
<p style="color:#000000; text-align:justify"><span><span>Flink-Doris-Connector 作为 Apache Flink 与 Doris 之间的桥梁,打通了实时数据同步、维表关联与高效写入的关键链路。本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。</span></span></p>
一、 Apache Doris 简介
Apache Doris 是一款基于 MPP 架构的高性能、实时的分析型数据库,整体架构精简,只有 FE 、BE 两个系统模块。其中 FE 主要负责接入请求、查询解析、元数据管理和任务调度,BE 主要负责查询执行和数据存储。Apache Doris 支持标准 SQL 并且完全兼容 MySQL 协议,可以通过各类支持 MySQL 协议的客户端工具和 BI 软件访问存储在 Apache Doris 中的数据库。
在典型的数据集成和处理链路中,往往会对 TP 数据库、用户行为日志、时序性数据以及本地文件等数据源进行采集,经由数据集成工具或者 ETL 工具处理后写入至实时数仓 Apache Doris 中,并由 Doris 对下游数据应用提供查询和分析,例如典型的 BI 报表分析、OLAP 多维分析、Ad-hoc 即席查询 以及日志检索分析等多种数据应用场景。
Flink-Doris-Connector 是 Apache Doris 与 Apache Flink 在实时数据处理 ETL 的结合,依托 Flink 提供的实时计算能力,构建高效的数据处理和分析链路。Flink-Doris-Connector 的使用场景主要分为三种:
-
Scan :通常用来做数据同步或是跟其他数据源的联合分析;
-
Lookup Join :将实时流中的数据和 Doris 中的维度表进行 Join;
-
Real-time ETL :使用 Flink 清洗数据再实时写入 Doris 中。

二、Flink-Doris-Connector 典型场景的设计与实现
本章节结合 Scan、Lookup Join、Write 这三种场景,介绍 Flink-Doris-Connector 的设计与实现。
01 Scan 场景
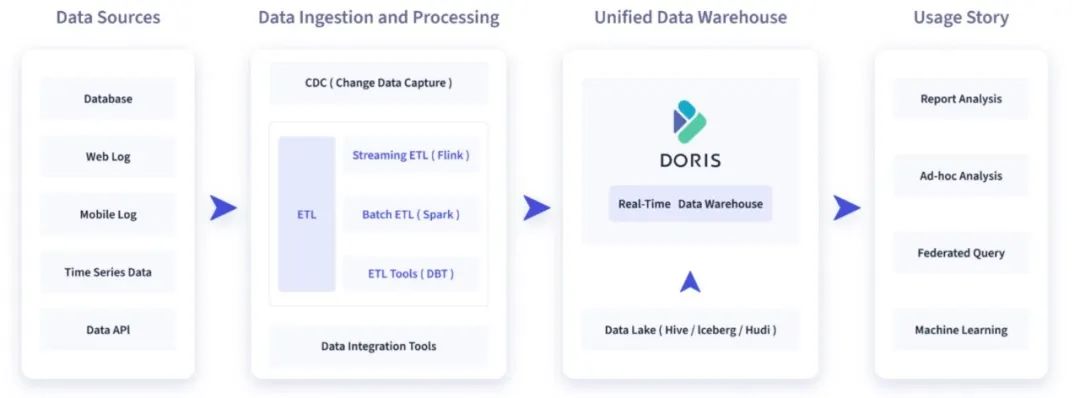
Scan 场景指将 Doris 中的存量数据快速提取出来,当从 Doris 中读取大量数据时,使用传统的 JDBC 方法可能会面临性能瓶颈。因此 Flink-Doris-Connector 中可以借助 Doris Source ,充分利用 Doris 的分布式架构和 Flink 的并行处理能力,从而实现了更高效的数据同步。
Doris Source 读取流程
-
Job Manager 向 FE 端发起请求查询计划,FE 会返回要查询的数据对应的 BE 以及 Tablet;
-
根据不同的 BE,将请求分发给不同的 TaskManager;
-
通过 Task Manager 直接读取每个 BE 上对应 Tablet 的数据。
通过这种方式,我们可以利用 Flink 分布式处理的能力从而提高整个数据同步的效率。
02 Lookup Join 场景
对于维度表存储在 Doris 中的场景,可通过 Lookup Join 实现对实时流数据与 Doris 维度表的关联查询。
JDBC Connector
Doris 支持 MySQL 协议,所以可以直接使用 JDBC Connector 进行 Lookup Join,但是这一方式存在一定的局限:
-
Jdbc Connector 中的 Lookup Join 是同步查询的操作,会导致实时流中每条数据都要等待 Doris 查询的结果,增加了延迟。
-
仅支持单条数据查询,在上游数据量吞吐较高时,容易造成性能瓶颈和反压。
Flink-Doris- Connector 的优化
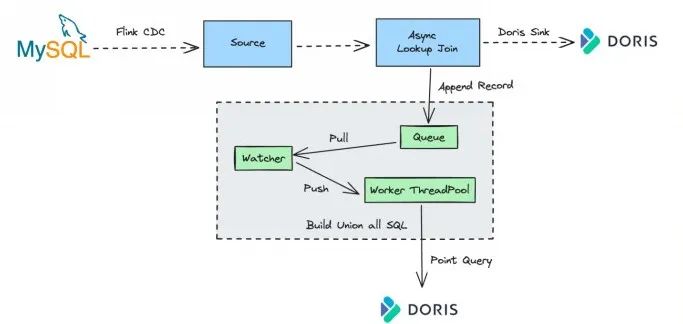
因此针对 Lookup Join 场景 ,Flink-Doris-Connector 实现了异步 Lookup Join 和攒批查询的优化:
-
支持异步 Lookup Join: 异步 Lookup Join 意味着实时流中的数据不需要显式等待每条记录的查询结果,可以大大的降低延迟性。
-
支持攒批查询: 将实时流的数据追加到队列 Queue 中,后台通过监听线程 Watcher,将队列里面的数据取出来再推送到查询执行的 Worker 线程池中,Worker 线程会将收到的这一批数据拼接成一个 Union All 的查询,同时向 Doris 发起 Query 查询。
通过异步 Lookup join 以及攒批查询,可以在上游数据量比较大的时候大幅度提高维表关联吞吐量,保障了数据读取与处理的高效性。
03 实时 ETL 场景

对于实时写入来说,Doris Sink 的写入是基于 Stream Load 的导入方式去实现的。Stream Load 是 Apache Doris 中最为常见的数据导入方式之一,支持通过 HTTP 协议将本地文件或数据流导入到 Doris 中。主要流程如下:
-
Sink 端在接收到数据后会开启一个 Stream Load 的长链接请求。在 Checkpoint 期间,它会将接收到的数据以 Chunk 的形式持续发送到 Doris 中。
-
Checkpoint 时,会对刚才发起的 Stream Load 的请求进行提交,提交完成后,数据才会可见。
如何保证数据写入的 Exactly-Once 语义
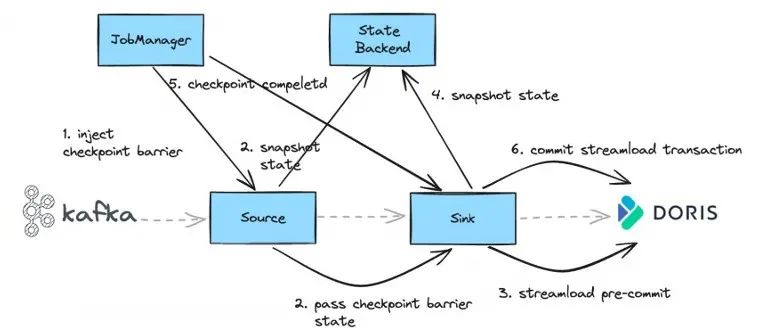
那么,如何保证数据写入期间,端到端数据的精确一次性?
以 Kafka 同步到 Drois 的 Checkpoint 过程为例:
-
Checkpoint 时,Source 端会接收到 Checkpoint Barrier;
-
Source 端接收到 Barrier 后,首先会对自身做一个快照,同时会将 Checkpoint Barrier 下发到 Sink 端;
-
Sink 端接收到 Barrier 后,执行 Pre-commit 提交,成功后数据就会完整写入到 Doris,由于此处执行的是预提交,所以在 Doris 上,此时对用户来说数据是不可见的;
-
将 Pre-Commit 成功的事务 ID 保存到状态中;
-
所有的算子 Checkpoint 都做完后,Job Manager 会下发本次 Checkpoint 完成的通知;
-
Sink 端会对刚才 Pre-commit 成功的事务进行一次提交。
通过这种两阶段提交,就可以实现端到端的精确一次性。
实时性与 Exactly-Once
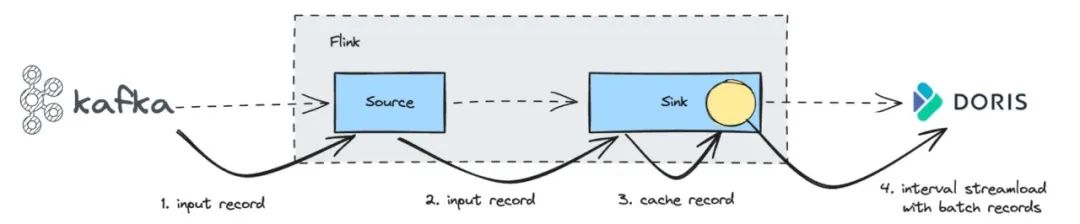
上面提到,Doris Sink 端的写入与 Checkpoint 绑定,数据写入 Doris 的延迟性取决于 Checkpoint 的间隔。但在一些用户的场景下,希望数据可以实时写入,但是 Checkpoint 不能做的太频繁,同时对于一些作业来说,如果 Checkpoint 太频繁会消耗大量资源,针对该情况,Flink-Doris-Connector 引入了攒批机制,以平衡实时性与资源消耗之间的矛盾。
攒批的实现原理是 Sink 端接收上游数据之后,不会立即将每条数据单独写入 Doris,而是先在内存中进行缓存,然后通过对应参数设置,将缓存数据提交到 Doris 中。结合攒批写入和 Doris 中的主键模型,可以确保数据写入的幂等性。
通过引入攒批机制,既满足了用户对数据实时写入的需求,又避免了频繁 Checkpoint 带来的资源消耗问题,从而实现性能与效率的优化。
三、基于 Flink CDC 的整库同步方案
以上是对 Flink-Doris-Connector 的典型场景和实现原理介绍,接下来我们来看它在实际业务中的一个重要应用——整库同步。相比底层实现,整库同步更偏向具体使用场景。下面我们基于前面介绍的能力,进一步探讨如何通过 Flink CDC 实现 TP 数据库到 Doris 的高效、自动化同步。
01 整库同步痛点
在数据迁移过程中,用户通常希望可以尽快将数据迁移到 Doris 中,然而在同步 TP 数据库时,整库同步往往面临以下几点挑战:
-
建表:
-
存量表的快速批量创建 :TP 数据库中往往存在成千上万的表,这些表的结构各异,对于存量表而言需要逐一在 Doris 中创建对应的表结构;
-
同步任务开启后,新增表的自动创建与同步: 为了保证数据的完整性和实时性,同步工具需要实时监控 TP 数据库的变化,并自动在 Doris 中创建和同步新表。
-
-
元数据映射: 上下游之间字段元数据的便捷映射,包括字段类型的转换、字段名称的对应修改等。
-
DDL 自动同步: 增加、删除列等操作会导致数据库结构发生变化,进而影响到数据同步。因此,同步工具需要能够实时捕获 DDL 并动态地更新 Doris 表结构,以确保数据的准确性和一致性。
-
开箱即用: 零代码,低门槛,理想的同步工具只需进行简单配置,即可实现数据的迁移和同步。


