生于被中断线程的代码,检测到中断事件的发生,可以通过 Thread.interrupted()方法检测到是否有中断发生。
-
对象终结规则:一个对象的初始化完成(构造函数结束)先行发生于它的 finalize()方法的开始。
-
传递性:如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那就可以得出操作 A 先行发生于操作 C 的结论。
hanpens-beofre 是 JVM 对开发者的保证,即不管 JVM 如何优化(JIT 编译),都会保证上述原则一定成立。而对于开发者来说,只要了解上述原则,无需硬件交互的复杂性,也能够写出可预测的代码,从而保证线程安全。
从 hanpens-beofre 中 程序次序规则 和 线程终止规则 可得,上述代码最终运行结果的可能性会有以下几种:

可以明显看出,理论上不会存在 x =0 && y = 0 的运行结果,然而实际上程序在执行了一段时间后,最终的确产生了 x = 0 && y = 0 的结果!
这就引出了 volatile 解决的第一个问题:避免指令重排序。指令重排序在编译器和 CPU 层面(乱序执行)都会发生。
CPU 的乱序执行
我们知道,CPU 运算的本质就是不断获取下一条指令然后执行,编译器给它什么指令它就执行什么,何来的乱序执行呢?
这还要从计算机的诞生之初讲起。
内存拖后腿
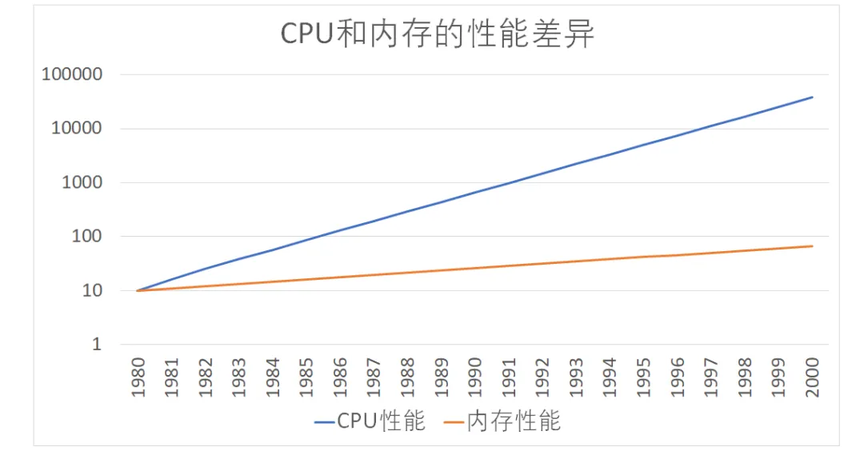
计算机诞生之初,CPU 和内存之间的速度差异并不明显,一切相安无事。随着科学的进步,CPU 的运算速度越来快,根据摩尔定律计算,相当于 CPU 的性能每年增长 60%,相比之下,内存性能的增长却相对缓慢,每年约为 7%。到今天,CPU 运算和内存访问的速度产生了巨大鸿沟,已经达到了 120 倍之多。这时如果 CPU 还以传统计算机架构,数据从内存中读取的话,将会严重拖慢 CPU 的运行速度。
※ 局部性原理
在程序运行过程中,芯片工程师总结了两条存在局部性原理:时间局部性、空间局部性。
-
时间局部性: 由于在代码中循环操作的普遍存在,因此当某部分数据被访问时,不久后该数据很可能会再次被访问,基于此原理诞生了 CPU 的高速缓存。
-
空间局部性: 由于代码是顺序执行的,因此当某一份数据被访问时,后续的数据也将很快被访问,基于此原理诞生了缓存行。
※ CPU 内的高速缓存
为了弥补 CPU 运行速度与内存访问速度之间的巨大差异,提升 CPU 执行效率,CPU 在内部封装了高速缓存。
高速缓存是一种静态随机访问存储器(SRAM),相对于使用电容存储的内存(DRAM)来说,速度快得多,访问速度在纳秒级别,终于能勉强不再拖 CPU 后腿了。
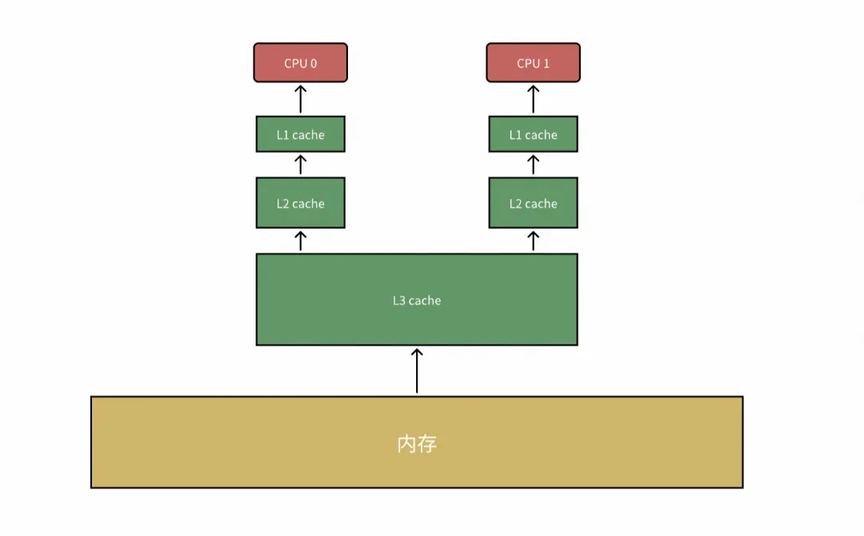
CPU 缓存共分为三级:
-
按访问速度从大到小排序为:L1 > L2 > L3
-
按容量从大到小排序为:L3 > L2 > L1
-
其中 L3 缓存 CPU 共享,L1、L2 缓存为各 CPU 独占。CPU 在访问内存数据时,会优先从高速缓存中访问,访问顺序依次为 L1、L2、L3,若高速缓存中都不存在,则再访问内存。
缓存的引入,降低了 CPU 直接访问内存的频率,大大提升了 CPU 的执行效率。
※ 缓存行
根据空间局部性原理,当 CPU 访问了一块数据时,相邻的数据很可能也即将被访问。那么是否可以通过预加载相邻的数据到高速缓存中,提升高速缓存的命中率呢?
当然可以,我们把预加载的这部分内存数据叫做缓存行。
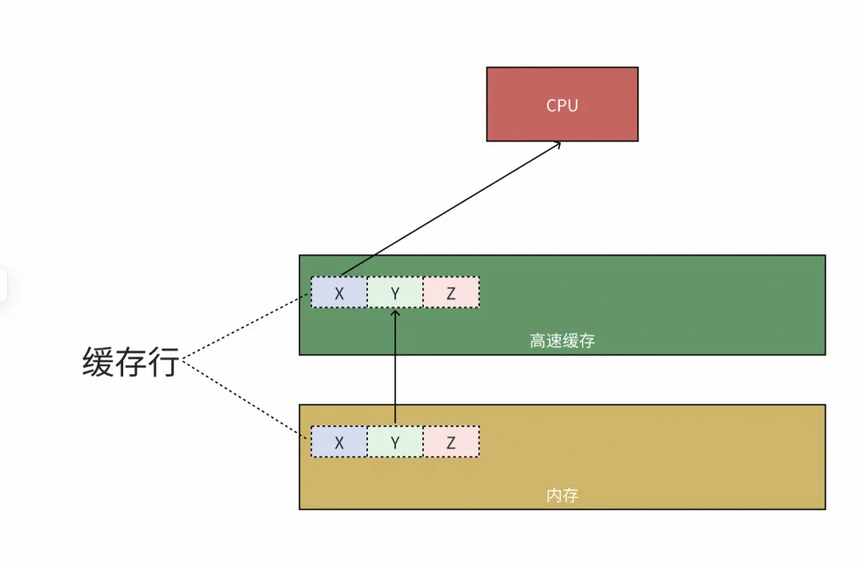
由图所示,内存被划分为若干缓存行的块,缓存行的大小是固定的,通常为 64 字节,高速缓存数据块最小粒度就是缓存行(换句话说,高速缓存内的数据就是由一个个缓存行构成的)。当 CPU 需要访问位于内存的数据 X 时,会将整个缓存行同时加载到高速缓存中,以提升程序后续执行时的缓存命中率。
CPU 内的“分布式”问题
高速缓存是把双刃剑,在大幅提升 CPU 运行效率的同时,也引来了一个 “分布式” 问题。
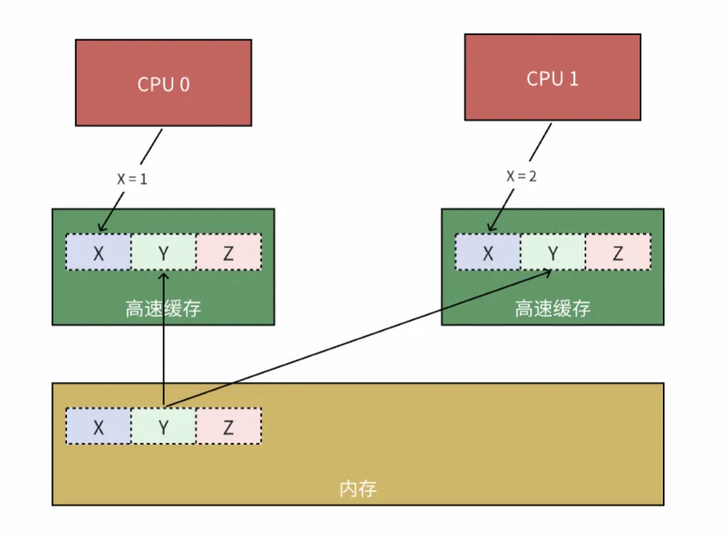
记得我们前面说过,CPU 的 L1、L2 缓存是各核心独占的,在两个 CPU 的 L2 缓存同时加载了同一个缓存行的情况下,当 CPU 0 数据 X 做了写操作(X = 1),其他 CPU 对这一修改是不可见的,这时 CPU 1 如果依然访问自己高速缓存中的数据,势必会产生数据不一致。
为了解决这个问题,缓存一致性协议便诞生了。
※ MESI 协议
缓存一致性协议有多种,最出名的就是 MESI 协议。
MESI 是 Modified Exclusive Shared Invalid 四个单词的缩写,分别表示缓存行的四种状态:
-
Modified:表示缓存行中数据已经被 CPU 修改了。
-
Exclusive:缓存行处于独占但尚未修改的状态,该状态表示其他 CPU 不可以预读取这个缓存行到自己的高速缓存中。
-
Shared:表示缓存行数据已经被多个 CPU 预加载到缓存中,且各 CPU 均未对该缓存行做修改。
-
Invalid:表示有其他 CPU 修改了该缓存行,缓存行数据已经失效。

-
CPU 0 需要修改缓存行中 X 的数据时,将当前缓存行标记为 Modified ,并向总线发送一条消息,表明缓存行 CPU 0 已经修改。
-
CPU 1 接收到该缓存行已失效的消息后,会将本地缓存行标记为 Invalid ,并 ACK 给 CPU 0。
-
CPU 0 收到其他 CPU 已经将本地缓存行标记失效消息后,修改 X 的值。
-
此时 CPU 0 高速缓存中缓存了 X 的最新值,其他 CPU 如果需要访问 X ,将会通过总线从 CPU 0 中获取。
MESI 协议非常复杂,比如各 CPU 之间是如何通信的、多个 CPU 同时发送失效事件怎么办等等。
篇幅所限仅做本文用的着的部分介绍。有兴趣了解具体实现可以点击 https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESI.htm 查看动画演示。
缓存一致性协议有效解决了各 CPU 间数据一致性问题。那么,代价是什么呢?
禁止 CPU 摸鱼
上图可以看出 CPU 0 在执行修改 X 的值之前,需要与其他 CPU 进行通讯,收到其他 CPU 将本地消息修改完成后,才可修改本地缓存行的数据。在这期间 CPU 0 一直无事可做。而不管是前面提到过的编译器指令重排序还是超线程、指令流水线等技术,目的都是在提升 CPU 的运行效率,减少 CPU 空跑时间。如果由于缓存一致性协议造成 CPU 空闲的话,这对于我们来说显然是不可接受的!
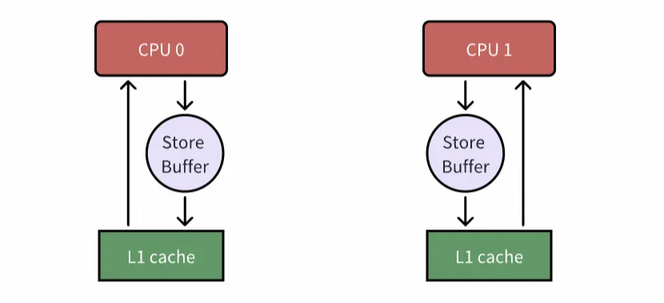
为了让 CPU 满负荷运转,芯片工程师在 CPU 与 L1 缓存之间又加了一层——store buffer。
引入了 store buffer 后,CPU 写缓存行不再需要等待其他 CPU 回复消息,而是直接读写 store buffer,等到特定时刻,再将 store buffer 中的数据 flush 到高速缓存中
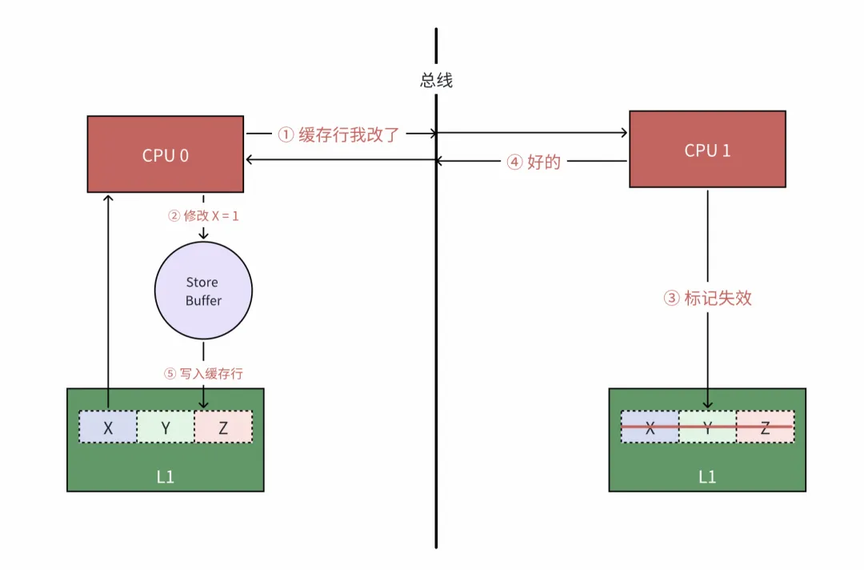
-
CPU 0 需要修改缓存行中 X 的数据时,将当前缓存行标记为 Modified ,并向总线发送一条消息。
-
CPU 0 不再等待 CPU 1 回复,而是直接将修改后的数据写入 store buffer 中。
-
CPU 0 收到 CPU 1 标记缓存已经失效的回复消息后,将 store buffer 中的值 flush 到高速缓存中。
问题会这么完美的解决吗?
1,乱序执行
现在我们将 store buffer 纳入考量,再来回头看本节开始的这段代码:

最终由于 store buffer 中数据的 flush 时间晚于 CPU 直接写高速缓存中数据的时间,客观上产生了 CPU 执行的指令顺序与实际代码中不一致的现象(X = B 早于 A = 1 执行,Y = A 早于 B = 1 执行),即乱序执行。最终得到了(A = 1,B = 1,X = 0,Y = 0)的结果。
既然发现了问题,那么要如何解决呢?这就要提到另一项技术:内存屏障。
随着 store buffer 技术的引入引起的问题还有很多,于是牵扯出一系列其他技术,如 Store Forwarding、Invalidate Queues 等技术。由于与本文涉及到的内容无关,这里就不做赘述了,各位有兴趣可以自行了解相关内容。
2,内存屏障
内存屏障听起来比较高大上,实际总结起来非常简单,就一句话:
去告诉 CPU,我在此处定义了一个内存屏障,自这里开始,后续所有针对高速缓存的写入,都必须先把 store buffer 中的数据全部 flush 回高速缓存中!
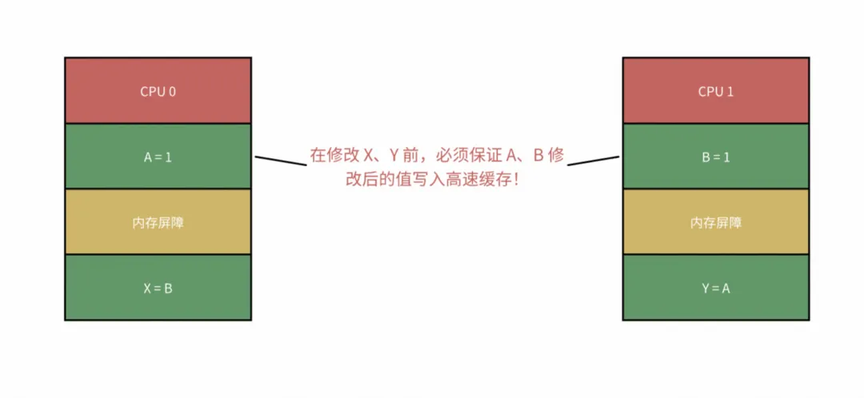

在 Java 中 volatile 关键字避免 CPU 乱序执行的原理其实就是在访问 volatile 变量时添加了内存屏障。限制后续数据的写入操作一定把当前 store buffer 中的数据 flush 到高速缓存中,再通过缓存一致性协议保证数据一致性。
回到本节一开始的代码,你一定想到了要如何让这段程序永远执行下去的办法了?
static int x = 0, y = 0;
没错,我们只需要限制针对数据 X、Y 的写操作之前,位于 store buffer 中的数据 A、B 全部 flush 到高速缓存即可。所以最终的解决方案就是给变量 A、B 添加 volatile 关键字即可!
想想为什么在变量 X、Y 上加 volatile 不可以?说加 4 个 volatile 的那位同学,课后把内存屏障这一章节抄写 3 遍!
前面说过,指令重排序问题在 CPU 和编译器层面都存在,CPU 层面说完了,那编译器层面呢?
3,编译器重排序
由于 JIT 编译后的指令不好扒,我们以 C 语言为例,先来看看下面的 C 语言例子:
int func(int a, int b, int c, int d) {
如果编译器不做优化,如果完全顺从我们代码语义,以上函数生成的汇编伪代码如下:
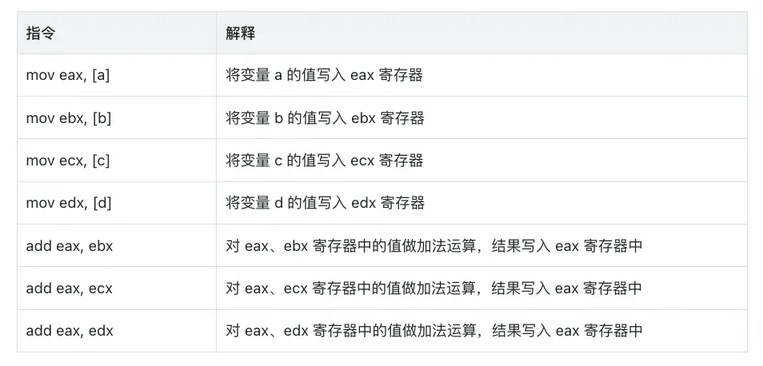

而现代 CPU 会有多个执行单元,例如读写单元、运算单元,这些执行单元之间可以独立工作。在执行上面的指令时,只能顺序执行,不能并行执行。要想发挥两个执行单元的效率,只需调整一下顺序即可:
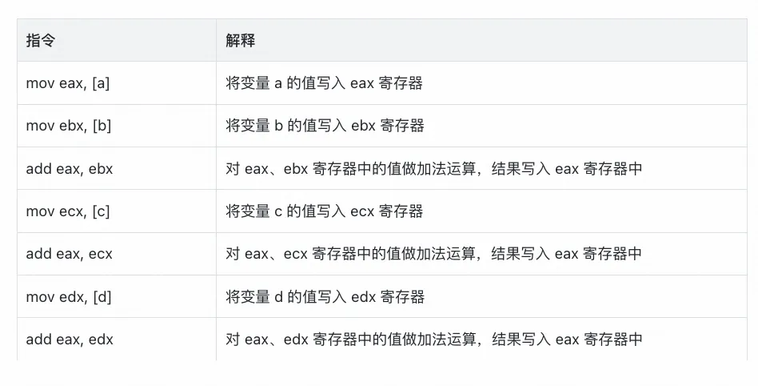

可以看出,虽然指令的数量一样,但在对指令做简单的重新排序后,优化一下指令的提交顺序,就可以更快的完成任务。
在 JVM 中,JIT 编译同样也会遵循这一原则,在不改变源码语义的情况下,改变 CPU 指令的执行顺序,就可以更快的完成运算任务,提升执行效率。这在单线程情况下运行良好,但多线程运行时,就可能会存在一些意料之外的问题。
三,可见性问题
再来看另一个示例:
private static boolean running = true;
上面的程序,并不会按照我们预期的那样正常输出程序结束后退出,而是会永远的执行下去(不要尝试用前文中的 store buffer 来强行解释这个问题,store buffer 本质上也是个 buffer,在某一时刻数据依然会 flush 到高速缓存中,从而让其他线程感知到最新的值)。
这就引出 volatile 关键字解决的另一个问题:内存可见性问题。
分层编译
我们知道,Java 是跨平台的。一个 Java 源码文件的执行需要两个过程:
-
AOT 编译:源代码文件编译为 class 文件。
-
JIT 编译:JVM 加载 class 文件,将 class 文件中字节码转换为计算器可执行的机器指令。
字节码的执行也有两种方式:
-
解释执行:优点是启动速度快,缺点是需要逐条将字节码解释为机器指令,开销大,性能低。
-
编译执行(JIT 编译):优点是执行效率高,与本地编译性能基本没差别,缺点是编译本身需要消耗 CPU 资源,以及编译后的指令数据需要存储,需要消耗内存空间。
而 JIT 编译器又分为两种,Client Compiler、Server Compiler。之所以叫 client,server 是因为在一开始设计这俩编译器的时候,前者是设计给客户端程序用的,就比如像 idea 这种运行在个人电脑上的 Java 程序,不会长时间使用,反而更注重应用的启动速度以及快速达到相对较优性能。而后者则是设计给服务端程序用的。
HotSpot 虚拟机带有一个 Client Compiler —— C1 编译器。这种编译器启动速度快,但是性能相对 Server Compiler 来说会差一些。Server Compiler 则更为激进,优化后的性能要比 Client Compiler 高 30%以上。HotSpot 虚拟机则带有两个 Server Compiler,默认的 C2 以及 Graal。
在 Java 7 之前,需要开发者根据服务的性质手动选择编译器。自 Java 7 开始,则引入了分层编译(Tiered Compilation)。
0:由解释器解释执行
1:C1 NO profiling:执行不带 profiling 的 C1 代码。
2:C1 LIMITED profiling:执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 代码。
3:C1 FULL profiling:执行带所有 profiling 的 C1 代码。
4:C2:执行 C2 代码。
谁动了我的代码
运行时编译有那么多层级,到底是哪层影响了代码的?
想要探究个问题很简单,只需要在 JVM 启动参数里增加 -XX:TieredStopAtLevel=XX 参数即可。TieredStopAtLevel 是控制 JVM 最大分层编译级别的参数,当我们配置的值 < 4 时,前文的代码均可以正常终止,那么结论很明显了:C2 编译器全责!
C2 你在干什么?!
为了探究 C2 编译对我们代码做了什么,我们决定使用一款工具:JITWatch。JITWatch 专门用来探究 JIT 编译后的代码对应汇编指令。
关于 JITWatch 使用的流程这里就不做赘述了,网上有大量说明。本节的案例也很好复现,大家可以动手试一试。
我们将前文的源码文件编译后,提交以下命令执行:
# Ubuntu 22.04 下
接着启动 JITWatch,加载 jit.log 文件:
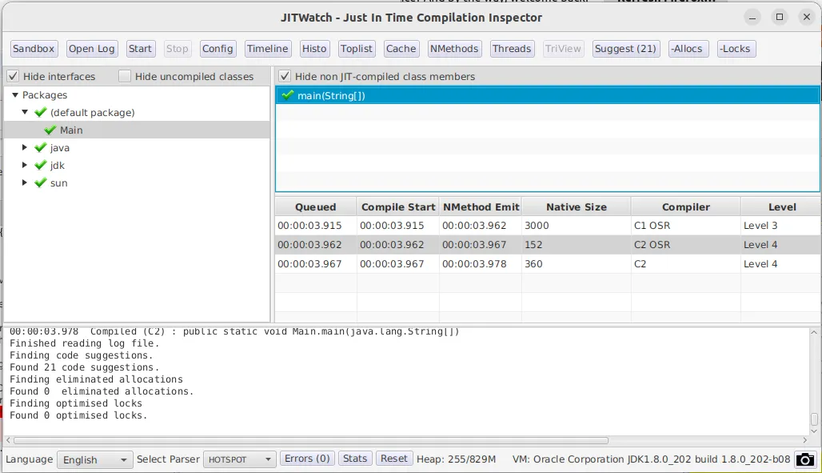
双击右侧 main 方法,查看 C2 编译后的结果:
记得选 OSR(栈上替换) 那个 C2,因为代码属于死循环,代码块不会退出,无法完整替换 C2 编译后的机器指令,只能通过栈上替换技术来进行。
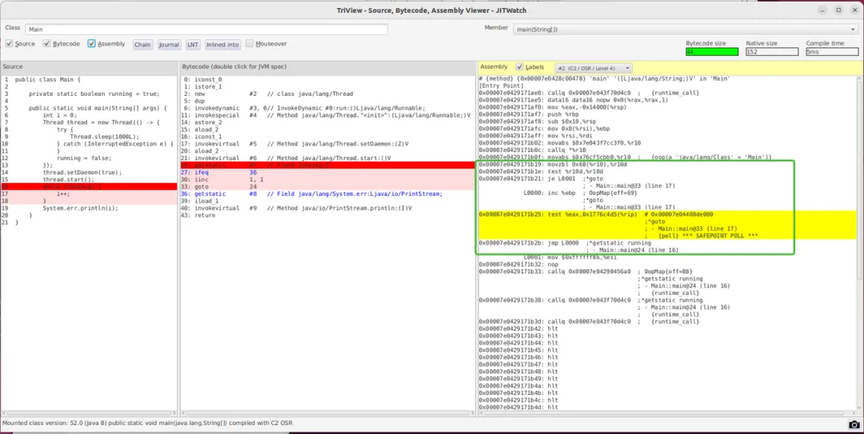
绿色框中为我们的核心代码,我在此处将它放大并增加了注释,如下:
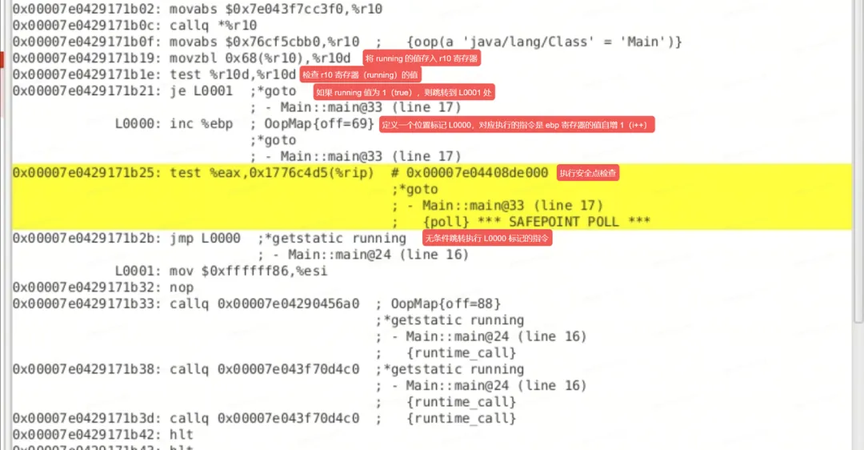
什么?无条件跳转?!
可以看出,由于 C2 编译器的激进优化,编译后的机器码不再判断 running 变量,从而产生了内存可见性问题。而即使 C2 编译后的机器指令依然会执行安全点检查。想想是不是可以利用安全点检查机制,用一些操作来让进程停止?比如提交执行一次 GC、打个断点之类的。
四,总结
说了那么多,能不能说点有用的?
有的有的,我们在多线程开发中,只要变量被多个线程共享,且是可变的,加上 volatile 准没错:)
往期回顾
1.社区搜索离线回溯系统设计:架构、挑战与性能优化|得物技术
3.eBPF 助力 NAS 分钟级别 Pod 实例溯源|得物技术
文 / 空载
关注得物技术,每周二、四更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
如有任何疑问,或想要了解更多技术资讯,请添加小助手微信
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


