学术会议ICLR,居然和美光和西部数据大跌扯上关系了?
两家存储芯片巨头股价大跌,没有财报暴雷,没有供应链断裂,只是谷歌展示了一篇即将在ICLR 2026正式亮相的论文。
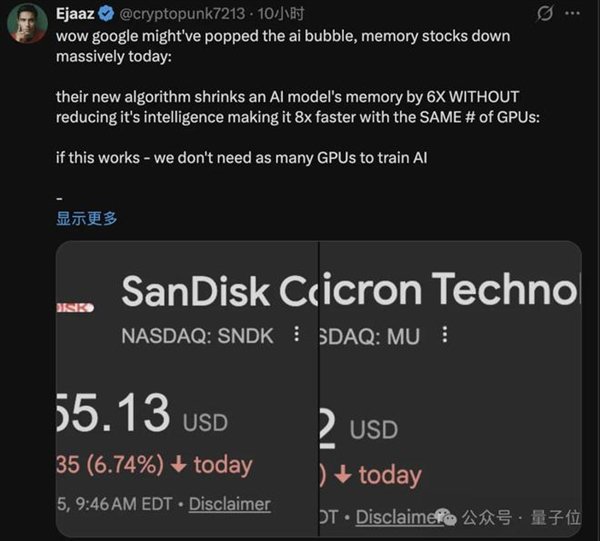
谷歌研究院推出TurboQuant压缩算法,把AI推理过程中最吃内存的KV cache压缩至少6倍,精度零损失
市场的解读简单粗暴,长上下文AI推理以后不需要那么多内存了,利空内存。

网友纷纷表示,这不就是美剧《硅谷》里的Pied Paper?
Pied Piper是2014年开播的HBO经典美剧《硅谷》里的虚构创业公司,核心技术就是一种“近乎无损的极限压缩算法”。
2026年,类似的算法在现实世界居然成真了。
KVCache量化到3 bit
要理解TurboQuant为什么重要,先得理解它解决的是什么问题。
AI大模型推理时处理过的信息会临时存在KV Cache,方便后续快速调用,不用每次从头算起。
问题是随着上下文窗口越来越长,内存消耗急剧膨胀。KV cache正在成为AI推理的核心瓶颈之一。
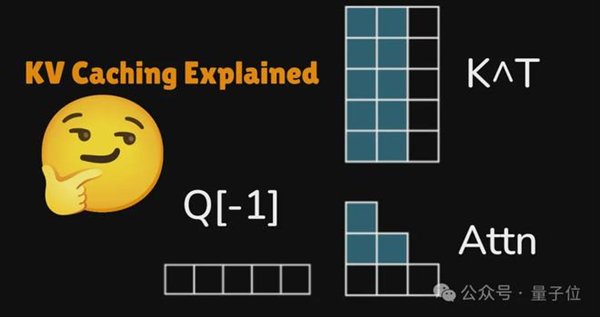
传统的解决思路是向量量化,把高精度数据压成低精度表示。
但尴尬的是,大部分量化方法本身也需要存储额外的“量化常数”,每个数字要多占1到2个bit。
TurboQuant用两个改动把这个额外开销干到了零。
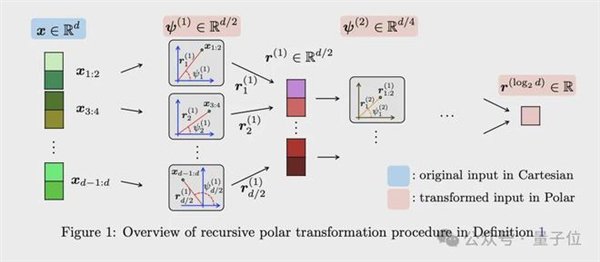
PolarQuant(极坐标量化):
不用传统的X、Y、Z坐标描述数据,转而用极坐标”距离+角度”。
谷歌团队发现,转换后角度的分布非常集中且可预测,根本不需要额外存储归一化常数。
就像把“往东走3个路口,往北走4个路口”压缩成”朝37度方向走5个路口”。
信息量不变,描述更紧凑,还省掉了坐标系本身的开销。
QJL(量化JL变换):
把高维数据投影后压缩成+1或-1的符号位,完全不需要额外内存。TurboQuant用它来消除PolarQuant压缩后残留的微小误差。
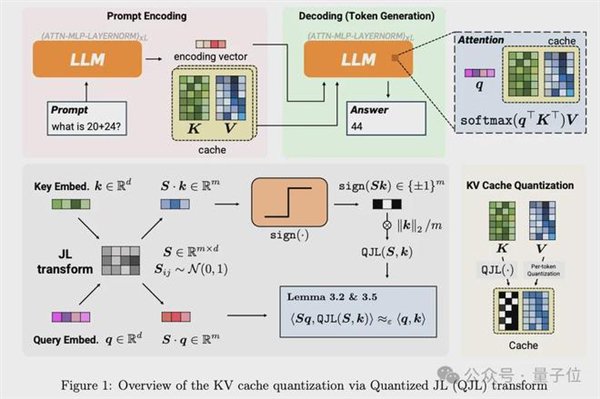
两者组合后PolarQuant先用大部分bit容量捕捉数据的主要信息,QJL再用1个bit做残差修正。
最终实现3-bit量化,无需任何训练或微调,精度零损失。
8倍加速,Benchmark全线拉满
谷歌团队在Gemma和Mistral等开源模型上,跑了主流长上下文基准测试,覆盖问答、代码生成、摘要等多种任务。
在“大海捞针”任务上,TurboQuant在所有测试中拿下完美分数,同时KV cache内存占用缩小了至少6倍。
PolarQuant单独使用,精度也几乎无损。
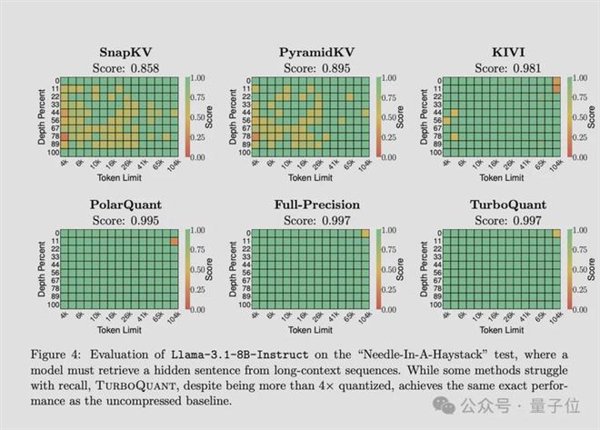
速度提升同样显著。在英伟达H100 GPU上,4-bit TurboQuant计算注意力分数的速度,比32-bit未量化版本快了8倍。
不只是省内存,还更快了。
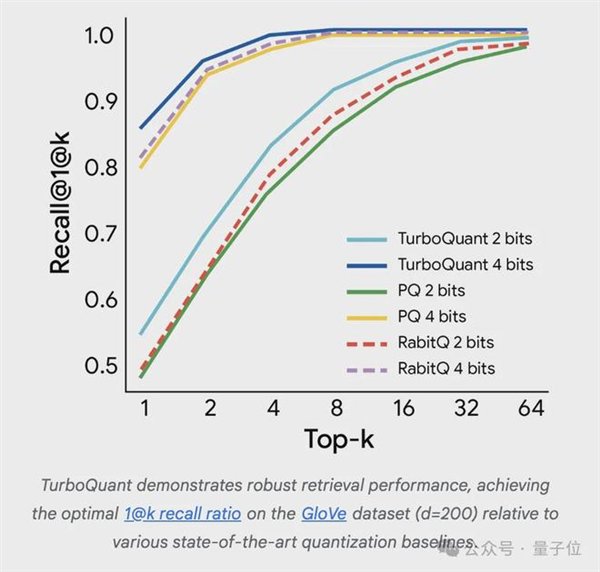
在向量搜索领域,TurboQuant同样超越了现有最优量化方法的召回率,而且不需要针对具体数据集做调优,也不依赖低效的大码本。
AI内存的DeepSeek时刻?
Cloudflare CEO评价“这是谷歌的DeepSeek时刻”。
他认为DeepSeek证明了用更少的资源也能训出顶尖模型。
TurboQuant的方向类似,用更少的内存,也能跑同样质量的推理。
谷歌表示,TurboQuant除了可以用在Gemini等大模型上,同时还能大幅提升语义搜索的效率,让谷歌级别的万亿级向量索引查询更快、成本更低。
不过TurboQuant目前还只是一个实验室成果,尚未大规模部署。
更关键的是,它只解决推理阶段的内存问题。而AI训练环节完全不受影响。
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
责任编辑:若风
文章内容举报
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

