来源:36氪

文 | 郑铭泽
编辑 | 康晓
来源| 窗智记(ID:FYCnicole)
封面来源 | 企业官网
“中国将赢下这场人工智能的全球竞赛。”英伟达CEO黄仁勋的最新言论,在美国掀起轩然大波。他在一场闭门会中声称,中国在AI领域的实力与美国只有“几纳秒之差”——彼时,这些言论更像是针对白宫的一种政策游说。
但黄仁勋可能无法预料,他所说的中美AI“几纳秒之差”的拐点,正被一家估值仅33亿美元的中国初创公司打破。
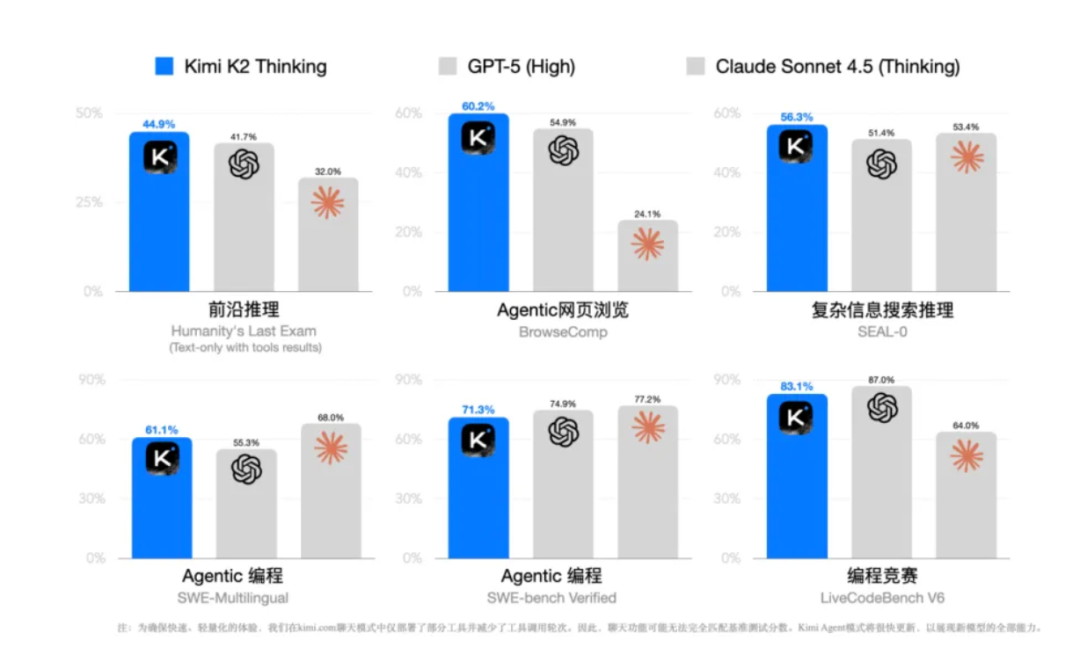
11月6日,黄仁勋发出严厉预警后仅仅一天,月之暗面发布最新模型Kimi K2 Thinking,在Humanity’s Last Exam、TAU-Bench等重要基准测试中,超越GPT-5、Claude 4.5等全球最强开源乃至闭源模型。
巧合的是,Kimi K2 Thinking发布当天,英伟达股价一路下跌,市值蒸发超1800亿美元。有网友调侃,“每当中国发布先进模型,总能给华尔街带来亿点点震撼”。
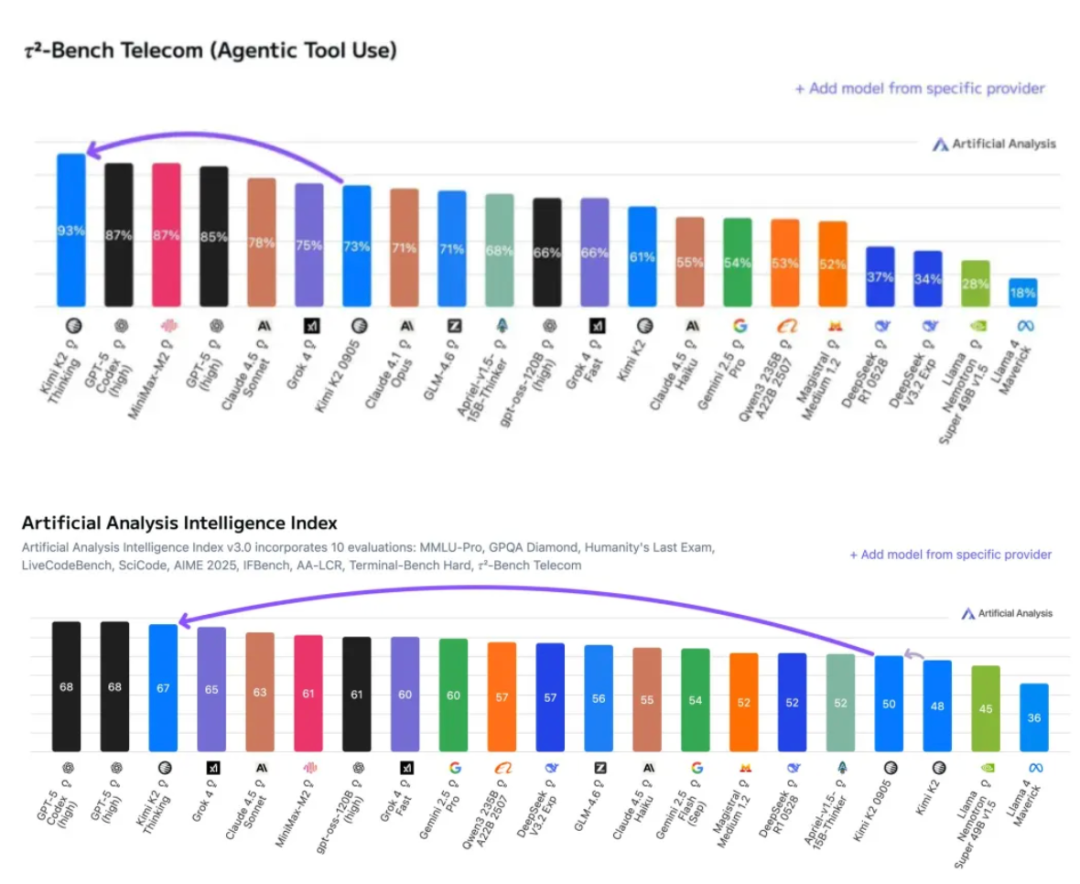
在专业机构Artificial Analysis智能体工具的调用测试中,Kimi K2 Thinking的得分达到93%,是目前第三方机构测量到的最高分;在智能指数中,则以67分排名第3,仅次于GPT5。
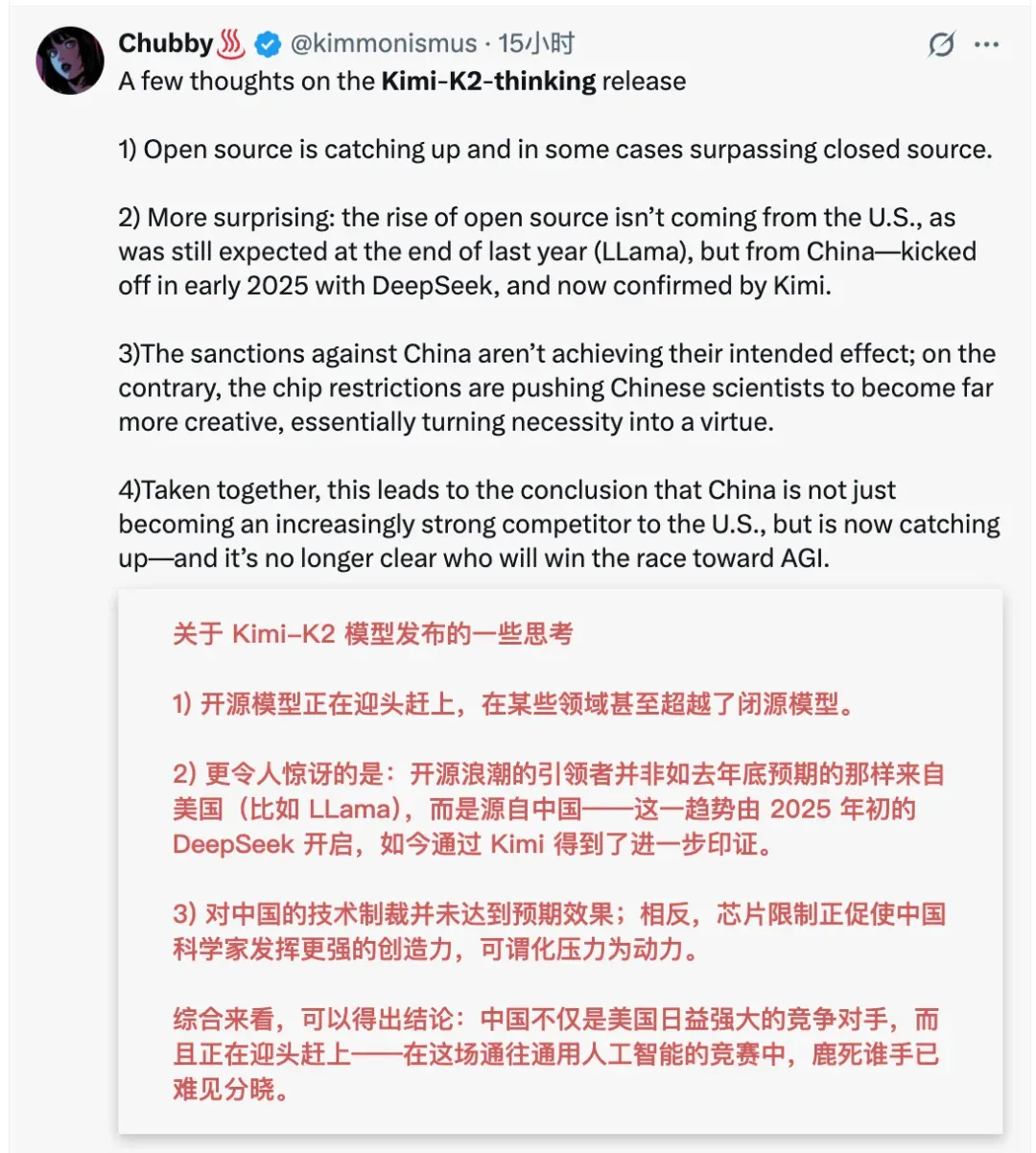
短短两天,Kimi K2 Thinking下载量已超过5万,成为人工智能全球最大开源社区Hugging Face最热门的开源模型。“这是另一个DeepSeek时刻吗?”Hugging Face联合创始人Thomas Wolf在个人社交账号上敲下评论。
海外的开源社区和科技媒体上,开发者对Kimi K2 Thinking的赞誉也纷至沓来。
而此时,距离Kimi年初陷入DeepSeek打击的至暗时刻刚过去10个月。
杨植麟的幸运之处在于,为月之暗面搭建了一个结构稳定的200人左右的技术人才组织,这构成了Kimi最重要竞争力。
AGI就像月球暗面一样,要看到它很难,但在AGI的登月时刻到来之前,杨植麟没有认输——估值不及OpenAI 1%,人力、资金、资源全落下风,在这场完全不对称的战争里,坚持发展基座大模型的月之暗面,拼杀出一种堂吉诃德式的悲壮。
很多人或许会质疑,这是不是又一次大模型跑分的胜利?“创智记”的判断是:Kimi K2 Thinking除了在INT4量化等底层技术上实现突破,更重要是在效率和智能体商业化应用上改写基座大模型竞争的格局。
简而言之,Kimi K2 Thinking一个大模型上承载了月之暗面的三大野心:
第一、追平甚至超越OpenAI等闭源大模型的部分能力;
第二、对齐乃至超越DeepSeek的成本效率;
第三、定义未来智能体调用的行业标准。
可以看出,即便在今年砍掉To C市场投入的至暗时刻,月之暗面的战略依然是探索AGI时代成功的最大可能性——那么,对标硅谷,今天的Kimi,资本市场应该给出多少估值?
对Kimi而言,To C用户市场的竞争依然惨烈,这靠低成本无法解决,毕竟DeepSeek式的机遇不可求,接下来要考验这个年轻团队的持续创新能力,能否获取足够弹药。
但作为基建的开源大模型,K2已经成为国内乃至硅谷开发者们的最热门选择之一。

超稀疏MoE:
底座模型K2的智能进化
人类大脑是一个极致高效的智能系统,其工作机制可以理解为稀疏编码:大脑在任何一个瞬间,只有极少数神经元处于活跃状态(被编码)。这种机制是高效和节能的体现。
Kimi K2 Thinking底座模型K2的成功之处,在于向人类大脑智能大幅进化,找到了一种在更低算力下实现高性能的新路径,320亿参数的运行成本即能获取万亿参数模型的知识和能力。据CNBC报道,K2 Thinking的训练成本仅为460万美元。
Kimi对传统MoE架构(包括DeepSeek等开源模型)进行了一系列深度优化,可以称之为“超稀疏MoE”,并集成了一系列开源生态成果。
K2 Thinking以1万亿参数位居全球大模型前列,但每次推理只激活3.2%(320亿)参数,在效率上冲至第一。排名第二的是DeepSeek(5.5%);据AI专家的技术分析,GPT-4/5在10%左右。
K2的MoE包含高达384个专家网络,但在执行一个复杂的Agentic任务时,K2只激活8个,稀疏度48倍,能动态的、按需的进行专家调用,提升了处理复杂任务的深度和效率。
理论上,任何MoE模型都可以做到只激活部分专家。但实践中,真正的难题在于:1、专家间的负载均衡:大多数模型容易出现部分专家过度使用,导致退化为稀疏全连接;2、路由延迟与训练稳定性:专家选择本身是一个非微分过程;3、量化后的稳定性崩溃:INT4下,训练振荡更明显,梯度传播容易塌陷。
K2的突破点在于它把路由器与专家层训练分离,采用了异步蒸馏机制——即先用高精度教师模型训练路由模式,再用低比特学生模型复现推理路径。
这是一种“先教会它怎么思考,再教它用低算力思考”的方式。简单来说,K2是通过工程细节“堆”出来的系统稳定性,而非仅靠架构新奇——这也意味着,它的复制难度极高:你可以看到架构,但未必能复现路由收敛、权重量化的精度平衡。
10月31日,月之暗面又开源了一项新的Kimi Linear架构(下一代的混合线性注意力机制),从全注意力向高效线性注意力跃迁,以此解决传统Transformer的痛点:全注意力机制的计算复杂度随序列长度呈平方级增长(O(N²)),导致超长上下文场景下显存爆炸与推理延迟。Kimi Linear开源后已获vLLM官方支持。
据“创智记”了解,Kimi Linear架构最近先在480亿参数的模型上做了成功验证,在模型速度提升、内存优化上取得了巨大进展。这与K2把下一代Muon优化器扩展到万亿规模的路径类似,先在2月应用到几百亿参数规模的moonlight系列模型做验证。
对标硅谷巨头的大模型,K2验证了另一种增长曲线:通过参数动态激活与极致压缩,让模型的“有效智商”不再与显存线性绑定。
对AI生态而言,这种变革带来三层影响:
技术层:重新定义“规模”与“效率”的边界;
经济层:大幅降低1T级模型推理成本,使中型企业也能负担高性能模型;
生态层:推动开源INT4和MoE架构的优化,形成更透明的底层创新循环。
换句话说,K2让“更聪明的AI”不再意味着“更贵的AI”。


INT4量化:
将效率创新写进硬件
K2 Thinking在效率上的提升,与原生INT4量化能力紧密相关。
如何理解原生INT4量化?
让大模型更有效率,现行实践的思路很简单,就是把近万亿参数的数值变得小一点,以此降低计算量——这个把参数变小的过程就是量化。举例,5×4、5.3876×4.2367、56145.1×78456.5,哪个计算更简单?
但是量化会带来精度的极大损失。把一个5.3876的参数变小为5会损失小数点后的精度,而把一个56145.1的参数变小为5,更会导致数量级上的精度损失,最终会影响到模型的精度,而这是不能接受的。
因此,如何把参数变小(量化)又同时不损失模型的精度,是所有大模型工程师们追求的目标。
主流大模型如GPT-5、Claude量化的方法为PTQ(Post-training quantization),也就是先把大模型的参数算出来,再让所有参数变小。把原本是32位的浮点数(FP32)的参数,变为16位的浮点数(FP16)甚至是变为8位的整数(INT8)。PTQ这种先把参数算完再变小的方法会导致较大的模型精度损失,一般会达到3-5%。
FP16是目前最流行的量化方法,因此,英伟达最好的AI芯片也针对16位浮点数做了硬件适配算法的优化。FP16的量化方法是现行的行业标准,你要用别的方法,连硬件都不能最优适配。
K2 Thinking量化的颠覆式创新体现在直接把参数大小缩小到4字符位整数,也就是4个位置的01,一共最多可表示16个数。这在参数精度上的损失上几乎是灾难性的,因此传统的PTQ肯定不适用。工程师使用了QAT方法(Quantization-aware Training),也就是模型在参数训练的时候就提前知道参数的大小只能压缩到最多16个整数,把量化前置进了模型的参数训练中。
把INT4做好,不是单纯的“把位数缩小”,而是要一整套算法(PTQ / GPTQ / AWQ / SmoothQuant / 非线性编码等)+工程(分层量化、分组量化、保留高精度层)+硬件适配。
K2 Thinking采用原生INT4量化后,工程师们的坚持换来了收获,且所见即所得,测试成绩等于实际部署性能,消除实验室与生产环境的性能落差。
INT4量化是 K2 Thinking对行业很有启发性的技术。按照官方信息,它解决了大模型长链条推理在量化后容易“逻辑崩溃”的业界难题,实现了在几乎不损失精度的情况下,推理速度提升2倍,显存占用大幅降低。
负责INT4量化的Kimi工程师刘少伟,在知乎上分享:在LLM的语境下,量化并非传统的“牺牲精度换速度”,原生的低比特量化在param-scaling+test-time-scaling的持续演进下,会成为大模型训练的一个标准范式。
当然,在客户的实际应用或者链条更长且复杂的推理中,是否能真的做到“测试成绩等于实际部署性能”,这种精度处理是否会影响任务的结果和成功率,仍有待更多的市场检验。

智能体长程管理:
最会用工具的大模型
19世纪著名历史学家托马斯·卡莱尔(Thomas Carlyle)有一个经典的论断:”人是使用工具的动物。没有工具,他一无是处;有了工具,他无所不能。”
会高效的使用工具一直都是衡量人类智能的重要标准之一。在大模型追赶“类人”智能的过程中,工具调用能力是各家大模型厂商的必争之地。
大多数现有大模型在调用外部工具或API时,会受限于“连续调用长度”和“上下文管理”,调用往往局限在5-20次内,且易因上下文丢失或逻辑混乱而中断。K2 Thinking将上限提升至200-300次,并保持全程无需人工干预,这不仅是数量级提升,更是系统鲁棒性的质变。其底层依赖:
交替思考机制:在”思考-执行”间循环,每轮调用都基于前序结果重新推理;
工程稳定性:15.5万亿token训练中实现”零loss spike”,确保长程任务不崩溃;
Test-Time Scaling:通过扩展思考token和调用轮次,实现推理深度的动态增强。
K2 Thinking所展示的工具调用能力已经可以让模型从”被动响应”到”主动求解”,具备类似人类”研究式工作流”的特性:1、自主任务拆解:将模糊问题分解为数十个子任务,持续验证假设、修正路径;2、错误自愈:在数百步交互中处理异常,通过多轮调用自我纠错;3、端到端交付:如网友实测中,模型可独立完成”三维模拟动画生成”这类需几十次工具配合的创造性任务
TAU-Bench是智能体能力测试的黄金标准,是第一个把”AI能不能当数字员工”这件事量化的基准。它不关心模型能背多少知识,只关心你交代一件事,它能不能不犯错、不偷懒、不绕路地干完。
Kimi K2 Thinking在TAU-Bench测试中以78.3分登顶,超过GPT-5(72.1)和Claude 4.5(69.8)。
K2 Thinking定义了智能体调用的一种有效行业标准。
工程师将K2 Thinking模型的长链思考和工具调用情况完全向用户公开。这种透明的交互方式意味着大模型的思考“黑箱”正在向用户打开,同时,模型工具调用的反馈将不仅来自于模型自身,甚至是用户的真实反馈,增加了模型智能进化的想象空间。
当资金羸弱,当AI巨头以数十万卡筑墙,月之暗面200多人的团队用K2 Thinking撕开了一道裂缝——真正的创新,从不应只依赖于资源的堆砌和垄断,亦可生长在无路可退时的极致专注。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

