作者:vivo 互联网算法团队
本文聚焦多模态大语言模型(MLLMs)在文档问答(DocQA)任务中的性能提升,提出无需改动模型架构或额外训练的结构化输入方法,通过保留文档层次结构与空间关系(如标题、表格、图像位置)优化理解能力。研究发现,传统无结构OCR输入导致注意力分散,性能下降,而 LaTeX 范式结构化输入显著提升表现。注意力分析揭示其诱导”结构化注意力”,减少无关区域干扰,聚焦语义核心。在MMLongBench、PaperTab等四个数据集上验证,该方法尤其在复杂图表任务中效果显著,为智能文档处理与自动问答提供高效的解决方案。
本文提供配套演示代码,可下载体验:
一、引言
多模态大语言模型(Multimodal Large Language Models, MLLMs)蓬勃发展的今天,文档理解(Document Understanding)作为一项涉及文本、图表和图像的复杂任务,依然面临诸多挑战。如何高效整合多源信息、理解文档的层次结构,成为提升 MLLMs 性能的关键问题。研究发现了一种无需修改模型架构或额外训练的新方法:仅通过结构化输入提升 MLLMs在文档问答(DocQA)任务中的表现,同时通过注意力分析实践探寻结构化输入带来性能提升的深层原因。
二、文档理解的核心挑战
文档理解要求模型同时处理文本、图表、图像等多模态信息,并准确回答问题。然而,现有方法多依赖于扩展上下文窗口或优化检索增强生成(RAG),忽略了一个关键问题:输入格式如何影响模型的理解能力?
研究发现,传统的无结构 OCR 文本输入在某些case下未提升模型性能,反而因注意力分散和结构丢失导致性能下降。例如,在 MMLongBench 数据集上,加入无结构 OCR 文本后,模型准确率从 0.389 下降至 0.370。
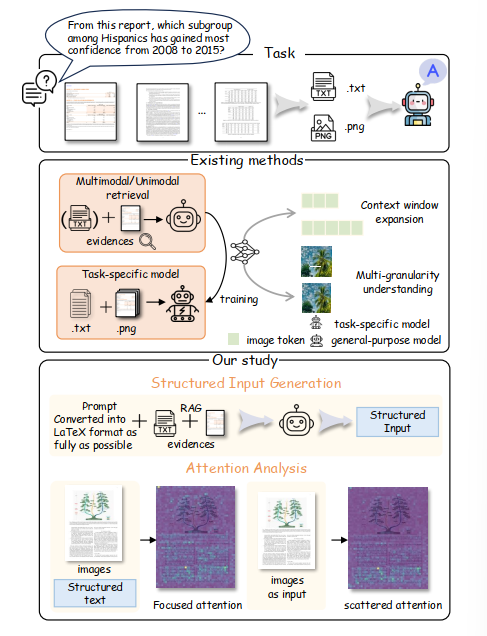
当前主流多模态大模型已经具备处理多模态信息的能力,其中Qwen2.5-VL-7B-Instruct,Phi-3.5-Vision-Instruct,SmolVLM-Instruct等在多个多模态任务上达到了SOTA,但在文档阅读任务中仍表现不佳。以往文档阅读模型通过训练得到专用模型来进行文档阅读理解,并基于文档回答问题,如mPLUG-DocOwl,Textmonkey等模型。但随着RAG的快速发展,像ColBERT 和ColPali 这样的RAG方法在分别检索文本或视觉信息方面已被证明有效,当前主流方法通常基于RAG检索证据页面,然后将证据信息直接输入多模态大模型中以便回答DocQAs。但当问题需要整合来自两种模态的信息时,它们通常表现不佳。
随着通用大模型的发展和AGI概念的普及,如何直接利用通用多模态大模型达到目的,不额外进行训练成为研究热点。改变输入结构能否帮助多模态大模型进行高效推理为本文探讨的重点。本文致力于探寻通用多模态大模型在何种条件下能够具有更加高效的推理理解能力,能否具备在trainning free的条件下达到较高的多元素文档理解能力。
三、创新方法:结构化输入与注意力分析
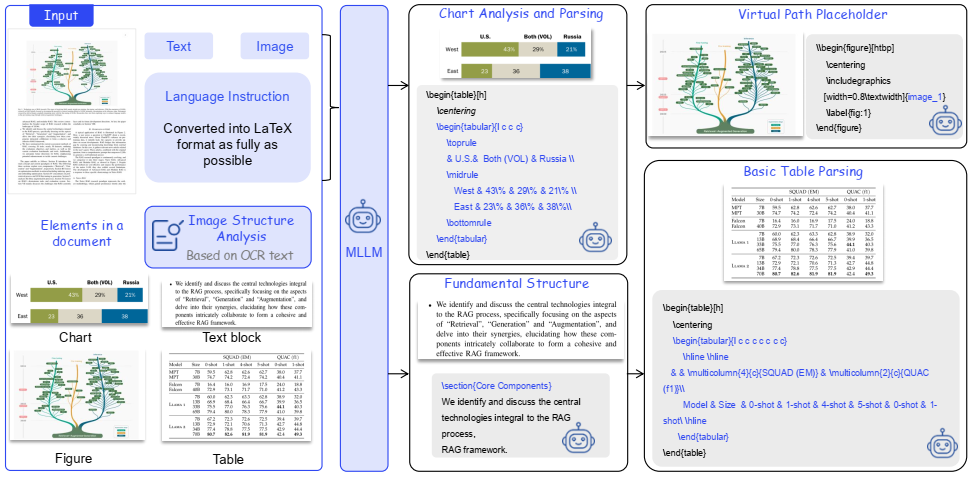
为解决这一问题,提出了一种基于 LaTeX 范式的结构保留方法。该方法通过保留文档的层次结构和空间关系(如标题、表格、图像的位置),从而为模型提供更清晰的语义引导。
具体流程包括:
-
结构化编码:将 OCR 文本和图像输入 MLLMs,提示模型尽可能保留图表、表格和文本的结构,生成 LaTeX 格式的表示。
-
联合输入:将结构化文本与原始图像一同输入模型,指导其在回答问题时关注关键区域。
-
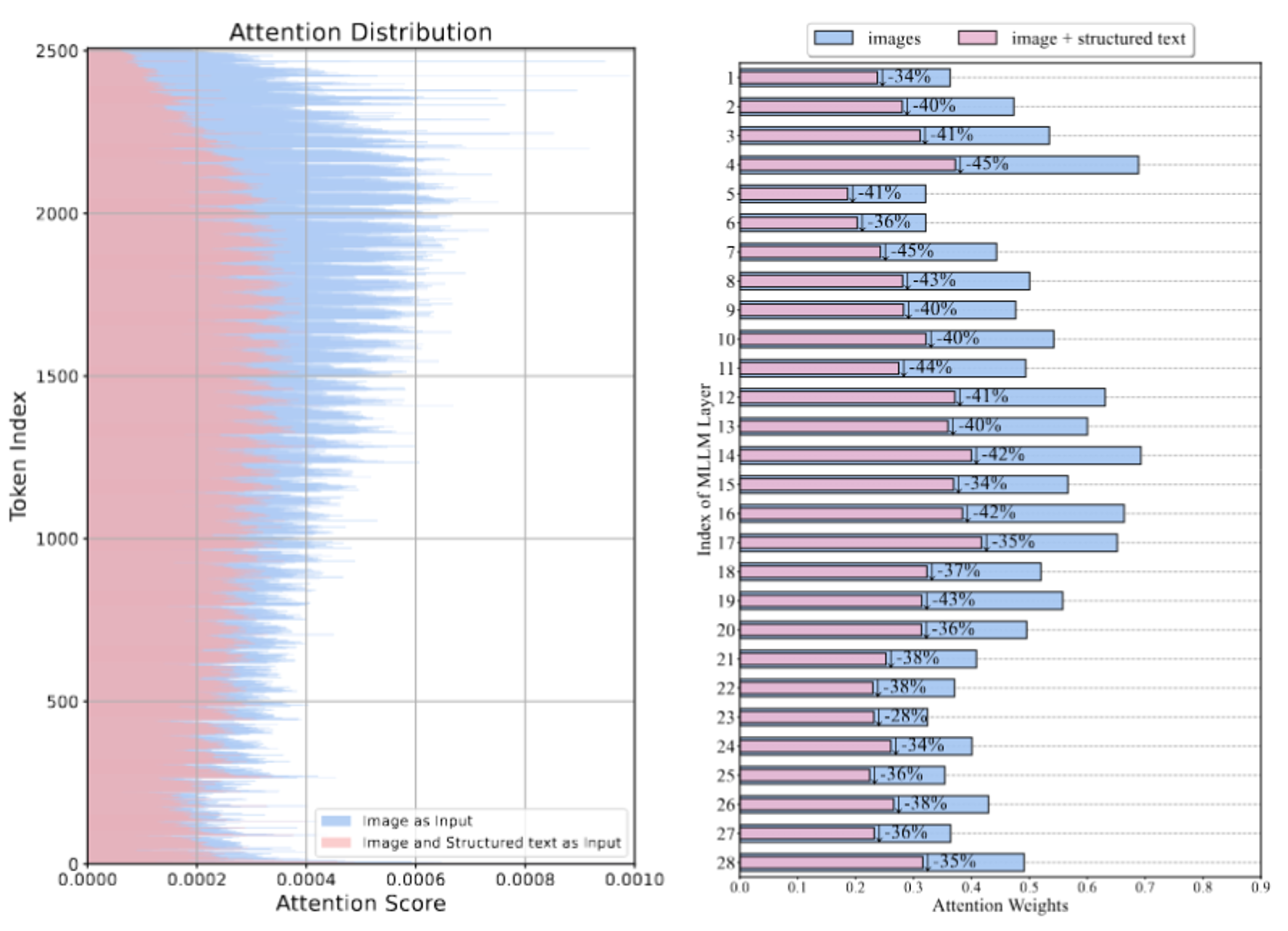
注意力分析:通过比较仅图像输入、图像加无结构文本、图像加结构化文本三种情况的注意力分布,发现结构化输入显著减少了注意力浪费,引导模型聚焦于语义相关的文本和图像区域。
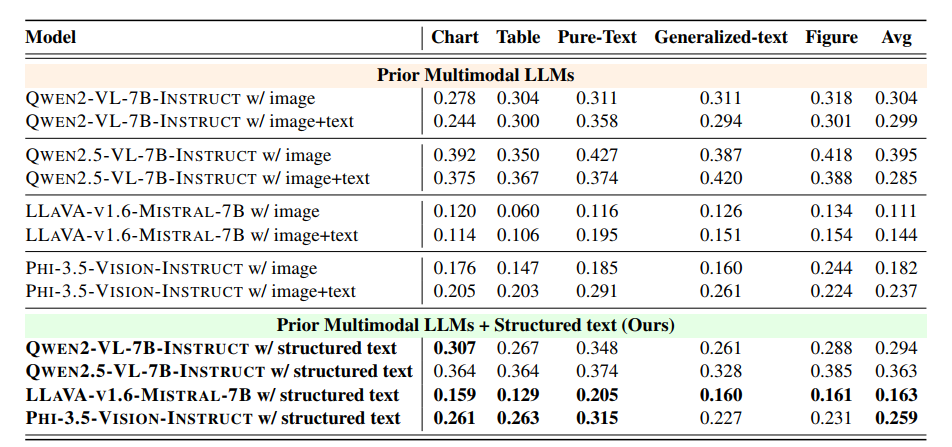
实验结果表明,该方法在多个文档理解基准数据集上显著提升了模型性能。例如,在 MMLongBench 上,QWEN2.5-VL-7B-INSTRUCT 的准确率从 0.389 提升至 0.435;在 PaperTab 数据集上,准确率提升高达 20%,得益于 LaTeX 格式对表格和图表的精准解析。
四、通过注意力机制进行深层原因探究
进一步的,通过注意力分析揭示了结构化输入的内在机制。无结构文本输入导致模型注意力分布散乱,浪费在图像边缘或无关区域;而结构化文本添加了结构化约束,诱导模型形成”结构化注意力”模式,聚焦于文档的核心内容(如图表、文本块)。例如,在一个案例中,模型需根据图表回答”西德居民对美俄关系的看法比例”。无结构输入下,注意力分散在图像空白区域;结构化输入后,注意力集中于图表和相关文本,显著提高答案准确性。

结构化输入帮助减少MLLMs对于图片边界token的关注度,提高了模型对于文章主体部分的注意力得分。
具体实例分析,证明结构化输入的重要意义。

五、实验验证与数据支持
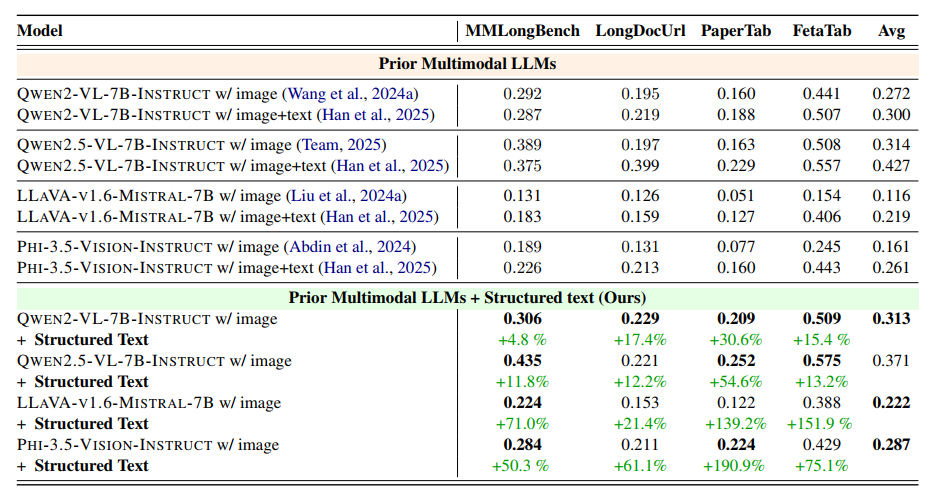
在四个文档理解基准数据集(MMLongBench、LongDocUrl、PaperTab、FetaTab)上测试4种 MLLMs 模型(如 QWEN2-VL-7B-INSTRUCT、Phi-3.5-Vision-Instruct)。结果显示,结构化输入在所有数据集上均提升了模型性能,尤其在包含复杂图表的 PaperTab 数据集上效果显著。消融实验进一步证明,仅用结构化文本或仅用图像的性能均低于两者结合,验证了结构化输入与图像联合使用的必要性。
六、总结与展望
实践研究揭示了输入格式对 MLLMs 文档理解能力的关键影响,提出了一种简单而高效的结构化输入方法。未来可进一步探索更先进的结构提取技术或设计注意力控制插件,以进一步释放 MLLMs 在文档理解中的潜力。该研究提供了一种无需重训模型即可提升性能的实用方案,适用于智能文档处理、自动问答等场景。在没有额外训练和架构修改的前提下,通过简单的结构化文本输入,可以提升现有多模态大模型在文档理解任务中的表现。此项研究可以帮助用户分析、工作解析等场景中更准确地提取信息,提升工作效率。同时,RAG(检索增强生成)系统也能结合结构化输入来降低信息检索中的噪声,从而更高效地利用检索到的证据页面,为未来文档处理与分析提供了新的实践路径。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


