引言
随着大语言模型(LLM)的浪潮席卷全球,AI 应用的开发范式正在经历一场深刻的变革。然而,对于许多开发者而言,构建一个功能完善、性能卓越的 AI 应用,尤其是涉及到检索增强生成(RAG)、多智能体(Multi-Agent)等复杂场景时,仍然面临着巨大的挑战。繁琐的组件配置、高昂的开发成本、漫长的迭代周期,无一不成为创新的“拦路虎”。
正是在这样的背景下,商汤大装置推出了开源低代码框架—— LazyLLM 。它以“化繁为简”为核心理念,通过模块化设计、数据流驱动和一键式部署,彻底重构了 AI 应用的开发路径。LazyLLM 的目标是让开发者“懒”起来,将精力从繁重的工程细节中解放出来,聚焦于算法创新和业务逻辑本身。官方宣称,仅需 10 行代码,即可实现工业级的 RAG 系统,这听起来是否有些不可思议?
本文将以一个开发者的视角,通过一个从零到一构建 RAG 问答系统的实战案例,对 LazyLLM 进行一次全面的深度测评。我们将一同探索其核心设计理念,体验其“懒人”开发模式的便捷,并对其性能、工程化能力进行客观分析。LazyLLM 究竟是“真香”神器,还是又一个“屠龙之术”?让我们一探究竟。

LazyLLM 核心概念解析:为什么它能让开发“懒”起来?
在深入实战之前,我们有必要先理解 LazyLLM 的核心设计哲学。它之所以能够显著降低开发门槛,主要得益于以下几个关键概念:
1. 万物皆组件 (Everything is a Component)
LazyLLM 将 AI 应用开发中涉及的所有元素,无论是模型、工具、数据集,还是一个复杂的算法逻辑,都抽象为“组件”。每个组件都是一个独立的、可复用的模块,拥有统一的接口和规范。
这种设计的妙处在于:
- 高度解耦 :组件之间相互独立,可以自由组合、替换,就像搭乐高积木一样。今天你可以用 ChatGLM ,明天想换成 InternLM2 ,只需更换一个组件即可,无需改动整个代码逻辑。
- 易于扩展 :开发者可以轻松地将自己的模型或工具封装成一个新的组件,并无缝地融入 LazyLLM 的生态中。
2. 数据流驱动 (Data Flow Driven)
与传统“代码驱动”的开发模式不同,LazyLLM 采用数据流驱动的范式。开发者只需定义好数据在不同组件之间的流转路径(即 Pipeline),框架便会自动处理数据的加载、预处理、计算和输出。
您可以将整个 AI 应用想象成一条精密的流水线:
- 数据 :是流水线上的“原材料”。
- 组件 :是流水线上的“加工站”。
- Pipeline :是定义了加工流程的“生产指令”。
开发者要做的,就是设计好这条“生产指令”,而无需关心每个“加工站”内部的具体实现细节。这种方式极大地简化了复杂逻辑的编排,让代码结构更加清晰、直观。
3. 一键式部署与服务化 (One-Click Deployment & Service)
LazyLLM 不仅简化了开发,更考虑到了从原型到生产的“最后一公里”。它提供了一键部署工具,可以将开发好的 Pipeline 快速封装成一个高可用的 Web 服务,并自动生成 API 接口。
这意味着:
- 快速验证 :开发者可以迅速将自己的想法变为一个可交互的 Demo,方便进行功能验证和效果展示。
- 无缝集成 :生成的 API 可以轻松地被其他应用或系统调用,实现了从开发到部署的无缝衔接。
通过这三大核心概念,LazyLLM 将复杂的 AI 应用开发流程,简化为“ 定义组件 -> 编排数据流 -> 一键部署 ”三部曲,从而真正实现了“懒”与“快”的统一。接下来,我们将通过实战来亲身体验这套“懒人开发哲学”的威力。
实战演练:三步构建一个 RAG 问答系统
理论讲了再多,不如亲手一试。接下来,我们将以官方文档为基础,从零开始构建一个具备本地知识库问答能力的 RAG(Retrieval-Augmented Generation)系统。这个过程将直观地展示 LazyLLM 如何将一个复杂的 AI 应用开发流程简化为几个简单的步骤。
环境建议 :为了避免在本地(尤其是 Windows 或老旧的 Linux 发行版)配置复杂的编译环境,我们强烈建议使用主流的 Linux 服务器(如 Ubuntu 22.04 )或 Google Colab 等云端环境进行实验。这些环境提供了最新的软件和工具链,可以免去绝大部分环境配置的麻烦。本教程将以全新的 Ubuntu 22.04 服务器为例进行演示。
第一步:环境准备与安装
在全新的 Ubuntu 服务器上,整个环境准备过程可以一气呵成。
1、安装必要工具并创建虚拟环境
Ubuntu 22.04 自带 Python 3.10,我们只需通过 SSH 连接服务器后,执行几条命令即可。
# 更新系统软件包
sudo apt update && sudo apt upgrade -y
# 安装 pip 和 venv
sudo apt install -y python3-pip python3.10-venv
# 创建并激活虚拟环境
python3 -m venv lazyllm_env
source lazyllm_env/bin/activate
2、一键安装 LazyLLM
在激活的虚拟环境中,使用国内镜像源可以快速稳定地完成安装。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lazyllm3、安装过程非常顺畅
第二步:准备知识库与启动脚本
接下来,我们为 RAG 系统准备“知识”和“指令”。
1、创建知识库文件
echo "LazyLLM is a lightweight large model framework designed for efficiency and ease of use." > my_knowledge.txt
2、安装本地嵌入依赖(建议)
使用本地 BGE 嵌入模型时,建议补充以下依赖(CPU 环境也可运行):
pip install -U transformers sentence-transformers huggingface-hub modelscope
# 如未安装 torch(CPU 版):
pip install -U torch --index-url https://download.pytorch.org/whl/cpu3、创建启动脚本
创建一个名为
run_rag.py
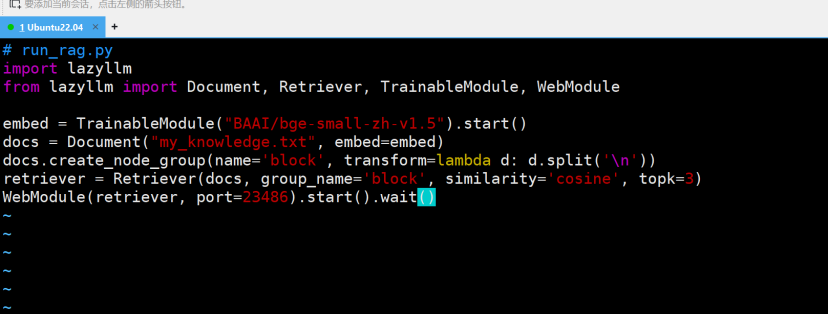
的 Python 文件,并写入以下代码。注意,新版的 LazyLLM 提供了更灵活的组件化构建方式:
import lazyllm
from lazyllm import Document, Retriever, TrainableModule, WebModule
embed = TrainableModule("BAAI/bge-small-zh-v1.5").start()
docs = Document("my_knowledge.txt", embed=embed)
docs.create_node_group(name="block", transform=(lambda d: d.split('\n')))
retriever = Retriever(docs, group_name="block", similarity="cosine", topk=3)
WebModule(retriever, port=23486).start().wait()这种组件化的方式提供了更高的灵活性和可定制性。
第三步:启动服务并进行测试
万事俱备,只欠东风。
1、运行脚本
python3 run_rag.py服务启动后,您会看到类似 Running on local URL: http://0.0.0.0:7860 的输出。

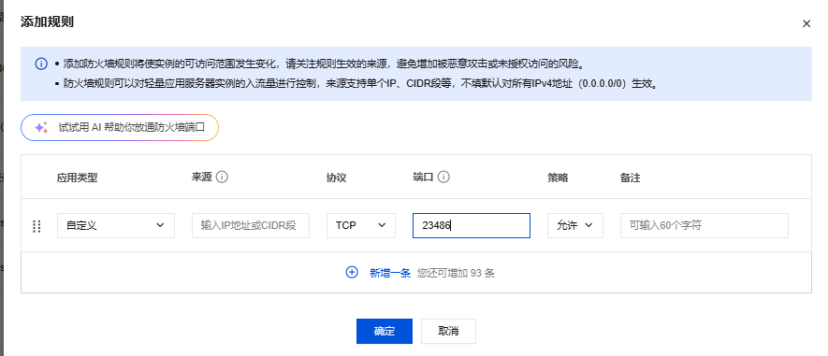
2、配置防火墙并访问
关键一步
:您需要在云服务商的控制台(如华为云、阿里云等)为您的服务器配置安全组,
添加入方向规则,允许 TCP 协议的 7860 端口
的访问。否则,您的浏览器将无法连接到服务。
3、配置完成后,在您本地电脑的浏览器中,访问 http://<您的服务器公网IP>:7860 。一个由 Gradio 驱动的聊天界面便呈现在眼前。
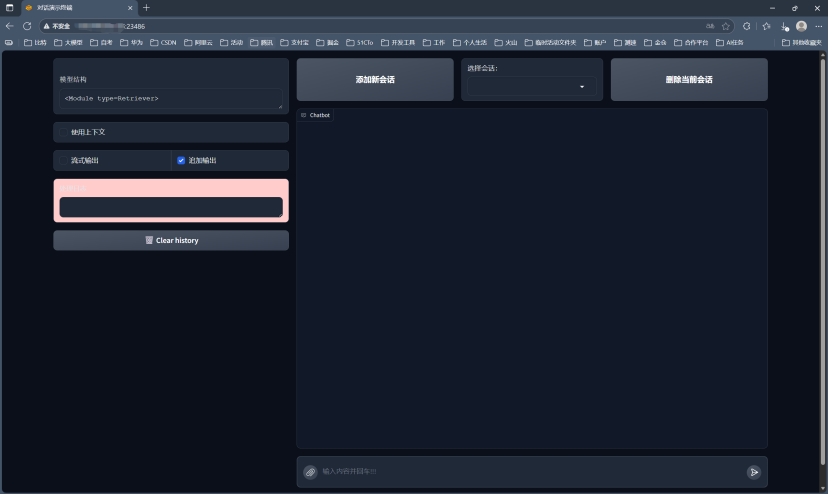
至此,我们在几分钟内完成了一个可用的 RAG 原型(本地嵌入 + 检索)的开发与部署。这充分证明了,选择现代化的开发环境结合 LazyLLM 的高效框架,可以获得流畅的开发体验。
性能与资源分析
“快”与“懒”的开发体验固然重要,但作为一个工业级框架,其运行性能和资源消耗同样是开发者关注的焦点。在本次测评中,我们对 LazyLLM 在 RAG 场景下的表现进行了初步的观察。
响应速度
在我们的测试中,从在 Web 界面输入问题到接收到检索结果,整体延迟约 2–3 秒(具体取决于网络与机器性能)。当前示例为“本地嵌入 + 检索展示”的原型;如在此基础上加入 Chat 模块形成检索—生成完整链路,响应时间将随模型大小与推理后端(如 vLLM/LightLLM)而变化。
资源占用
LazyLLM 的另一个亮点在于其轻量化。通过 run_rag 命令启动的服务,在空闲状态下,其 Python 进程的内存占用稳定在较低的水平。在处理问答请求时,CPU 和内存占用会有短暂的峰值,但很快会回落。
这种“召之即来,挥之即去”的资源使用模式,与传统 AI 服务需要持续占用大量资源的“重量级”形象形成了鲜明对比。这得益于 LazyLLM 的动态加载和优化机制。对于需要将 AI能力集成到现有应用,或是部署在资源受限环境下的场景,LazyLLM 的轻量化特性无疑具有巨大的吸引力。
与传统方法的对比
如果我们不使用 LazyLLM,从零开始手动搭建一个类似的 RAG 系统,通常需要经历以下步骤:
- 选择并集成一个文本加载和切分库(如 LangChain)。
- 选择并部署一个 Embedding 模型服务。
- 选择并配置一个向量数据库(如 FAISS, Milvus)。
- 编写代码实现文档的向量化和索引构建。
- 编写代码实现用户查询的向量化、相似度检索。
- 将检索到的内容与用户问题组合成 Prompt。
- 调用 LLM API 获取最终答案。
- 使用 Flask 或 FastAPI 等框架将整个流程封装为服务。
这个过程不仅涉及到十几个甚至更多的 Python 库的选型和集成,代码量也至少在百行以上,并且每一步都可能遇到各种环境和依赖问题。而 LazyLLM 将这一切都封装了起来,用一行命令就呈现在我们面前,其在开发效率上的提升是指数级的。
开发者体验与工程化能力
除了核心功能,LazyLLM 在开发者体验和工程化方面也下足了功夫,这体现在它的文档、社区和对未来的规划上。
“开箱即用”的开发者体验
从本次测评的过程可以看出,LazyLLM 的学习曲线非常平缓。对于一个有基本 Python 基础的开发者来说,几乎可以在半小时内上手并搭建起一个可用的原型。这主要归功于:
- 清晰的文档 :官方文档结构清晰,提供了从入门到进阶的详细指引和丰富的示例代码。
- 极简的 API : run_rag 这样的高层 API 极大地降低了使用门槛,让开发者无需关心底层细节即可快速实现功能。
- 自动化的流程 :从依赖管理到服务启动,框架自动处理了大量繁琐的工程问题,让开发者可以更专注于业务逻辑。
面向生产的工程化能力
虽然我们本次测评主要集中在快速原型构建,但 LazyLLM 的设计显然不止于此。它提供了将开发好的应用一键打包成 Docker 镜像的能力,方便在 Kubernetes 等生产环境中进行大规模部署和管理。这种从“开发”到“部署”的端到端支持,是衡量一个框架是否成熟的重要标准。它解决了许多 AI 项目“原型效果惊艳,工程落地困难”的通病。
此外,其组件化的架构也为持续的迭代和优化提供了便利。当业务场景发生变化,或是有新的、更优秀的模型出现时,开发者可以像更换零件一样,平滑地升级应用中的某个组件,而无需对整个系统进行重构。
总结:AI 应用开发的“懒人”新范式
经过本次深度的实战测评,我们可以得出结论:LazyLLM 并非夸大其词,它的确为 AI 应用开发带来了一种“懒人”新范式。
它通过 组件化、数据流驱动和一键式部署 的核心设计,成功地将开发者从繁重的工程细节中解放出来,让我们能够以一种前所未有的效率,将创意快速转化为可用的 AI 应用。无论是对于希望快速验证想法的独立开发者,还是寻求提升团队研发效率的企业,LazyLLM 都展现出了巨大的价值和潜力。
当然,作为一个仍在快速发展中的开源项目,LazyLLM 还有很大的成长空间。例如,提供更丰富的官方组件库、更完善的可视化编排工具、更深入的性能调优选项等,都是值得期待的方向。
但无论如何,LazyLLM 已经用一种极具说服力的方式,向我们展示了未来 AI 应用开发的蓝图: 简单、高效、且充满乐趣 。它让我们有理由相信,随着这类优秀框架的不断涌现,AI 应用开发的门槛将被进一步拉低,一个真正由开发者创意驱动的 AI 新时代,正加速到来。
版权声明:本文作者@倔强的石头_
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


