语义嵌入模型
语义嵌入背后的思想是, AI 模型可以学会用高维空间的几何关系来表示其输入含义的各个方面。
你可以将一个语义嵌入看作是高维空间中的一个点(技术上称为向量)。 嵌入模型 是一种神经网络,它接收一些数字数据作为输入(理论上可以是任何数据,但最常见的是文本或图像),并以一组数值坐标的形式输出对应的高维点位置。如果模型表现良好,两个语义嵌入之间的距离就与它们各自对应的数字对象在语义上有多相似成正比。
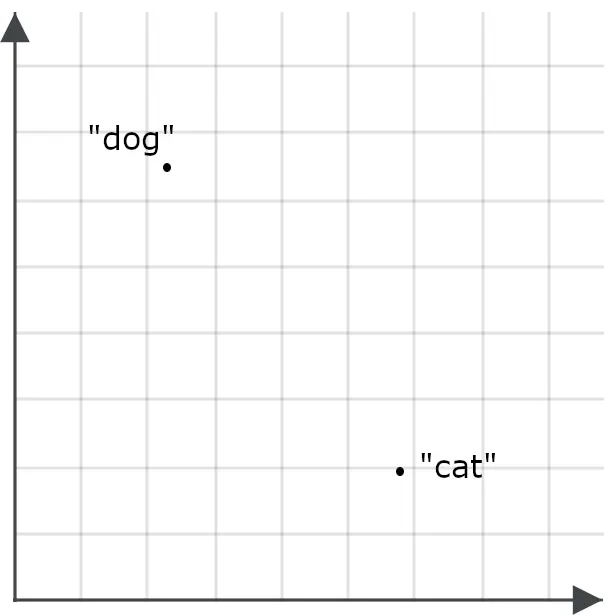
为了理解这对搜索应用为何重要,可以想象单词 “ dog ” 和单词 “ cat ” 各自对应为空间中的两个点:


多模态嵌入
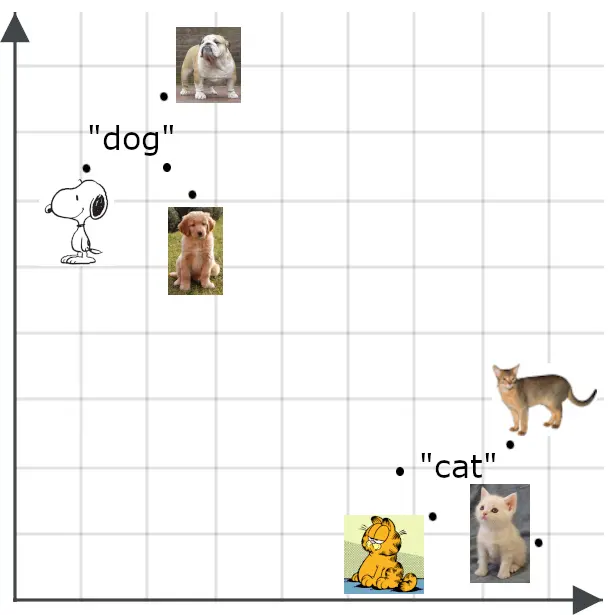
多模态模型将语义嵌入的概念扩展到文本之外,尤其是图像。我们会期望一张图片的嵌入与对该图片的准确描述的嵌入彼此接近:
Matryoshka(套娃) 表示学习
嵌入的维度数量以及其中数值的精度会对性能产生显著影响。非常高维的空间和极高精度的数值可以表示高度细致和复杂的信息,但需要更大、训练和运行成本更高的 AI 模型。它们生成的向量需要更多存储空间,计算向量之间距离也需要更多计算资源。使用语义嵌入模型需要在精度和资源消耗之间做出重要权衡。
非对称检索
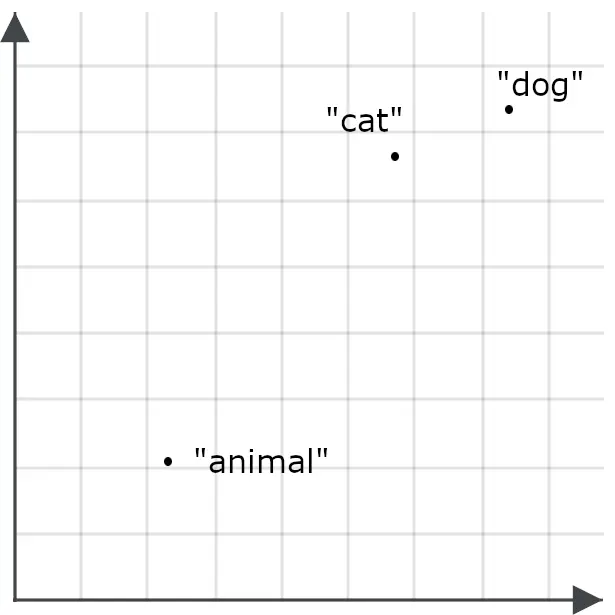
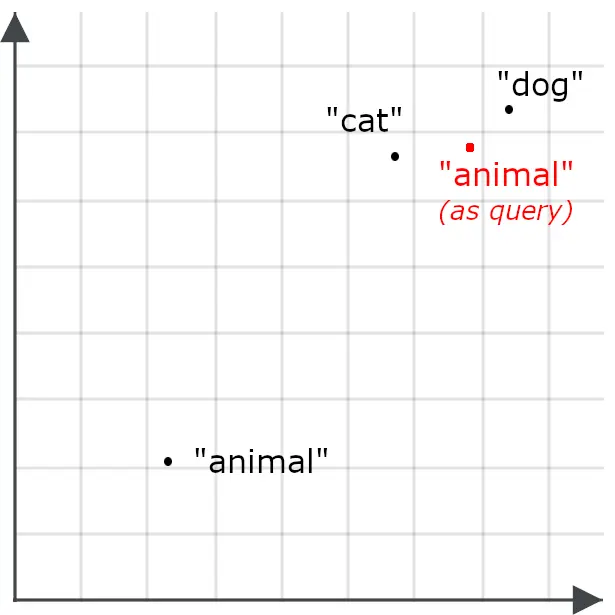
语义相似度通常是对称测量的。比较 “ cat ” 和 “ dog ” 得到的值,与比较 “ dog ” 和 “ cat ” 得到的值是相同的。但在使用嵌入进行信息检索时,如果打破对称性,将查询的编码方式与检索对象的编码方式区分开,会效果更好。
多向量嵌入
单一嵌入适用于信息检索,因为它们符合索引数据库的基本框架:我们使用单个嵌入向量作为检索键存储可检索对象。当用户查询文档存储时,查询会被转换为嵌入向量,文档中键与查询嵌入在高维嵌入空间中最接近的文档会被检索出来作为候选匹配。
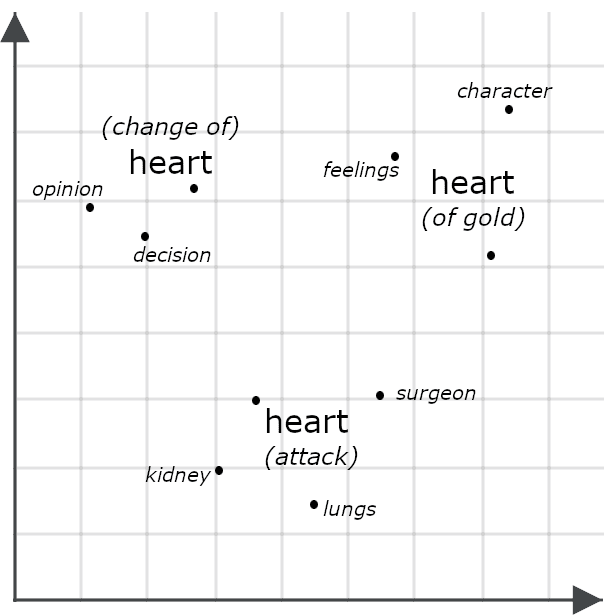
-
She had a heart of gold.
-
She had a change of heart.
-
She had a heart attack.
Jina 嵌入模型
Jina embeddings v4
-
在视觉文档检索上表现出最先进的性能,同时在多语言文本和常规图像处理上也超过了更大型的模型。
-
支持大输入上下文:32,768 个 token 大约相当于 80 页双倍行距的英文文本,20 兆像素相当于 4,500 x 4,500 像素的图像。
-
用户可选择嵌入维度,从最大 2048 维到最小 128 维。实证发现,低于该阈值性能会显著下降。
-
支持单向量嵌入和多向量嵌入。文本的多向量输出为每个输入 token 生成一个 128 维嵌入;图像的多向量输出为覆盖图像所需的每个 28×28 像素块生成一个 128 维嵌入。
-
通过专门训练的一对 LoRA 适配器优化非对称检索。
-
优化语义相似度计算的 LoRA 适配器。
-
专门支持编程语言和 IT 框架,也通过 LoRA 适配器实现。
Jina embeddings v3
jina-embeddings-v3 是一个紧凑、高性能、多语言、仅文本的嵌入模型,参数少于 6 亿。它支持最多 8192 个 token 的文本输入,并输出单向量嵌入,嵌入维度可由用户选择,从默认的 1024 维到最小 64 维。
-
非对称检索
-
语义相似度
-
分类
-
聚类
Jina 代码嵌入
Jina 的专用代码嵌入模型 —— jina-code-embeddings(0.5b 和 1.5b)——支持 15 种编程语言和框架,以及与计算机和信息技术相关的 English 文本。它们是紧凑模型,参数分别为 5 亿(0.5×10⁹)和 15 亿(1.5×10⁹)。两个模型都支持最多 32,768 个 token 的输入上下文,并允许用户选择输出嵌入维度:小模型为 896 到 64 维,大模型为 1536 到 128 维。
-
代码到代码( Code to code ):跨编程语言检索相似代码,用于代码对齐、代码去重,以及支持移植和重构。
-
自然语言到代码( Natural language to code ):根据自然语言查询、注释、描述和文档检索匹配代码。
-
代码到自然语言( Code to natural language ):将代码匹配到文档或其他自然语言文本。
-
代码补全( Code-to-code completion ):建议相关代码以完成或增强现有代码。
-
技术问答( Technical Q&A ):识别与信息技术相关问题的自然语言答案,非常适合技术支持场景。
Jina ColBERT v2
jina-colbert-v2是一个拥有 5.6 亿参数的多向量文本嵌入模型。它是多语言模型,使用 89 种语言的材料进行训练,并支持可变嵌入维度和非对称检索。
Jina CLIP v2
jina-clip-v2是一个拥有 9 亿参数的多模态嵌入模型,训练目标是让文本和图像在嵌入空间中彼此接近,如果文本描述了图像的内容。它的主要用途是基于文本查询检索图像,但它也是一个高性能的纯文本模型,从而降低用户成本,因为无需为文本到文本和文本到图像的检索使用不同模型。
重排序模型
重排序模型会将一个或多个候选匹配项与查询一起作为模型输入,并直接进行比较,从而生成精度更高的匹配结果。
Jina 重排序模型
Jina Reranker m0
jina-reranker-m0 是一个拥有 24 亿(2.4×10⁹)参数的多模态重排序模型,支持文本查询和由文本和/或图像组成的候选匹配。它是视觉文档检索的领先模型,非常适合用于存储 PDF、文本扫描、截图以及其他包含文本或半结构化信息的计算机生成或修改的图像,也适用于由文本文档和图像混合组成的数据。
Jina Reranker v3
jina-reranker-v3 是一个拥有 6 亿参数的文本重排序模型,在同等规模模型中性能处于最先进水平。与 jina-reranker-m0 不同,它接受单个查询和最多 64 个候选匹配的列表,并返回排序顺序。它的输入上下文为 131,000 个 token,包括查询和所有文本候选。
Jina Reranker v2
jina-reranker-v2-base-multilingual 是一个非常紧凑的通用重排序模型,具有额外功能以支持函数调用和 SQL 查询。参数少于 3 亿,提供快速、高效且准确的多语言文本重排序,并额外支持选择与文本查询匹配的 SQL 表和外部函数,非常适合 agentic 场景使用。
小型生成语言模型
生成语言模型是指像 OpenAI 的 ChatGPT、Google Gemini 以及 Anthropic 的 Claude 这样的模型,它们接受文本或多媒体输入,并输出文本。大语言模型(arge language models – LLMs)与小语言模型(small language models – SLMs)之间没有明确界限,但开发、运行和使用顶级 LLM 的实际问题是众所周知的。最知名的 LLM 并未公开分发,因此只能估计其规模,但 ChatGPT、Gemini 和 Claude 预计在 1–3 万亿(1–3×10¹²)参数范围内。
Jina SLMs
ReaderLM v2
ReaderLM-v2 是一个生成语言模型,可根据用户提供的 JSON schema 和自然语言指令,将 HTML 转换为 Markdown 或 JSON。
Jina VLM
jina-vlm 是一个拥有 24 亿(2.4×10⁹)参数的生成语言模型,训练目标是回答关于图像的自然语言问题。它在视觉文档分析方面表现非常强大,即回答关于扫描件、截图、幻灯片、图解以及类似的非自然图像数据的问题。

 图片来源: Wikimedia Commons 用户 Vauxford。
图片来源: Wikimedia Commons 用户 Vauxford。
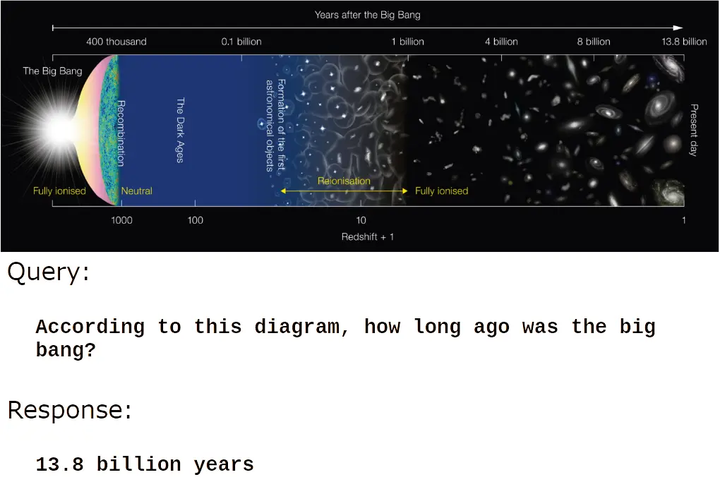
 图片来源: Wikimedia Commons。
图片来源: Wikimedia Commons。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


