
<blockquote> 在多模态大模型迅速发展的今天,我们已经能让模型”看图说话”,甚至”读懂表格”,但要让模型真正理解复杂的文档结构(例如在PDF中准确识别章节、表格、公式与图像的逻辑关系)依然是一个未被彻底解决的问题。
UniParse正是为此而生:它是一款面向AI应用的通用文档解析工具 ,旨在将文档中的非结构化内容转化为结构化语义信息,使多模态模型能够高效、精准地理解和利用文档内容。
本文将从技术视角介绍UniParse,功能方面的介绍请移步产品上线|商汤自研智能文档解析工具UniParse,重新定义文档处理!
一、为什么需要文档解析
现代大模型已经能够处理文本、图像、语音等多种模态,但在面对文档时仍然存在明显短板:
-
格式复杂:PDF、Word等文件中同时包含文字、表格、图片、公式、页眉页脚等多种内容,且层次不统一。
-
结构缺失:OCR只能识别文字,却无法恢复章节层级与逻辑顺序。
-
语义混乱:表格、图像与正文往往存在隐含关联,模型难以在语义上进行对齐。
这意味着,如果直接把整份文档输入多模态模型,模型将面临巨大的上下文噪声和空间混乱,生成效果不稳定,也无法进行精确问答。UniParse的作用,就是在模型”读文档”之前,帮它理清结构、分清语义、建立关联。
二、UniParse的技术流程
UniParse的核心流程分为两个主要阶段:版面分析(LayoutAnalysis)与内容提取(ContentExtraction) ,并辅以预处理 与内容合并两个辅助流程。整个流程既保持模块化设计,又在数据层实现了结构化信息流动,使得不同模态内容(文字、图片、表格、公式)能够被统一建模和调用。
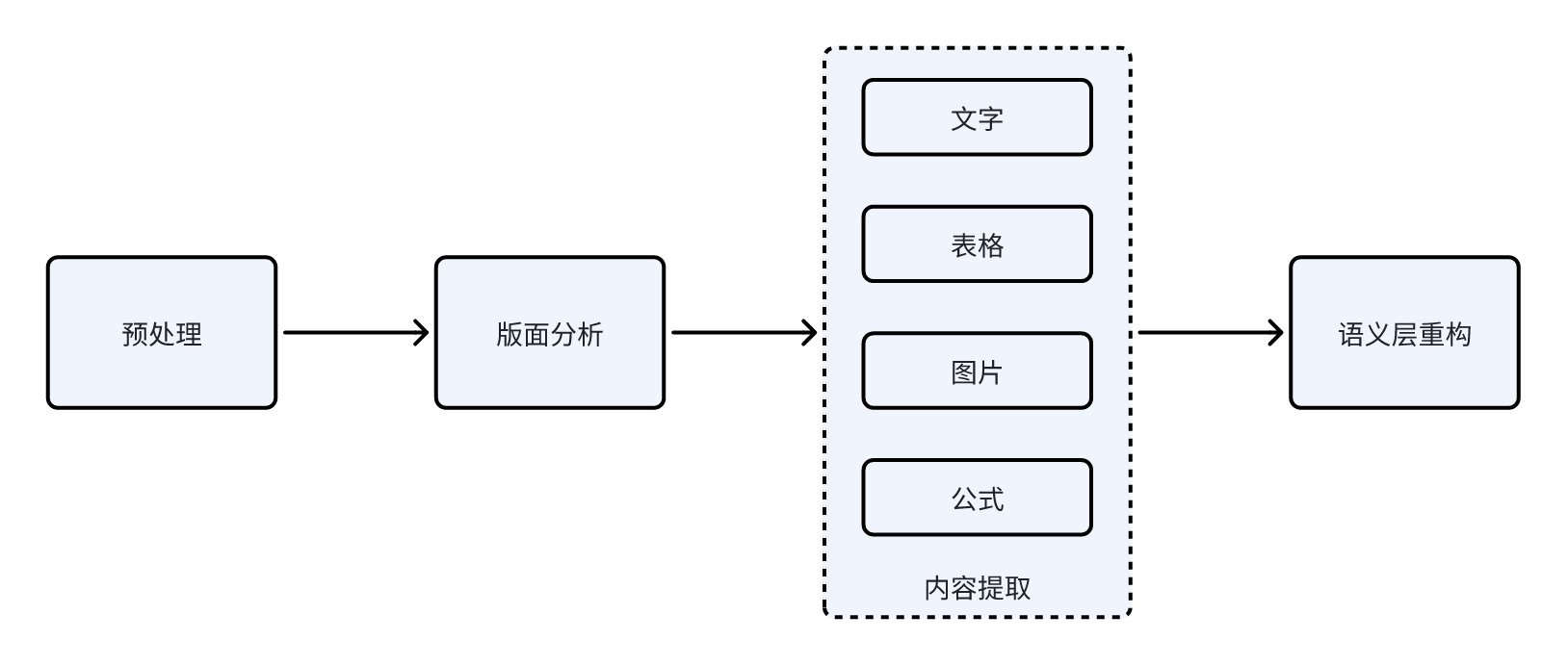
1️⃣文档预处理
UniParse的预处理阶段主要任务是统一输入格式 。系统会将各类文档(PDF、DOC、DOCX等)逐页渲染为高分辨率图像,保证不同文件格式在后续视觉模型中具有一致的输入维度。这一过程通常基于PyMuPDF或libreoffice的渲染引擎实现,可控制分辨率以兼顾清晰度与性能。
同时,预处理阶段还执行以下步骤:
-
页面编号与坐标标准化:为每页图像生成统一的坐标系,用于后续版面元素定位;
-
去噪与边缘裁剪:提升模型在扫描件、照片类文档上的鲁棒性;
-
文件元信息提取:(如页数、文件名、创建时间),用于文档追踪与任务调度。
经过预处理后,所有文档都被转化为一组图像文件及其基础元信息,为后续的版面解析与内容提取提供统一输入。
2️⃣版面分析
版面解析是UniParse的核心之一,目标是还原文档的空间与语义结构 。这一阶段采用视觉语言联合建模方法:
-
在视觉层面,利用版面分析模型(如LayoutLMv3或自研视觉Transformer)识别标题、正文、表格、图像、公式、脚注等区域;
-
在语言层面,通过文本块的字体、缩进、上下文语义判断章节层次与逻辑顺序;
-
最终将视觉检测结果与文本序列对齐,生成一个包含位置、类型与层级的结构化版面树。
3️⃣内容提取
UniParse针对不同类型内容采用专用解析管线:
-
文字:OCR模型或文本提取API结合版面坐标进行文本恢复与段落重建;
-
表格:基于结构化表格识别网络(如TableFormer或自研模型)恢复单元格位置、合并关系与层级结构,输出HTML/LaTeX格式;
-
图片:通过OCR或视觉语言模型(VLM)获取图像描述,为多模态模型提供语义锚点;
-
公式:采用基于Transformer的公式识别引擎将公式区域转化为可编辑的LaTeX表达式。
每种内容在抽取后都会带有来源页、坐标和上下文标签,以便在合并阶段进行定位与关联。
4️⃣语义层重构
最后一步是内容合并与输出。系统将前述多类型元素按照版面树的层级进行拼接,恢复出原文档的逻辑顺序与结构。这一阶段还可以进行:
-
内容去重与段落融合(防止跨页重复文本);
-
模态链接(表格、图像与正文语义匹配);
-
结构化输出(统一输出为JSON、HTML或Markdown格式)。
通过这一设计,UniParse能在保持文档可读性的同时,为下游多模态模型提供可计算的结构化输入。
三、UniParse与多模态大模型的协同机制
多模态模型的核心挑战之一是模态对齐。传统方法依赖模型内部注意力机制去”猜测”文本与视觉区域的对应关系,而UniParse提供了显式的结构锚点。
从工程上看,UniParse的结构化输出可以直接映射到模型输入的不同通道:
-
文本节点被编码为语言向量;
-
表格与公式节点可转换为结构token序列;
-
图像节点对应视觉特征向量;
-
节点之间的层级关系(如章节树)可编码为attentionmask,用于指导模型的跨模态关注。
通过这种方式,UniParse在模型输入阶段实现了结构化对齐:
-
模型在编码时能基于文档结构进行有选择的注意力分配;
-
上下文检索与问答更精确,因为每个节点都带有位置标签;
-
生成内容可以反向追溯到原文档区域,实现可解释性。
换言之,UniParse并非一个单纯的”预处理器”,而是为多模态大模型提供了结构感知接口,让模型真正理解”这是一份文档”,而不仅仅是一组视觉与文本片段。
四、应用场景:从文档解析到智能理解
UniParse的技术能力为多模态模型打开了更广阔的应用空间:
-
智能问答(QA):大模型可直接基于结构化数据进行文档问答,不仅能回答正文问题,也能解析表格、公式或图表。
-
知识抽取与检索增强生成(RAG):通过文档语义图构建可检索知识库,支持高精度上下文匹配。
-
报告生成与内容审校:结构化信息流使模型能生成符合格式规范的总结、分析报告或审阅意见。
-
图文理解与多模态推理:表格、公式、图片被视为独立模态单元,与文本共同构成推理输入,适用于学术报告、财务报表等复杂文档。
小结
在多模态智能系统的发展路径中,结构化理解是必经之路。UniParse作为文档解析的基础设施,为大模型提供了语义层级、视觉位置与逻辑关系的桥梁,使文档理解从模糊感知走向可解释推理。未来,模型的”读文档”能力将不断演进——它们不再仅仅识别信息,而是能够基于文档的结构和语义进行真正的理解与推理。
更多技术讨论,欢迎移步 “万象开发者” gzh!
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


