
<span id="OSC_h1_1"></span> 一、 背景
Valkey 社区于 2024 年 09 月发布了 Valkey8.0 正式版,在之前的文章《Redis 是单线程模型?》中,我们提到,Redis 社区在 Redis6.0 中引入了多线程 IO 特性,将 Redis 单节点访问请求从 10W/s 提升到 20W/s,而在 Valkey8.0 版本中,通过引入异步 IO 线程、内存预取(Prefetch)、内存访问分摊(MAA)等新特性,并且除了将读写网络数据卸载到 IO 线程执行外,还会将 event 事件循环、对象内存释放等耗时动作也卸载到 IO 线程执行,使得 Valkey 单节点访问请求可以提升到 100W/s,大幅提升 Valkey 单节点性能。
Valkey 8.0中引入的异步 IO 与 Redis 6.0 中的多线程 IO 有什么区别?Valkey8.0 中如何应用内存预取和内存访问分摊技术进一步来提升性能的?本篇文章让我们来一起看看。
-
2024 年,Redis 商业支持公司 Redis Labs 宣布 Redis 核心代码的许可证从 BSD 变更为 RSALv2 ,明确禁止云厂商提供 Redis 托管服务,这一决定直接导致社区分裂。
-
为维护开源自由,Linux 基金会联合多家科技公司(包括 AWS、Google Cloud、Oracle 等)宣布支持 Valkey ,Valkey 基于 Redis 7.2.4 开发,作为 Redis 的替代分支。
-
Valkey8.0 为 Valkey 社区发布的首个主要大版本。
-
最新消息,在 Redis 项目创始人 antirez 今年加入 Redis 商业公司 5 个月后,Redis 宣传从 Redis8 开始,Redis 项目重新开源。
二、 异步 IO 线程背景
Redis6.0多线程IO
在 Redis 6.0 中引入了多线程 IO 特性,用来处理网络数据的读写和协议解析,读写数据执行流程如下所示:
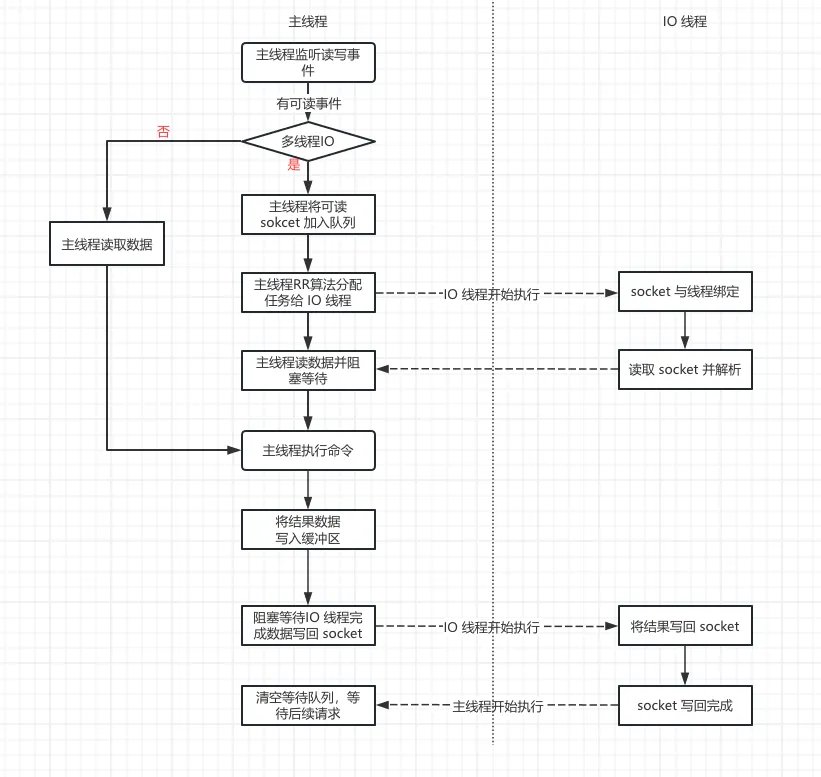
在 Redis6.0 中,读数据流程是主线程先将所有可读客户端加入一个队列,全部处理完后,再通过 RR 算法将这些可读客户端分配给 IO 线程,由 IO 线程执行读数据;写数据流程类似处理。
尽管引入多线程 IO 大幅提升了 Redis 性能,但是 Redis6.0 的多线程 IO 仍然存在一些不足:
-
主线程在处理客户端命令时,IO 线程会均处于空闲状态;由于主线程会阻塞等待所有 IO 线程完成读写数据,主线程在执行 IO 相关任务期间的性能受到最慢 IO 线程速度的限制
-
由于主线程同步等待 IO 线程,IO 线程仅执行读取解析和写入操作,主线程仍然承担大部分 IO 任务
Valkey 8.0 异步 IO 线程
Valkey8.0 通过使用任务队列使主线程向 IO 线程发送任务,IO 线程异步并行执行任务提升整体性能。Valkey 8.0 异步 IO 线程工作流程整体设计图如下所示:
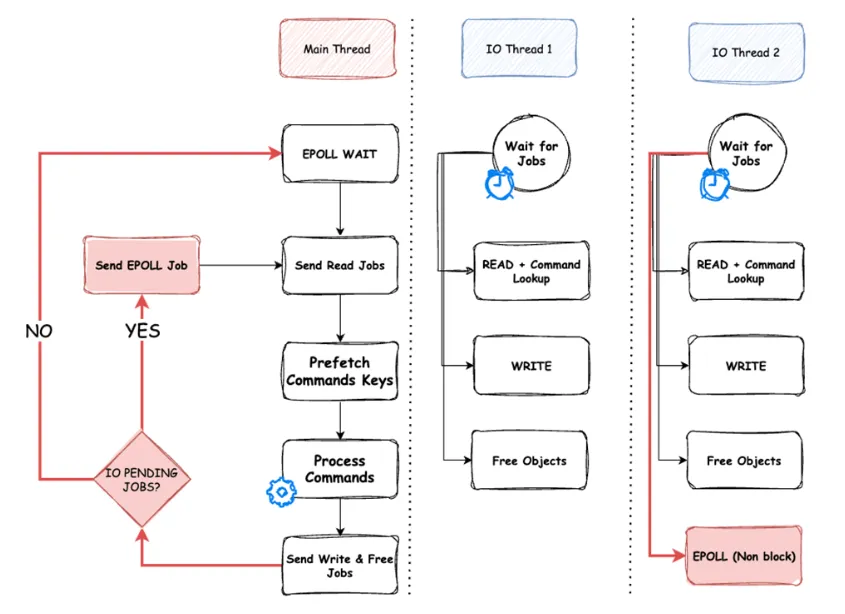
IO 线程初始化
在 Valkey 启动时进行初始化的时候,根据配置的线程数量server.io_threads_num 决定是否创建异步 IO 线程,如果server.io_threads_num == 1表示不开启,另外,IO 线程数量最大不超过 15 个;如果配置开启异步 IO 线程,则初始化的时候按需创建异步 IO 线程。
线程间通信
Valkey 初始化创建 IO 线程的时候,会给每个 IO 线程创建一个静态、无锁、固定大小(大小为 2048)的
环形缓冲区作为任务队列,用于主线程发送任务,以及 IO 线程接收任务。
环形缓冲区是从主线程到 IO 线程的单向通道。当发生读/写事件时,主线程会发送一个读/写任务,然后在进入 event 事件监测休眠之前,它会遍历所有待处理的读/写客户端,检查每个客户端的 IO 线程是否已经处理完毕。IO 线程通过切换客户端结构体上的原子标志 read_state / write_state 来表示它已经处理完一个客户端的读/写操作。
读数据流程
读数据流程如下图所示:
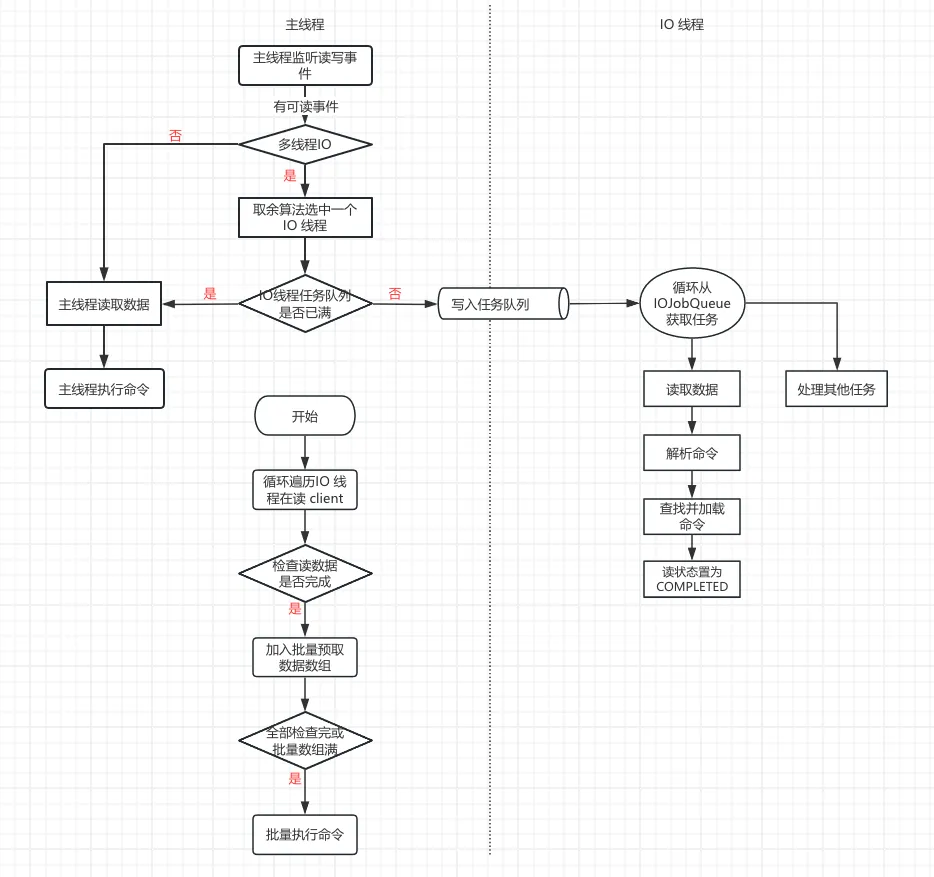
主线程监测到有读事件时,检查是否开启 IO 线程,如果开启了 IO 线程,会根据算法选择一个 IO 线程,检查选中的 IO 线程任务队列是否已满,如果任务队列未满,则将该待读事件客户端加入IO 线程的任务队列。
如果未开启 IO 线程,或者选中的 IO 线程任务队列已满,则由主线程完成读数据操作并执行命令。
IO 线程循环从任务队列获取任务,如果是读数据任务,则执行读数据流程。先读取数据,然后解析命令,并从命令列表中查找命令并保存在指定字段(这里也是把本来由主线程在执行命令时执行的动作卸载到 IO 线程完成)。
主线程在进入 event 事件监听睡眠前,循环遍历所有在等待 IO 线程读数据的客户端,检查数据是否读取完成,如果是则加入批量预取数据数组,当全部客户端都检查完成或者批量预取数据数组存满,则批量执行命令。
在 Redis6.0 中,需要先将所有可读客户端存入一个队列,再遍历可读客户端列表通过 RR 算法将可读事件分配到不同的 IO 线程中,然后主线程设置 IO 线程开启读数据,在主线程执行这些操作期间,IO 线程均处于空闲状态。
在 Valkey 8.0 中,每监测到一个可读事件,立即通过任务队列发送到一个 IO 线程,IO 线程立即可以开始读数据操作,主线程遍历后续可读事件期间,IO 线程异步在执行读取操作。
写数据流程
主线程执行完每个命令时,将客户端加入等待等写队列clients_pending_write,将响应客户端的数据写入到响应缓存 buf 或者 reply 链表。
主线程处理完所有命令后,循环遍历等待写队列clients_pending_write,将通过算法选择一个 IO 线程,如果选中的 IO 线程任务队列未满,将该客户端写数据任务加入 IO 线程的任务队列。
IO 线程循环从任务队列获取任务,如果是写数据任务,则执行写数据流,将数据写回给用户。
动态调整 IO 线程数量
每次在有可读事件或者可写事件需要执行前,Valkey 会根据可读/写事件数量,动态调整活跃 IO 线程数量,最大活跃 IO 线程数量不超过设置的允许 IO 线程数量(固定为 15)。
根据可读/写事件数量、每个 IO 线程可执行事件数量(可配置)、以及最大允许活跃 IO 线程数量,计算需要的目标活跃 IO 线程数量,当前活跃 IO 线程数量小于目标数量时,可增加活跃 IO 线程,当前活跃 IO 线程数量大于目标数量时,可减少活跃 IO 线程。
动态增加或者减少活跃 IO 线程数量,减少活跃 IO 线程并不会直接关闭创建出来的 IO 线程,而是通过加锁使当前没有任务可执行的 IO 线程暂停轮询查找任务,避免 IO 线程不必要的空轮询;同样增加活跃 IO 线程只需要主线程释放锁即可,IO 线程获取到锁后,开始轮询获取是否有可执行任务需要执行。
- 尽管 I/O 线程数量可动态调整,具有动态特性,但主线程仍保持线程亲和性,确保在可能的情况下由同一个 I/O 线程处理同一客户端的 I/O 请求,从而提高内存访问的局部性。
卸载更多任务到 IO 线程
在 Valkey 8.0 中,除了读取解析数据/写入操作之外,还将很多额外的工作卸载到 I/O 线程,以便更好地利用 I/O 线程并减少主线程的负载。
事件轮询卸载到 IO 线程
在 Valkey 中使用了 IO 多路复用模型实现在主线程中来高效处理所有来自客户端的连接读写访问,而套接字轮询系统调用(例如epoll_wait)是开销很大的过程,仅由主线程来执行会消耗大量主线程时间。
在 Valkey8.0 中,当主线程有待处理的 I/O 操作或要执行的命令时,主线程都会将套接字轮询系统调用调度到 IO 线程执行,否则由主线程自身来执行。
为避免竞争条件,在任何给定时间,最多只有一个线程(io_thread 或主线程)执行epoll_wait,当主线程将事件轮询系统调用分配给一个 IO 线程执行后,主线程执行完命令处理后,不再执行事件轮询系统调用,而是直接检查 IO 线程的轮询等待结果,查看是否有可读写事件。
对象释放卸载到 IO 线程
在 Valkey 读取客户端数据后,命令解析过程中会分配大量命令参数对象,在命令处理完成后,需要释放为这些命令参数分配的内存空间,在 Valkey8.0 中,将这些命令参数内存空间释放分配给 IO 线程执行,并且会分配给执行该参数解析(内存分配)的同一个 IO 线程来执行(通过客户端 ID 进行标识)。
命令查找卸载
如前面在读数据流程中提到的,当 IO 线程解析来自客户端的 Querybuf 的命令时,它可以在命令字典中执行命令查找,并且 IO 线程会将查找到的命令存储在客户端的指定字段中,后续主线程执行命令时直接使用即可,可以节省主线程执行命令的时间。
三、 数据预取(Prefetch)与内存访问分摊(MAA)
在 Valkey8.0 中引入异步 IO 线程提高并行度,并且将更多的工作转移到 IO 线程,将主线程执行的 I/O 操作量降至最低,此时,经过测试,单个 Valkey 节点每秒处理请求可达 80W。
通过分析开启 IO 线程后 Valkey 性能,主线程大部分时间都花销在访问内存查找 key,这是因为 Valkey 字典是一个简单但低效的链式哈希实现,在遍历哈希链表时,每次访问 dictEntry 结构体、指向键的指针或值对象,都很可能需要进行昂贵的外部内存访问。
于是在 Valkey8.0 中引入了**数据预取(Prefetch)和内存访问分摊(MAA)**技术,进一步提升 Valkey 单节点访问性能。
数据预取(Prefetch)
随着摩尔定律在过去 30 年间的持续生效,CPU 的运算速度大幅提升,而存储器(主要是内存)的速度提升相对较慢,这导致了存储器与 CPU 之间的速度差异。当 CPU 执行指令时,如果需要从内存中读取数据或指令,由于存储器速度的限制,CPU 可能需要等待访问存储器操作完成,从而导致性能瓶颈。
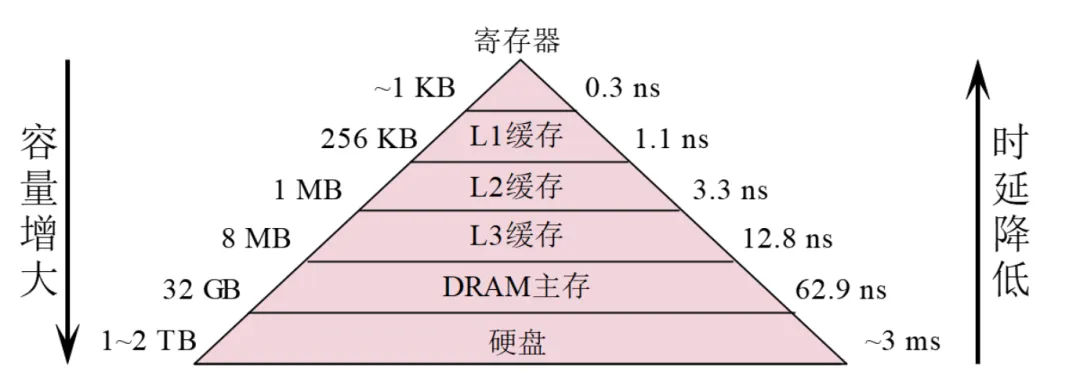
为了解决访问存储器瓶颈这一问题,现代计算机系统采用了多级缓存及内存层次结构,包括 L1、L2、L3 缓存以及主存等。尽管高速缓存(Cache)能够提供更快的访问速度,但其容量有限,当 CPU 访问的数据无法在高速缓存中找到时,就需要从更慢的内存层级中获取数据,这会导致较高的访问延迟,并降低整体性能。
数据预取(Prefetching)技术可以在一定程度上解决访问存储器成为 CPU 性能瓶颈的问题。数据预取是一种提前将数据或指令从内存中预先加载到高速缓存中的技术。通过预取,CPU 可以在实际使用之前将数据预先加载到缓存中,从而减少对内存的访问延迟。这样可以提高访问存储器的效率,减少 CPU 等待访问存储器的时间,从而提升整体性能。
__builtin_prefetch() 是 gcc 编辑器提供的一个内置函数,它通过对数据手工预取到 CPU 的缓存中,减少了读取延迟,从而提高程序的执行效率。
在 Valkey8.0 中,主线程在执行命令之前,通过使用 __builtin_prefetch() 命令,对所有即将操作的命令参数、key 及对应的 value 进行批量预取,提高主线程执行命令的效率。
内存访问分摊(MAA)
内存访问摊销 (MAA) 是一种旨在通过降低内存访问延迟的影响来优化动态数据结构性能的技术。它适用于需要并发执行多个操作的情况。其背后的原理是,对于某些动态数据结构,批量执行操作比单独执行每个操作更高效。
这种方法并非按顺序执行操作,而是将所有操作交错执行。具体做法是,每当某个操作需要访问内存时,程序都会预取必要的内存并切换到另一个操作。这确保了当一个操作因等待内存访问而被阻塞时,其他内存访问可以并行执行,从而降低平均访问延迟。
Valkey8.0 预取数据应用
Valkey 是一个键值对数据库,在 Valkey 中的键值对是由字典(也称为 hash 表)保存的,如下图所示的链式哈希表。
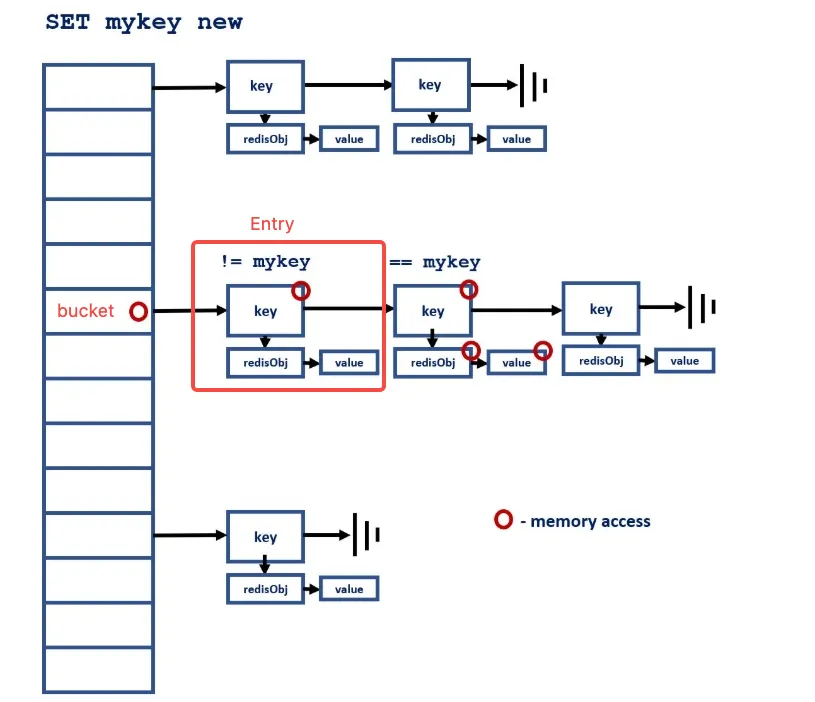
在 Valkey8.0 之前,在哈希表中查找一个 key 及对应的 value 步骤如下描述:
-
计算 key 的 hash 值,找到对应的 bucket
-
遍历存储在 bucket 中通过链表连接的 entry,直到找到需要的 key
-
如果找到 key,再访问 key 映射的 RedisObj(也就是存储的 value),如果存储的 value 是OBJ_ENCODING_RAW类型,还需要进一步访问内存地址获取真正的数据
每一步操作都需要等待前面的步骤完成内存数据读取,整个访问过程是一个串行步骤,这种动态数据结构会阻碍处理器推测未来可以并行执行的内存加载指令的能力,因此访问内存成为 Valkey 处理数据的性能瓶颈。
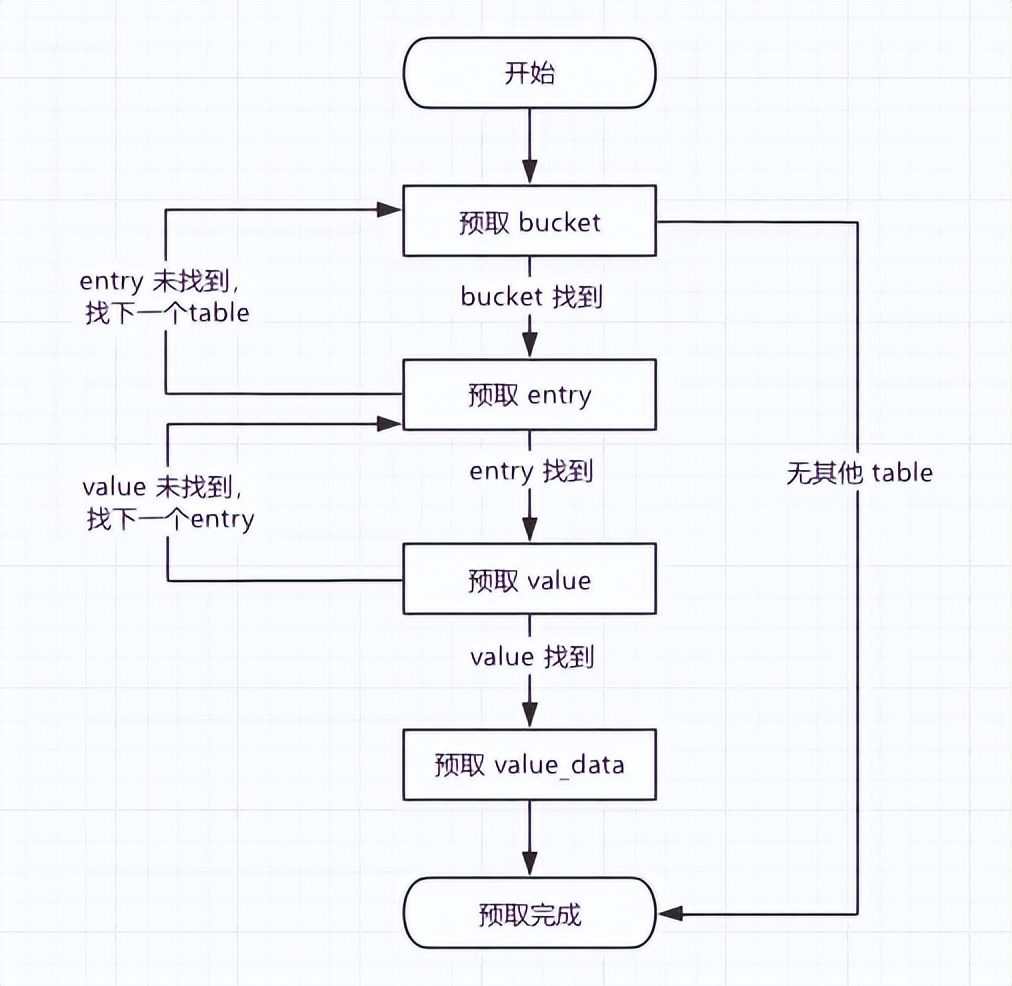
在 Valkey8.0 中,对于具有可执行命令的客户端(即 IO 线程已解析命令的客户端),主线程将创建一个最多包含 16 条命令的批次,批量处理这些命令。并且执行命令前,先将命令参数预取到主线程的一级缓存中,再将所有命令所需的字典条目 entry 和值 value 都从字典中预取。
同时,预取命令所需的字典条目 entry 和值 value 时遍历字典的方式与上述查找 key 过程类似,不同的是,每个 key 每次只执行一步,然后不等待从内存中完成读取数据,而只是预取数据,然后继续执行下一个 key 的下一次预取动作。这样当所有 key 都遍历完成第一步后,开始执行第二步的时候,执行第二步所需的第一步数据已经预取到了 L1 高速缓存。这样通过交错执行所有 key,并且结合预取,达到分摊访问内存的效果。
单个 key 预取流程如下所示:
每批次多个 key 预取流程则是循环遍历每个 key 交错执行上述步骤,先预取其中一个 key 的 bucket,然后不会执行预取该 key 的 entry,因为此时如果接着流程预取该 key 的 entry,需要等待将该 key 的 bucket 内存读取出来;而是执行下一个 key 的预取动作。也就是达成所有 key 的预取动作一直在并行执行效果,分摊内存访问时间。
多个 key 批量预取流程如下所示:
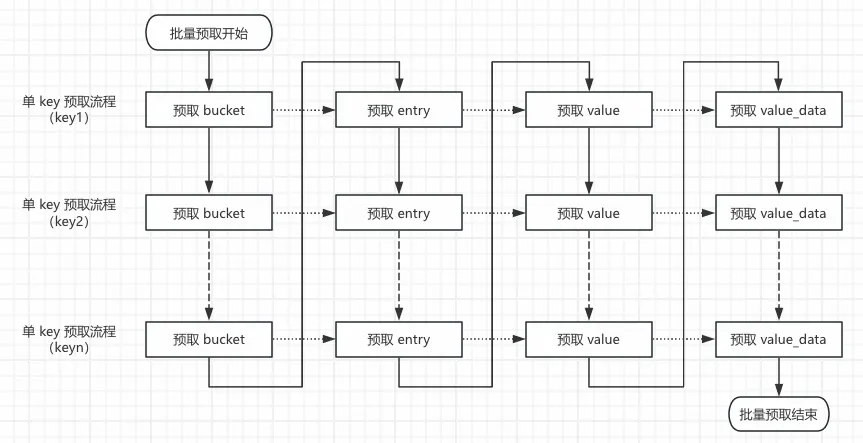
循环遍历每个 key 交错执行上述步骤,先执行一个 key 的预取动作,然后交错执行另一个 key 的预取动作,所有 key 的预取动作并行执行,降低所有 key 访问内存总时间。
同一批次所有 key 和 value 都完成预取后,主线程开始批量执行命令。相比在 Valkey8.0 之前的版本中,主线程逐个处理每个客户端命令,批量预取数据加上批量处理,大幅提升单节点 Valkey 服务器性能,社区测试单节点 Valkey 访问请求可以达到每秒 120W。
四、 总结
本文分析了在 Valkey8.0 中通过引入**异步 IO 线程、内存预取(Prefetch)、内存访问分摊(MAA)**等新特性,极大的提升了 Valkey 单节点性能,这些技术手段和算法思想也值得我们在实际业务开发中借鉴和使用。
Valkey8.0 中以上性能提升特性由亚马逊贡献,亚马逊也做了一系列压测对比,在增强 IO 多路复用的加持下,Valkey 单节点 QPS 最大可以超过 100W,压测数据可以参考《推陈出新 – Valkey 性能测试:探索版本变迁与云托管的效能提升》(https://aws.amazon.com/cn/blogs/china/valkey-performance-testing-exploring-version-changes-and-cloud-hosting-performance-improvements/),单节点性能完全可以比肩 Redis 低版本中等规模集群了。
在 Valkey8.0 版本中,除了以上重大性能提升优化以外,还在提升内存利用率、加快主从复制效率、增强 resharding 过程中高可用性、实验性支持 RDMA,以及提升集群的观测性等方面都进行了多项优化。我们后续再详细介绍。
Valkey8.0 正式版发布至今时间还不算太长,经过一段时间的验证后,我们也会考虑将自建 Redis server 版本逐步升级到新版本,为业务提供性能更优的缓存服务。
往期回顾
1.Java SPI机制初探|得物技术
2.得物向量数据库落地实践
3.Java volatile 关键字到底是什么|得物技术
4.社区搜索离线回溯系统设计:架构、挑战与性能优化|得物技术
5.从 “卡顿” 到 “秒开”:外投首屏性能优化的 6 个实战锦囊|得物技术
文 / 竹径
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


