
<p style="color:#222222; margin-left:8px; margin-right:8px; text-align:justify"><span><span style="color:#3f3f3f">本文内容来自金山办公的高级研发工程师肖圆,在<span> </span></span>蓝鲸智云 和 DeepFlow 社区联合举办的《觉醒!当AI获得系统感知力》武汉Meetup上的主题分享。
作者:肖圆,金山办公的高级研发工程师
大家下午好,我是来自金山办公的肖圆。今天分享的主题是我们基于 DeepFlow 在 Docker模式下的实践,我们这边可能是 DeepFlow 社区版在真正的在 Docker 模式下的做了一个落地实践探索。然后可能中间有一些经验可以跟大家去做一些分享。今天从这三个方向,一是,可观测性建设现状;二是,可观测落地与实践,最后,是可观测后续规划。
去年金山办公主要是基于 K8S 微服务架构做了可观测建设的探索实践,今年,由于应用架构从 K8S 逐渐演变为单元化架构,我们的战略也做了调整,可观测作为核心能力模块成为公司级项目。所以今年主要的目标是为了配合架构演进需求,技术团队将基于 DeepFlow 可观测平台,在纯 Docker 环境中构建新一代的全栈可观测体系,为架构转型提供坚实的技术保障。另一方面,这些可观测数据也是为后续AI的接入和故障自愈的落地做一些数据的保障。

01|可观测落地与实践
首先,看一下我们在 Docker 环境落地部署的单元化架构。单元化架构中的每个单元均包含完整的业务逻辑,可独立运行和扩展。在每个节点上都会有 DeepFlow Agent 来采集数据,这些数据会汇总到我们的一个监控节点上,也就是部署了可观测服务的这个节点上去。
在 DeepFlow 可采集到的数据基础上,我们也接入了业务的 APM 数据,每个节点的 APM 数据业务会通过 OTel SDK 去推送到我们的 Otel Collector 里面去。然后我们 Otel Collector 会再把 APM 数据集成到 DeepFlow Agent 里面。
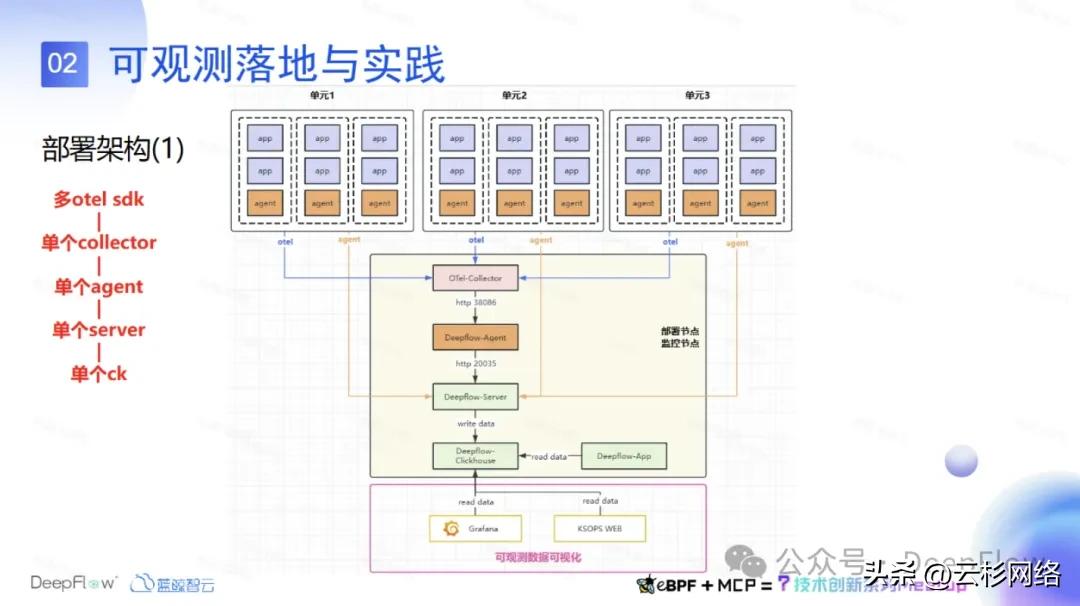
目前这个架构下接入 Otel 的服务比较少,还是可以落地的。未来要实现所有服务接入 Otel SDK 来接入 APM 数据的话,从现在的这个架构来讲会存在两个瓶颈。第一个是 Otel Collector 的性能问题,现阶段是一个节点上取了一个容器,当所有业务的数据都往这一个容器上推送的话,一旦 Otel Collector 出现性能问题,就会导致我们的业务的 APM 数据会无法去聚合。
第二个是我们的 Agent,因为 Agent 自己有熔断策略,它基于部署节点的负载自己会识别熔断的阈值来做宕机的策略。这些节点上同时也部署了很多 DeepFlow server,它也是会有一些资源消耗的,一旦这个节点负载稍微上升那 Agent 就可能不工作了。这中情况也会导致 Otel SDK 的数据可能也过不来。以上是目前这个架构存在的两个性能瓶颈的地方,后面随着业务接入越来越多,我们会采取第二种架构。
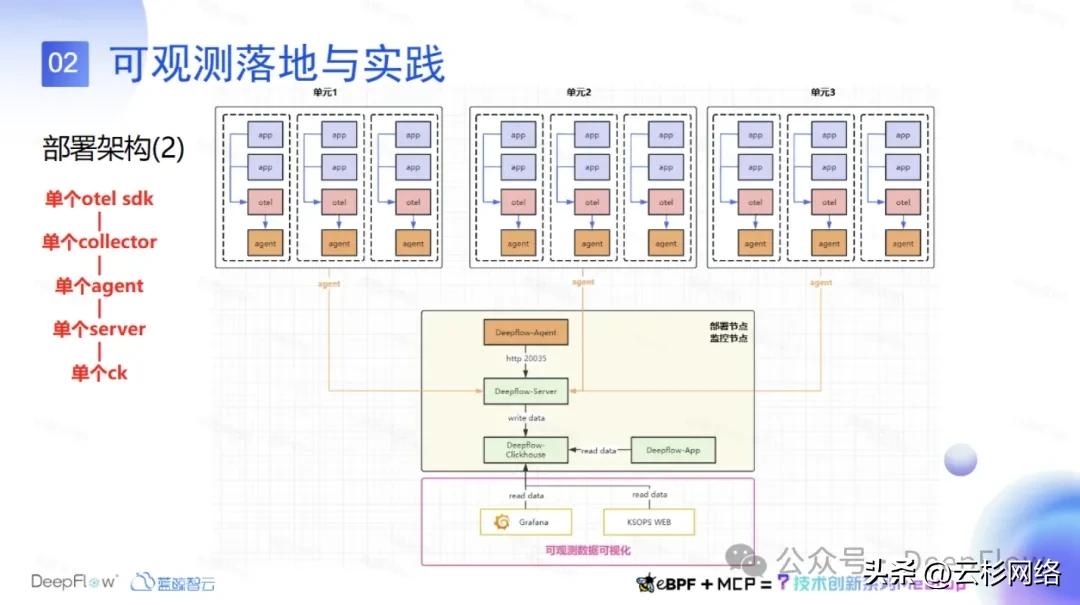
那第二种架构就是在我们的每一个节点上面都会布一个 Otel Collector,来收集本节点上所有的业务 trace 数据。然后本节点数据会给到本节点的 Agent,然后每个节点的 Agent 会集中到 DeepFlow server 端,这样的话就解决了 Otel Collector 性能瓶颈问题。后续我们会针对这一架构做出调整,调整之后会去做一些性能测试,看这种新的架构的性能怎么样。这是部署架构这一块儿。
部署方式上我们用的是纯 Docker 模式,所以都是 Docker compose 起的,针对每一个组件都有一个资源的 limit。因为它有一些消耗所以要做一些资源 limit。
另外在 server 端这一块,我们在 docker 模式适配的下会发现有一些问题,图中标红的这块内容要去做全量的变量注入。我们之前发现如果不注入的话,可能在一些场景下特别是在 IPV6 场景下会有问题。虽然能注册成功,但是它可能采集不到数据。

后面就是 Agent 的一个全局配置。这里标红的地方是我们这边比较注重。在 On CPU 这块儿 DeepFlow 对于我们来讲其实是一个福利。就是我们可以去零代码来采集业务函数级的性能剖析图。DeepFlow 默认只采集自身的数据,我们只需要指定采集的业务的进程名称就可以了。然后 Agent 也是有一个资源的 limit。
右边这部分的内容,我们也做了 mysql redis 和 kafka 的数据脱敏限制。因为这样用我们这些中间的数据可能有一些敏感的信息,做脱敏能在一定程度上降低一些存储的空间。另外,我们也指定启用了一些我们所关注的协议,现在关注的就是这六种协议。

接下来分享我们在适配期间的一些经验。第一个就是适配 Docker 模式的情况下,因为以前在 K8S 的情况下链路这一块儿的客户端和服务端可能直接显示 pod 的名称,所以更容易去看问题,去绘制业务全景图。
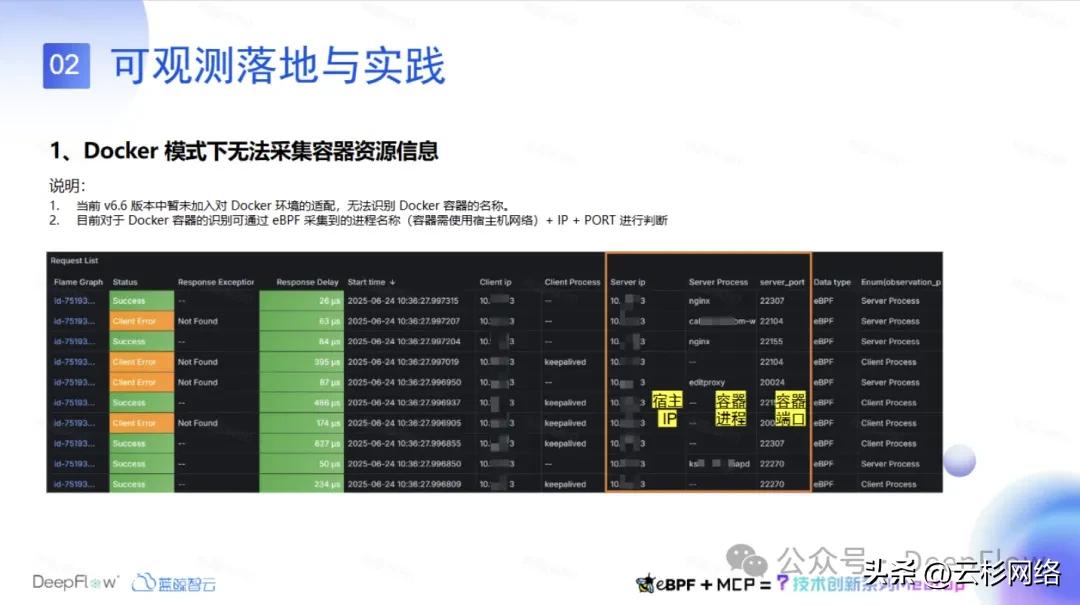
但是在 Docker 模式下, DeepFlow v6.6 版本中暂未加入对 Docker 环境的适配,链路上都是以 IP 的形式显示,无法识别 Docker 容器的名称。我们现在的微服务也都是 docker-compose 起的,而且也是 host 网络。所以对于当前的版本对 Docker 来讲没法直接显示微服的容器名称。这样不能直观的看到底是哪个服务访问哪个服务,而且对于绘制拓扑图也有一定的影响。目前对于 Docker 容器的识别我们是通过 eBPF 采集到的进程名称(容器需使用宿主机网络)+IP+PORT 进行判断,来解决这一问题。
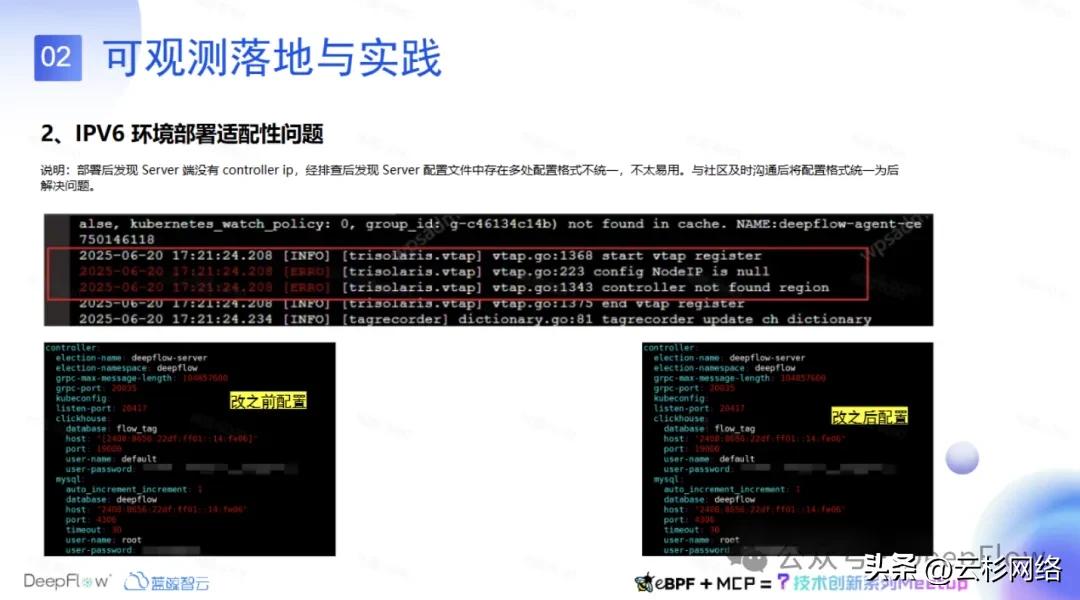
第二块就是 IPV6 环境部署适配性的问题。我们在适配的时候发现 Agent 注册不上,Server 端没有 Cont roller IP,经排查后发现 Server 配置文件中存在多处配置格式不统一不太易用,向 DeepFlow 社区反馈并沟通之后,发现是我们在做 IPV6 时地址格式不统一而导致的,同时社区也做了一些更新。我们把所有的 IPV6 的地址以不带中括号的形式去统一的配置更新后这一问题就得到了解决。
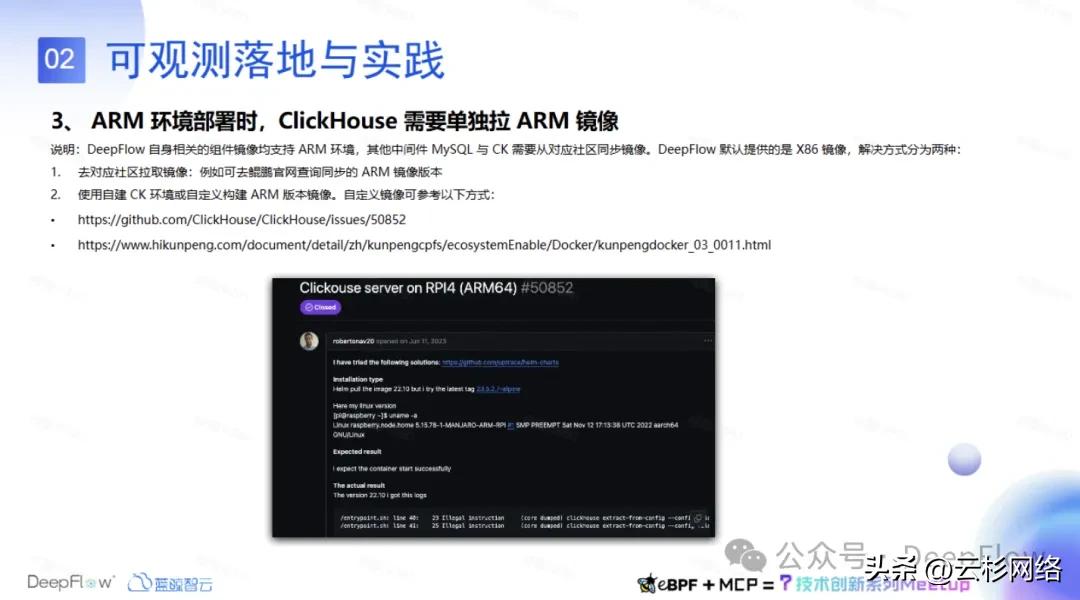
第三块是 ARM 环境部署时遇到的问题,我们用的 ClickHouse 也是 DeepFlow 官方,对于不同的操作系统 arm 环境来说 CK 的版本兼容性是不一样的。我们在做操作系统识别的时候,发现 UVS 系统是用不了现在 CK 最新的 23.8 这个版本,所以它只能降到 23.5 这个版本才能适配在 UVS 系统。还有麒麟系统也是适配的时候有一些问题,麒麟有两个版本其中 Sword 这个版本,它也只能用低版本的 CK 才能去部署。DeepFlow 官方给出了两种解决方式,一是去对应社区拉取景象,例如去鲲鹏的官网查询同步 ARM 的镜像版本;另一种是实用自建 CK 环境或自定义构建 ARM 版本镜像。
第四是业务端口与 Server 端口冲突的问题,在部署 DeepFlow server 的时候,发现它其实有很多监听端口,其中有一个 data source 的 20106 这个端口。我们的 A 产品在部署 server 的时候已经占用了这个端口,但因 A 产品的服务跟我们的服务不在一起,所以没发现这个端口的问题。但在跟 B 产品的服务布在一起的时候,就发现这个 20106 端口把业务端口给占用了,导致业务起不来功能受到影响,因为是先部署的 Server 后部署的 B 业务。当我们跟社区反馈沟通之后,社区很快速的就把这个端口给暴露出来。我们通过在 Server 配置中自定义模块所用的端口,并更新镜像之后很快就解决了这个问题。

下面是 DeepFlow 大版本升级的注意事项,像 DeepFlow V6.5~V6.7 这些大版本升级的话是不支持版本回退的。因为每个版本对参数和结构都有一些变化,所以只支持升级版本。目前金山办公用的是 V6.6 版本,马上要验证升到 V7。因为 DeepFlow V7 对一些资源的占用做了优化,这恰恰也是我们所重视的问题之一。
02|可观测实践阶段性成果
接下来是可观测建设中的一些阶段性的成果。这是函数级别的一个链路数据,这个 A 标签就是我们的业务通过 Otel SDK 来注入上报的 trace 数据,这个是基于函数级别的一个 Span 的数据。在做完这个联调之后,我们发现这个函数级别的链路数据是研发同学很希望能看到的。所以我们现在也是侧重于用 A 标签这个数据。

第二块是性能剖析,这是一个真实的案例,我们在做 DeepFlow 架构压测的时候,有一个服务在压测之前他只占 0.5 核,但是在压测期间可能占用了 1.5 核,压测结束之后这个服务还是 1 核,并没有恢复到以前的 0.5 核。就这个问题研发就提出为什么压测之后这个服务还是占 1 核,是不是 CPU 哪里有问题?在这种情况下我们就想到 DeepFlow 可以零侵入的采集到了函数级别的性能数据,建议研发同学,通过性能剖析图去定位是哪一个函数导致的这个问题。他们看完之后,选中自己的服务来生成这个剖析图之后,确实发现了导致这个问题的瓶颈点。
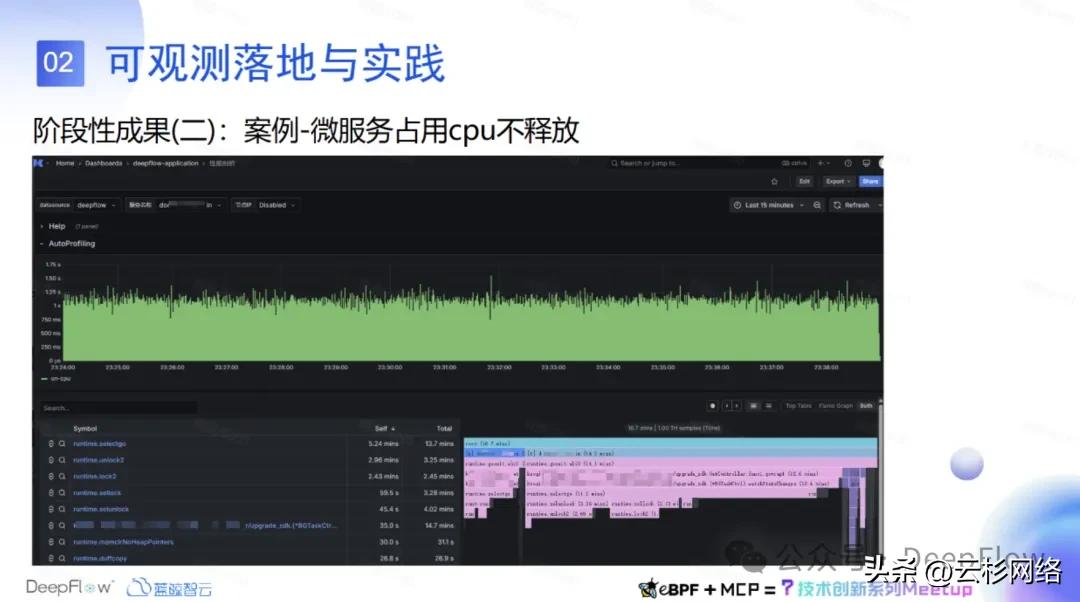
为了验证性能剖析图定位出的函数问题,研发同学在自己的服务接口导出了 pprof 报告,通过对比,发现确实是那个函数的 CPU 的问题。因为那个函数可能有一个定时入口在跑,导致那个接口经过压测之后 CPU 占用水平一直下不来。这就证明我们这个函数性能剖析图还是很准确的,对于我们现场做一些 CPU 的性能分析是很有帮助的。
因为我们经常会有一些私有化项目,它可能是内网环境。我们现在用的 pprof 都是要经过我们平台去生成 pprof 的文件,然后还要导出到我们本地给研发看。但有的客户环境不允许你去下文件出来,那对于这种场景选择用 DeepFlow 自带的性能剖析图功能是非常有帮助、非常方便的。
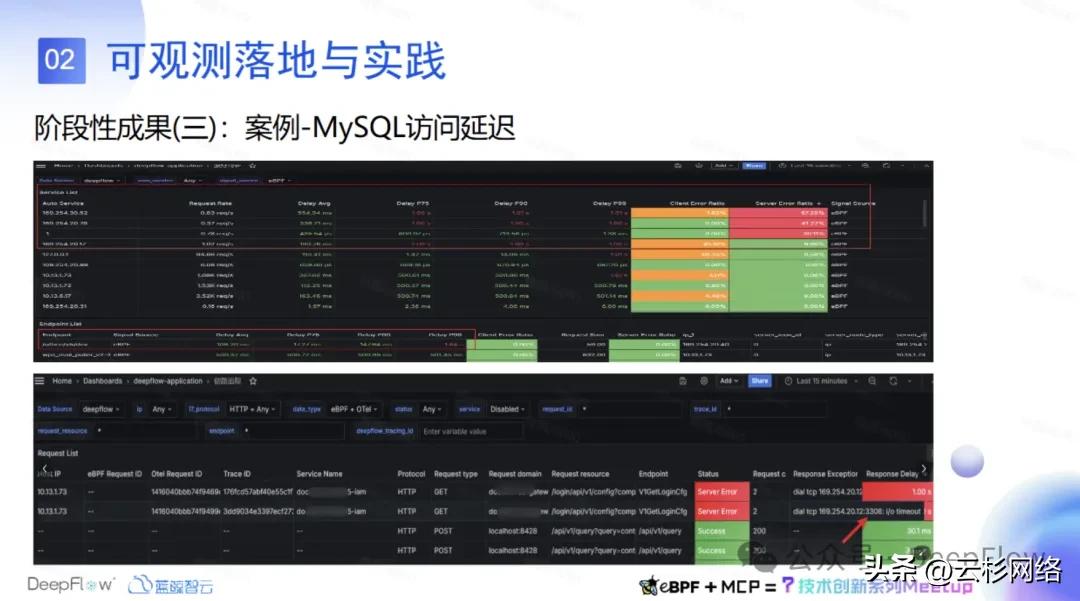
第三个案例是我们本地的 mysql 所在的节点负载比较高,出现了一些延迟的情况。针对这种情况 DeepFlow 自带的一个 Grafana 看板里面可以看到很多服务调用 mysql 时出现了很多 5xx 状态码。那我们进一步去看它链路里面的情况,可以很清楚的看到服务有报错,是连接 3306 有 time out 情况。所以这个情况也能说明用了 DeepFlow 可观测产品之后,链路追踪其实是可以很直观的看出一些问题的。这个是我们自己的联调环境在 mysql 所在的节点出现负载的问题时,通过看板发现是 mysql 延迟导致的业务问题。
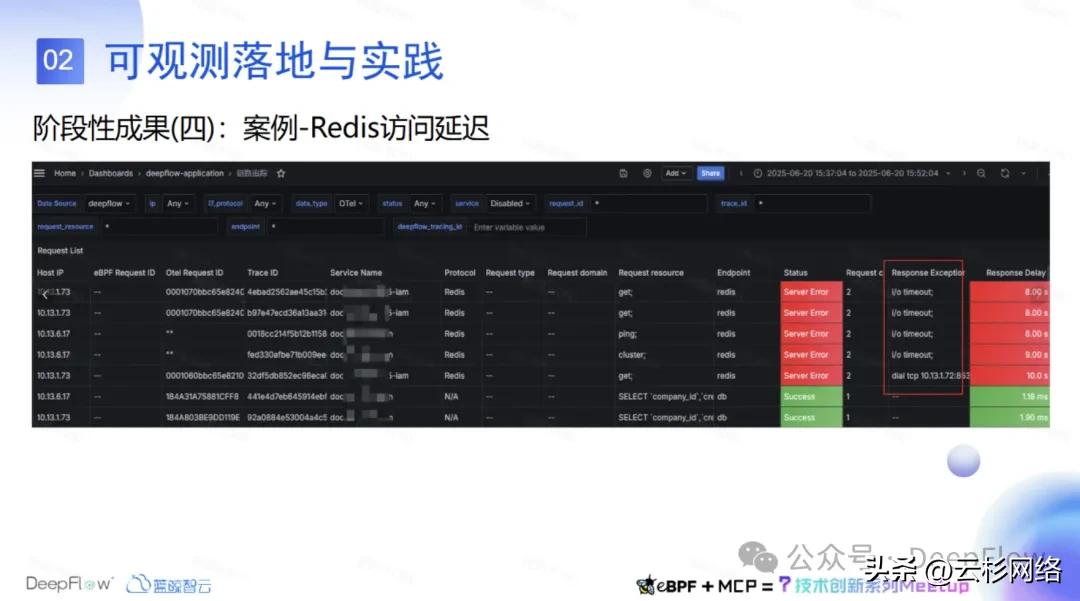
第四个案例是 redis 访问验证,这个是我们做的一个故障模拟场景。我们通过混沌工程对 redis 访问延迟做了一些限制。限制之后能在链路追踪看板里面很直观的看到是访问 redis 一些 time out 延迟的问题,DeepFlow 的这个功能可以很快速的定位到问题。
第五是系统适配方面,常见的 centos、redhat、ubuntu、suse、uos、kylin 这 6 种操作系统,amd64 核 arm64 两种 cpu 架构,以及 IPV6、IPV4 的 IP 栈都完成了可观测服务的适配。

数据联动这块,我们目前做了监控可观测。监控可观测里面是基于我们业务的一些 red 指标,就是相当于业务 SLO 指标,SLO 下降之后联动到我们的灭火图。在灭火图里面都是通过一个全局视图来展示业务的核心指标。如果哪个服务的 SLO 下降了,就通过灭火图可以看到是哪个服务的接口请求。比如出现 5xx、出现延迟高了,那么通过灭火图之后来再下钻到指标详情、监控看板、告警事件去分析到底是什么问题什么接口。
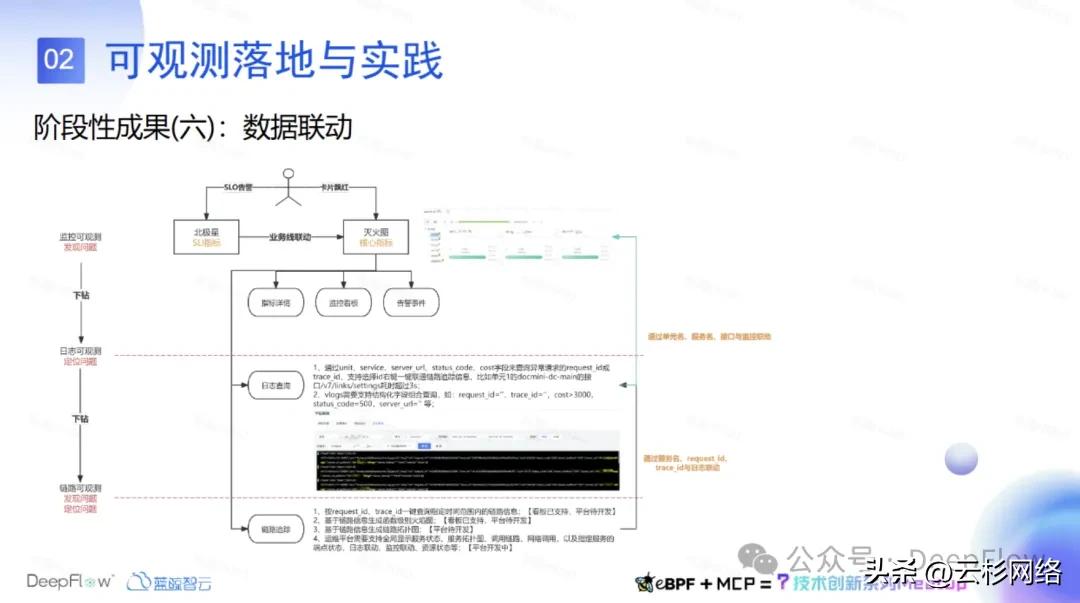
然后监控灭火图也可以关联到日志查询里面去。通过 service_name 和 URL,比如说接口延迟大于 3 秒了,可以通过日志里面结构化的字段去查,可以查出这个服务的接口日志。通过日志联动能查到出现问题这个链路的 request ID 或者 trace ID,然后我们再拿 trace ID 去链路追踪里面关联相应的核心链路,从这里可以看到性能剖析图,和 eBPF 所抓取到的一些 metric、日志数据、再加上函数级的性能拓扑图,可以进一步做下钻分析和问题的定位。
链路追踪这一块我们目前在做平台化开发,后续会对指标、日志、链路这三块数据做一些联动,目标是提升现场问题排查的效率。有时间可以在和大家分享一下这个平台的建设实践。
03|可观测建设后续规划
最后可观测建设的一个后续规划,第一,应用侧全链路接入,因为我们要集成 APM 数据到 DeepFlow 里面,所以推动各业务线按照 Otel SDK 的标准来接入。确保 Q3 要完成所有的核心业务的接入。
第二,统一观测平台的建设,就是前面所提到正在建设中的平台,目前是基于 Grafana 看板来实现,但在数据联动方面无法满足我们的需求,体验也不好。所以要开发新一代的可观测分析平台,实现四维数据联动,构建多维度数据关联分析能力。
第三,有效性验证体系。基于混沌工程来做一些故障模拟。通过收集现场客户遇到的常规故障来做一些模拟,模拟就验证我们这个可观测体系到底有没有它的价值,能不能发挥它的价值。基于故障模拟之后会出 SOP 的方案,对于现场来讲针对出现的故障就可以按照SOP去定位问题。
第四,引入 AIOps 能力,因为我们私有化这块也有自己的 AI 大模型。我们现在在做可观测的基建,也是为了做数据的积累。那么有了基建,有了这些基础数据之后,通过刚才向总所讲的那个 MCP Server,可以与大模型结合起做智能分析,如自动化的巡检、异常模式智能识别、故障根因辅助分析等。所以我们今年会先建设可观测平台,然后把 AI、自愈能力去跟平台做一些整合,最终形成一个完整的可观测平台。以上就是我今天分享的内容,在这里特别感谢 DeepFlow 社区的小伙伴对我们的大力支持,谢谢。

PPT 下载
https://yunshan-guangzhou.oss-cn-beijing.aliyuncs.com/yunshan-ticket/jpg/6815b7d64b37417156ca9f8bf1403705_20250702104904.pdf
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


