
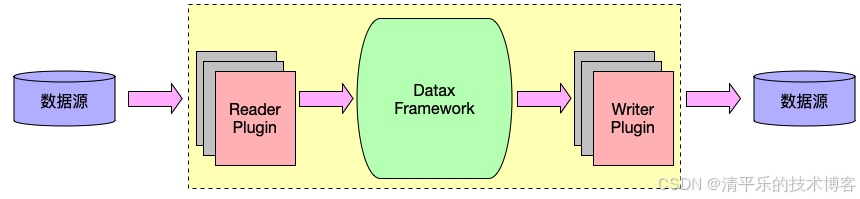
<p>Apache SeaTunnel 相较于 DataX、Flink CDC、Talend 等主流数据集成工具,在性能、部署易用性、多场景适配性等多个维度都具备显著优势。博主分别结合不同工具做了以下对比分析。</p> 一、对比 DataX
1、性能远超且资源更省
DataX 仅支持单机部署,易受网络、数据源波动影响,且同步速度有限。而 SeaTunnel 在相同测试场景下比 DataX 快 40%-80%,其 JDBC 连接器采用连接复用、动态分片技术,Zeta 引擎还实现动态线程共享,能减少资源消耗。例如在 8C32G 服务器的同库 JDBC 同步测试中,SeaTunnel 速率平均比基于类似技术的第三方平台快近两万条每秒。同时 SeaTunnel 支持集群部署,可通过并行读写进一步提升海量数据处理能力,避免了 DataX 单机的性能瓶颈。
2、批流一体更适配复杂场景
DataX 侧重离线数据同步,若需实现实时同步,需额外搭配其他工具。 SeaTunnel 则打破离线与实时的壁垒,基于其 Connector API 开发的组件可兼容全量、增量、CDC 等多种场景,无需为不同同步需求拆分开发任务,大幅降低管理难度。
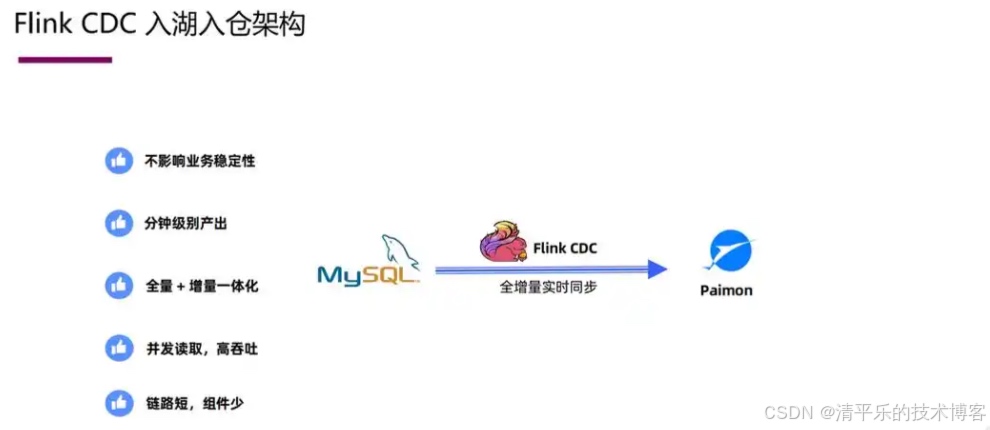
二、对比 Flink CDC
1、数据源兼容性更广
Flink CDC 聚焦于基于 Flink 引擎的变更数据捕获场景,连接器主要围绕数据库 CDC 展开,适配的数据源类型有限。SeaTunnel 支持超 100 个连接器,除主流数据库外,还涵盖分布式文件系统、消息队列、SaaS 服务等,能对接 HDFS、Kafka、Elasticsearch 等多种存储和中间件,可满足企业多源异构数据的集成需求。
2、引擎灵活且无强依赖
Flink CDC 强绑定 Flink 引擎,企业使用时需维护 Flink 集群,技术栈单一且升级成本高。SeaTunnel 默认使用自研 Zeta 引擎,也可适配 Flink、Spark 等引擎,无需强制依赖某一特定引擎。对于已有 Spark 集群的企业,无需重构架构即可集成 SeaTunnel,显著降低适配成本。
三、对比 Talend
1、架构轻量化且易维护
Talend 常需搭配多个组件才能完成复杂数据集成链路,如曾有客户用 Talend 抽取 SAP 数据时,需配合 Hudi、EMR、Hive 等组件,不仅部署流程繁琐,还对开发人员技术水平要求高。 而 SeaTunnel 无需依赖过多额外组件,支持单机和集群两种灵活部署模式,无中心化设计可按需调整 Master 和 Worker 节点角色,中小规模场景可快速部署落地,运维成本大幅降低。
2、适配性更强且易用性高
Talend 使用复杂,且对部分数据源版本支持不足,比如仅支持 SAP Hana 6.2,对 7.3 版本适配效果差。SeaTunnel 采用插件化架构,用户可通过 Connector API 自定义插件,适配自研数据源或特殊版本数据源。同时它支持 YAML 配置文件和 SeaTunnel Web 可视化开发,无需复杂编码,相比 Talend 降低了开发和使用门槛。
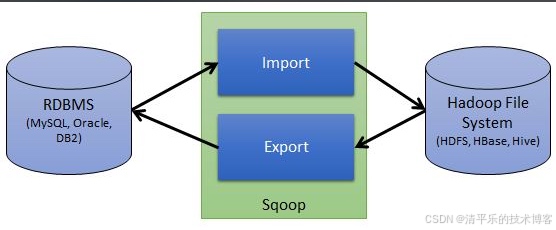
四、对比 Sqoop
1、场景覆盖更全面
Sqoop 主要用于传统关系型数据库与 Hadoop 之间的离线数据传输,不支持实时同步和 CDC 等主流场景,且连接器种类较少。SeaTunnel 不仅能完成离线数据向数据仓库的同步,还能支撑实时日志写入、全库同步等场景,比如将 Kafka 中的实时日志同步到 ClickHouse,适配企业从离线分析到实时监控的多样化需求。
2、数据一致性保障更完善
Sqoop 在面对节点故障等异常时,缺乏成熟的断点续传机制,易出现数据丢失或重复。 SeaTunnel 支持分布式快照算法和 Checkpoint 机制,即使集群节点全部宕机,开启 IMAP 持久化后重启集群可自动恢复任务,能有效保障数据同步过程中的一致性。
原文链接:https://blog.csdn.net/ZZQHELLO2018/article/details/155199279
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


