大家好呀!这里是你们的课代表懒懒~不知不觉,我们已经来到课程的最后一节,为我们的坚持和努力点赞!
通过之前的学习,我们已经学会了如何使用RAG增强大模型的能力。有细心的小伙伴发现,传统的RAG在召回上存在碎片化的局限。为了解决传统RAG存在的问题, 知识图谱RAG 应运而生,本节课就让懒懒带大家回顾如何搭建知识图谱RAG吧!
知识图谱RAG,超越朴素RAG!
朴素RAG:😔
- 检索返回的内容孤立、缺乏结构关联。
- 回答在需要跨文档、跨段落推理的场景中,召回片段之间缺乏逻辑和语义连贯性。
- 无法识别文档间的主题关系,信息冗余与漏召。
知识图谱RAG:😊
- 实体-关系-属性的三元组形式显式建模语义关联,使系统能够清晰刻画知识之间的语义路径。
- 在图谱上进行结构感知的检索或路径遍历,更有针对性地召回与用户问题语义相关、逻辑连贯的信息。
- 跨文档实体的对齐与融合,增强主题聚合与复杂推理能力。
知识图谱:让机器理解世界的“知识网络”
一切从图说起 🔥

(图(Graph)结构)
图是一种由一组节点(或称为顶点)和节点之间的边组成的数据结构,例如图1 可以表示地铁路线图,每个顶点表示一个站点,每个边表示站点之间的连通性。
知识图谱(Knowledge Graph, KG)是一种用 “图” 结构表示知识的方式,通常由三元组组成,其中每个三元组包含一个实体、关系以及与该实体相关的另一个实体,结构形式为 (实体1)—[关系]→(实体2)。
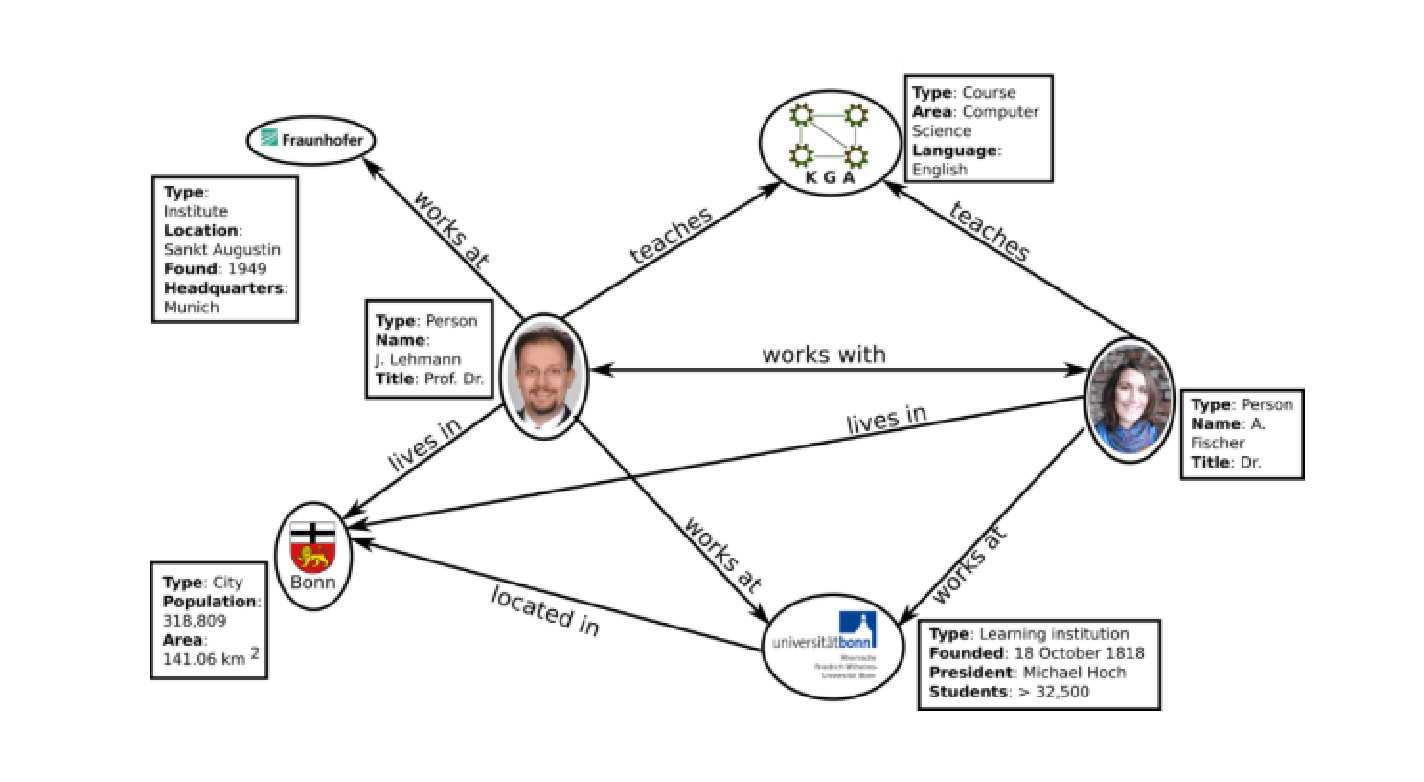
(知识图谱示例(图源网络))
知识图谱有三个重要组成部分,即实体,关系和属性,每个部分的解释如下:
- 实体(Entity):知识图谱的基本构成单位,代表现实世界中的物品、概念、事件等。例如图2中的每个人物、城市、课程都是实体。🤔
- 关系(Relationship):描述实体间联系的方式,通常用边来表示。比如图2中男士与Bonn的关系是“lives in”,表示这位男士生活在Bonn City。🤔
- 属性(Attribute):实体或关系的附加信息。例如图2中Bonn City有“Type”,“Population”和“Area”三个属性。🤔
从文档中构建知识图谱
拆解流程🔥
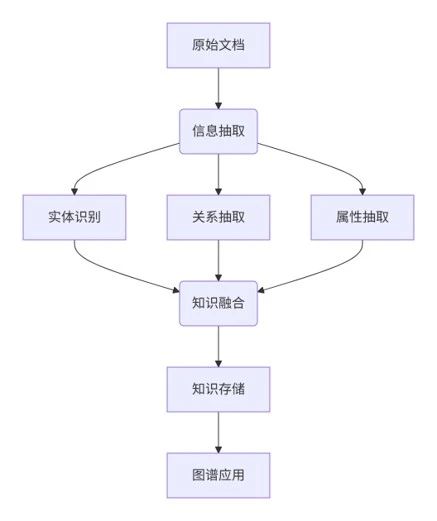
RAG系统的“智能外挂”:知识图谱如何赋能RAG?
构建知识图谱
要构建基于知识图谱的RAG系统,就像是在搭建一座“知识摩天楼”。
现成的结构化数据(比如数据库、RDF、Neo4j)就像预制好的砖块,拆开就能直接用,省时又省力。
而非结构化数据(比如那些长篇大论的文字)嘛,就像一堆散落的乐高零件,需要你仔细翻找,才能拼出点有用的东西,比如人名、地名、日期,以及它们之间的“小八卦”(比如“谁创办了什么”“谁住在哪儿”)。
怎么处理这些“碎片”呢?
可以采用传统的信息抽取方法,主要分两步:
- NER(命名实体识别):像一位“考古专家”,负责从文本中挖掘出关键的实体,例如人物、组织、地点等;
- 关系抽取:这位专家则专注于搞清楚实体之间的“人际关系”,比如“张三是某公司的创始人”。
当然,还有另一种更“现代”的做法——直接派出大型语言模型(LLM)这个“全能大工匠”。它能在一句话中同时识别实体、提取关系,甚至顺带润色输出,效率极高。
所以,搭建知识图谱就是这么一件“从零件到艺术品”的事情,有了这些工具,轻松又有趣!

图3 利用大模型构建知识图谱流程
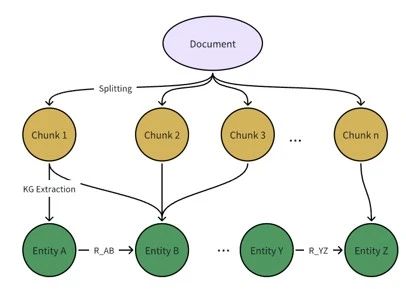
处理文本构建知识图谱就像拆书搭积木,步骤如下:
- 文本分块:先把长文本切成小块,方便操作,这步和普通RAG的“切片”手法一样。
- 提取图元素:用LLM发“指令”从每块文本里找出关键积木:
- 第一步:找实体(例如名字、类型、描述),就像从一堆零件里挑出有用的砖块。
- 第二步:找关系(谁和谁有啥联系,比如“合作”“位于”),把砖块之间的连接线画出来。
- 合并实体和关系:最后,把不同文本块中重复的积木合并,拼成一个完整、连贯的知识图谱!
简单来说,就是“切片-找积木-拼完整”,过程清晰又高效!😮
使用知识图谱召回
其流程如图所示:

(Knowledge Graph Based RAG 流程示例)
基于知识图谱的RAG系统回答过程有这样几个步骤!😮
- 检索阶段,根据用户输入问题从知识图谱中召回相关的实体、关系以及原文内容。
- 增强阶段,将召回的结构化结果整合为额外的上下文信息,与用户输入一起提供给大模型,以增强其理解和推理能力。
- 生成阶段,系统通过大模型生成答案,该过程与朴素RAG系统一致。
两大知识图谱RAG系统供你挑选
GraphRAG

GraphRAG通过构建知识图谱和分层社区结构,将局部信息聚合为全局理解。
其核心优势在于:
- 利用LLM从文档中提取实体、关系和事实声明构建知识图谱,通过图结构索引捕捉语义关联。
- 通过分层社区检测,使用图社区算法将图谱划分为紧密关联的社区,递归生成从局部到全局的摘要。
- 采用Map-Reduce式回答生成方法,借助社区摘要的并行处理与聚合,生成全面且多样的全局回答。
GraphRAG工作流程
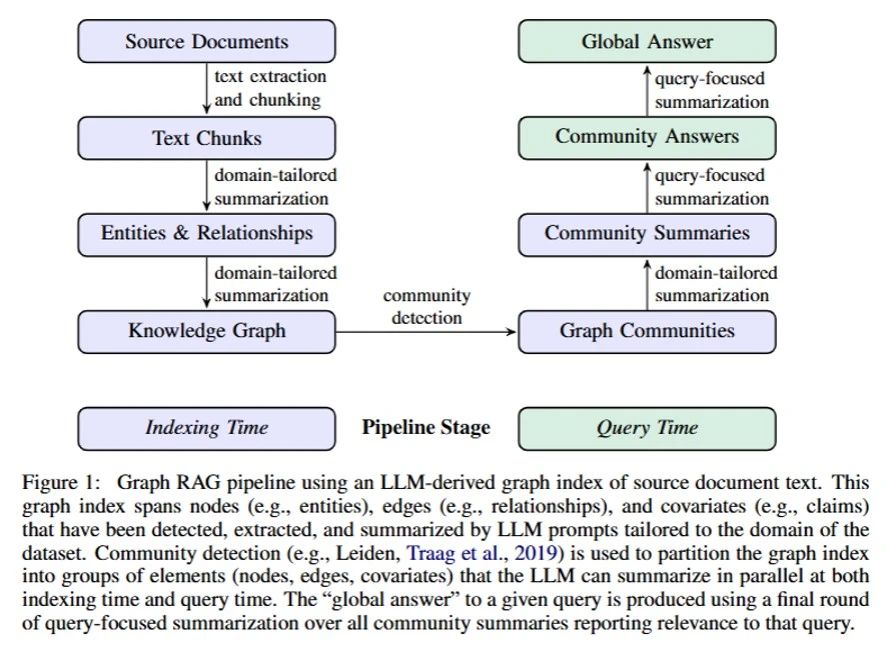
1.将文档拆分为文本块,并使用LLM提取其中的实体、关系及事实声明
2.基于提取结果构建知识图谱,将实体和关系转化为图节点和边,对重复实例进行聚合并生成节点描述,同时根据关系出现频率设定边的权重。
3.利用Leiden算法对图谱进行递归划分,形成嵌套的社区结构,每个社区代表一个语义主题,构建从局部到全局的层级结构。
社区新概念!
微软 GraphRAG 在知识图谱的基础上增加了一个社区(Community)的概念。

社区是 GraphRAG 中的高级结构,表示一组相关实体的集合。每个社区包含以下字段:
ID:社区的唯一标识符。
Level:社区的层级(如 0、1、2 等)。
Entity IDs:社区中包含的实体 ID 列表。
Relation IDs:社区中包含的关系 ID 列表。
Text Block IDs:社区中包含的文本块 ID 列表。
Description:社区的描述信息。
Summary:社区的摘要信息。
GraphRAG 在是构建Knowledge Graph后,增加了一个社区摘要(Community Summaries)的生成环节。这一策略使得系统在检索时只关注与查询高度相关的社区,而不是检索整个图。社区摘要对数据全局结构和语义的高度概括, 即使没有问题, 用户也可以通过浏览不同层次的社区摘要来理解语料库!
社区摘要生成由两步组成:
- 社区检测:使用图分析算法,获得具有高度连接性的实体簇
- 摘要提取:使用LLM根据社区中的实体和关系,提取各类型总结。

(微软 Graph RAG 的社区聚类效果图)
Light RAG
LightRAG的知识图谱是比较基础的 分片+实体/关系
LightRAG 就像一位“轻装上阵”的知识图谱专家,甩掉了复杂的社区聚类,直接构建知识图谱,支持增量更新——新数据只需补充节点和关系,无需重建全图,方便又高效!🧠
它的检索方式也很聪明,采用了双层检索策略:
- 低层级检索:专注细节,锁定具体实体的信息,比如“某人是谁”“某地在哪”。→
- 高层级检索:关注全局,处理宏观主题和趋势,比如“某领域的发展方向”。→
这种设计让 LightRAG 能快速适应动态数据场景,同时保证检索既全面又精准,堪称高效实用的“知识捕手”!
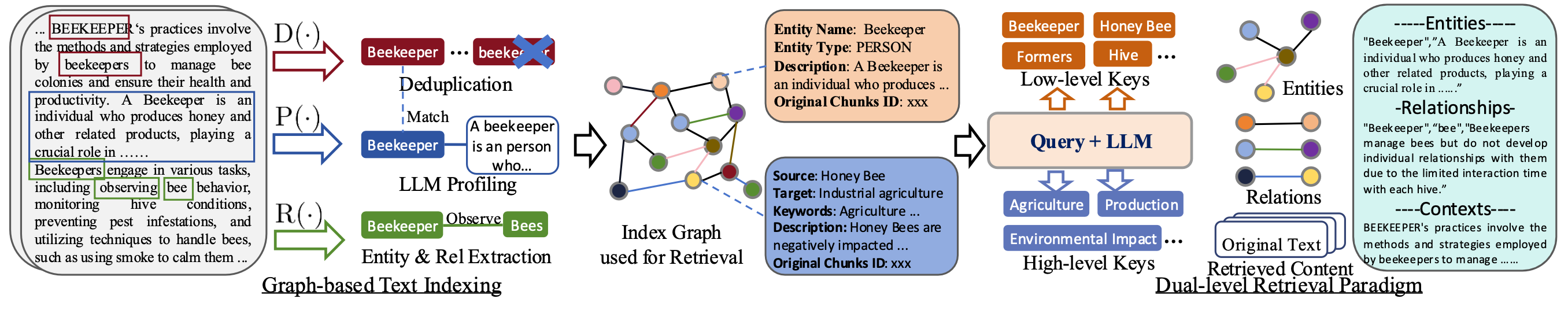
(LightRAG 整体结构(图源 LightRAG 论文))
LightRAG通过以下步骤实现 知识图谱的构建与检索 :
1.实体和关系抽取 :从文档中提取实体和关系(如实体名称、类型、描述等),完成后进行去重操作,然后进行图索引,构建知识图谱。
-
节点属性 :包括实体名称、类型、描述、来源文档ID。
-
关系属性 :包括起点实体、终点实体、关键词、描述、来源文档ID。
2.关键词提取 :
-
具体关键词 :关注精确信息(如实体名称、属性),用于底层级检索。
-
抽象关键词 :关注宏观主题或领域信息,用于高层级检索。
3.双层级检索:
-
低层级检索 :针对具体关键词,查找特定实体及其属性,提供详细信息。
(示例关键词:如“beekeeper”“hive”,获取具体实体的属性和关系。)
-
高层级检索 :针对抽象关键词,分析宏观主题、趋势或多个实体间的关系。
(示例关键词:如“agriculture”“production”,提供全局性见解。)
4.动态更新: 当有新数据加入时,仅需更新新增的节点和边,无需重建整个知识图谱,降低计算成本。
通过这种设计,LightRAG能够 高效 处理具体细节和宏观主题问题,为用户提供精准且深度的答案!
LightRAG VS GraphRAG🤦
🌐对于Legal Dataset,共94篇文章,约5000K Token(约5个水浒传大小)。GraphRAG 生成了 1399 个communities,平均每个社区报告生成需要5000Token, 其中 610 个 level-2 communities, 平均每个level-2的社区占用1000Token。下表对比了创建知识图谱和一次检索所消耗的LLM Token。C_Max为API单次请求最多Token限制,T_extract 代表提取实体和关系消耗Token数,C_extract则表示提取产生的API调用次数。🤦
| 处理阶段 |
query-召回 |
文档创建(5000K Token ) |
||
| 方案 |
GraphRAG |
LightRAG |
GraphRAG |
LightRAG |
| Token消耗 |
610*1000 |
< 100 |
1399*5000 + T_extract |
T_extract |
| API 调用次数 |
610*1000/C_Max |
1 |
1399 + C_extract |
C_extract |
实战演练:知识图谱RAG对复杂query的提升
我们基于LightRAG进行实战,来看看需要的配置吧!
Dataset
-
水浒传_utf8.txt (约912K Tokens)
切分及召回
-
NaiveRAG Chunk 1200 Token; top_k: 10
-
LightRAG Chunk 1200 Token ; relation/entity top_k: 60
使用LightRAG构建知识图谱
Step0️⃣: 环境准备。
🔨vLLM
pip install vllm
🔨LightRAG
pip install lightrag-hku
🔨infinity
pip install infinity-emb
🔨LazyLLM
pip3 install lazyllm
lazyllm install full
-
Git clone https://github.com/HKUDS/LightRAG 并安装lightrag pip install “lightrag-hku[api]”
-
下载语料 水浒传.txt 转为 utf8,并重命名放入比如”novel/shuihu.txt”
-
主动创建保存知识图谱的目录
Step1️⃣: 使用VLLM/Ollama等工具部署openai 兼容格式的LLM服务。
⚠️注:由于文章较长,尝试过多个平台的在线模型,即使换不同的语料,依然会有触发“内容安全限制”的情况。所以只能选择本地部署的LLM。
下载模型(Qwen 2.5-32B-Instruct),推荐从ModelScope下载:
注:由于文章较长,尝试过多个平台的在线模型,即使换不同的语料,依然会有触发“内容安全限制”的情况。所以只能选择本地部署的LLM。
下载模型(Qwen 2.5-32B-Instruct),推荐从ModelScope下载:
python -m vllm.entrypoints.openai.api_server --model /mnt/lustre/share_data/lazyllm/models/Qwen2.5-32B-Instruct/ --served-model-name qwen2 --max_model_len 16144 --host 0.0.0.0 --port 12345
Step2️⃣: 部署embedding 服务或使用已有平台的openai兼容格式的embedding在线服务。
下载模型(bge-large-zh-v1.5),推荐从ModelScope下载:
infinity_emb v2 --model-id "/mnt/lustre/share_data/lazyllm/models/bge-large-zh-v1.5" --port 19001 --served-model-name bge-large
Step3️⃣: 参照 examples/lightrag_openai_compatible_demo.py 修改LLM服务和embedding服务的配置 配置llm_model_func和embedding_func 的三个参数:model, base_url, api_key。
✅设置处理的文件名和保存知识图谱的文件夹路径
-
WORKING_DIR 为 知识图谱保存的文件夹路径
-
PATH_TO_TXT 为 待解析的小说 <水浒传>,注意检查是否为utf8格式
✅修改llm_model的配置
-
base_url 改为 http://{ip}:{port}/v1
-
model_name 改为 vLLM中配置的 qwen2
✅修改openai_embed的配置
-
base_url 改为 http://{ip}:{port}
-
model_name 改为 infinity中配置的 bge-large
Step 4️⃣ : 调整examples/lightrag_openai_compatible_demo.py 中的main 函数 设置知识图谱的存储目录WORKING_DIR 和文本文件的路径 PATH_TO_TXT。
async def main():
WORKING_DIR = "****"
PATH_TO_TXT = "shuihu.txt"
try:
embedding_dimension = await get_embedding_dim()
print(f"Detected embedding dimension: {embedding_dimension}")
rag = LightRAG(
working_dir=WORKING_DIR,
llm_model_func=llm_model_func,
embedding_func=EmbeddingFunc(
embedding_dim=embedding_dimension,
max_token_size=8192,
func=embedding_func,
),
)
with open(PATH_TO_TXT, "r", encoding="utf-8") as f:
await rag.ainsert(f.read())
except Exception as e:
print(f"An error occurred: {e}")
Step5️⃣ : 运行Demo,并检查WORKING_DIR中是否有graph_chunk_entity_relation.graphml 生成,其大小约为5M左右表示成功。
LazyLLM融合LightRAG
让我们看看整体的流程图吧!

- Step 1: 参考LightRAG构建知识图谱中的方式部署本地LLM和embedding服务✔️
- Step 2: 设置LightRAG知识图谱的存储目录
working_dir和文本文件的路径txt_path,并配置LazyLLM知识库目录dataset_path✔️
import os
import asyncio
import lazyllm
from lazyllm import pipeline, parallel, bind, Retriever
from lightrag import LightRAG, QueryParam
from lightrag.kg.shared_storage import initialize_pipeline_status
from lightrag.utils import setup_logger, EmbeddingFunc
from lightrag.llm.openai import openai_complete, openai_embed
class LightRAGRetriever:
def __init__(self, working_dir, txt_path, mode="hybrid"):
self.working_dir = working_dir
self.txt_path = txt_path
self.mode = mode
self.api_key = "empty"
self.rag = None
self.loop = asyncio.new_event_loop()
setup_logger("lightrag", level="INFO")
if not os.path.exists(working_dir):
os.makedirs(working_dir)
self.loop.run_until_complete(self.initialize_rag())
async def initialize_rag(self):
self.rag = LightRAG(
working_dir=self.working_dir,
embedding_func=EmbeddingFunc(
embedding_dim=1024,
max_token_size=8192,
func=lambda texts: openai_embed(
texts=texts,
model="bge-large",
base_url="http://0.0.0.0:19001",
api_key=self.api_key,
)
),
llm_model_func=openai_complete,
llm_model_name="qwen2",
llm_model_kwargs={"base_url": "http://0.0.0.0:12345/v1", "api_key": self.api_key},
)
await self.rag.initialize_storages()
await initialize_pipeline_status()
with open(self.txt_path, "r", encoding="utf-8") as f:
content = f.read()
await self.rag.ainsert(content)
def __call__(self, query):
return self.loop.run_until_complete(
self.rag.aquery(
query,
param=QueryParam(mode=self.mode, top_k=3, only_need_context=True)
)
)
def close(self):
if self.rag:
try:
self.loop.run_until_complete(self.rag.finalize_storages())
except Exception as e:
print(f"关闭LightRAG时出错: {e}")
finally:
self.loop.close()
self.rag = None
def main():
kg_retriever = None
try:
documents = lazyllm.Document(dataset_path="****")
prompt = ('请你参考所给的信息给出问题的答案。')
print("正在初始化知识图谱检索器...")
kg_retriever = LightRAGRetriever(
working_dir="****",
txt_path="****"
)
print("知识图谱检索器初始化完成!")
bm25_retriever = lazyllm.Retriever(
doc=documents,
group_name="CoarseChunk",
similarity="bm25_chinese",
topk=3
)
def bm25_pipeline(query):
nodes = bm25_retriever(query)
return "".join([node.get_content() for node in nodes])
def context_combiner(*args):
bm25_result = args[0]
kg_result = args[1]
return (
f"知识图谱召回结果:\n{kg_result}"
f"BM25召回结果:\n{bm25_result}\n\n"
)
with lazyllm.pipeline() as ppl:
with parallel() as ppl.multi_retrieval:
ppl.multi_retrieval.bm25 = bm25_pipeline
ppl.multi_retrieval.kg = kg_retriever
ppl.context_combiner = context_combiner
ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=ppl.input)
ppl.llm = (
lazyllm.OnlineChatModule().prompt(
lazyllm.ChatPrompter(
instruction=prompt,
extra_keys=['context_str']
)
)
)
lazyllm.WebModule(ppl, port=23466).start().wait()
except Exception as e:
print(f"\n处理过程中发生错误: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
main()
Step 3 : 运行Demo,则会启动Web端服务,即可向LLM提出问题啦。
————————————
通过这次的深入学习与实战,我们不仅了解了如何让知识图谱RAG“抽取实体、建图索引、逻辑推理”,更真正掌握了:一个能从碎片化信息中构建语义关联、支持复杂推理的RAG系统,不再只是简单的检索工具,而是具备全局视角与结构化思考能力的智能助手!
从分块抽取让系统“识别知识点”,到构建知识图谱为RAG搭建“语义网络”,再到高低层级检索实现从细节到全局的全面回答,我们一步步,把RAG从文本问答助手,进化成了语义理解+知识聚合的超级推理专家。
这不仅是功能的叠加,更是一次认知能力的全面升级!知识图谱RAG不再仅仅“回忆知识”,它开始学会“理解语义”、“关联信息”、“生成深度洞察”。
————————————
更多技术交流,欢迎移步“LazyLLM”GZH!
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


