
<p><img src="https://oscimg.oschina.net/oscnet/up-e0de98ebe06d3282e73d55bdbed373a9c84.png" alt=""></p> 摘要:本文整理自抖音集团数据工程师苏兴老师在 Flink Forward Asia 2024 流式湖仓(一)专场中的分享。内容主要为以下三部分:
1、 背景介绍
2、 落地实践
3、 未来展望
01、背景介绍
1.1 业务背景
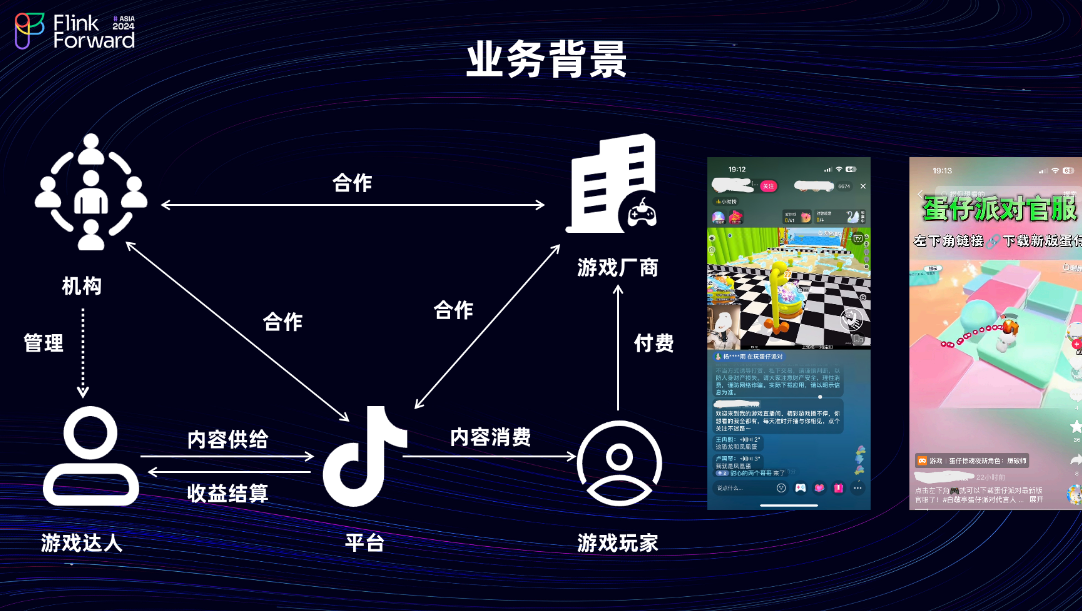
抖音集团的部分平台型业务以内容赋能行业,主要依靠短视频和直播为载体提供内容。对于游戏玩家,旨在提供从”看游戏”到”玩游戏”的完整产品链路;对于游戏达人,旨在激发其创作丰富多元的游戏内容,并使其创作内容的价值获得相应回报;对于游戏厂商,则提供一站式的经营能力解决方案。
1.2 数仓建设
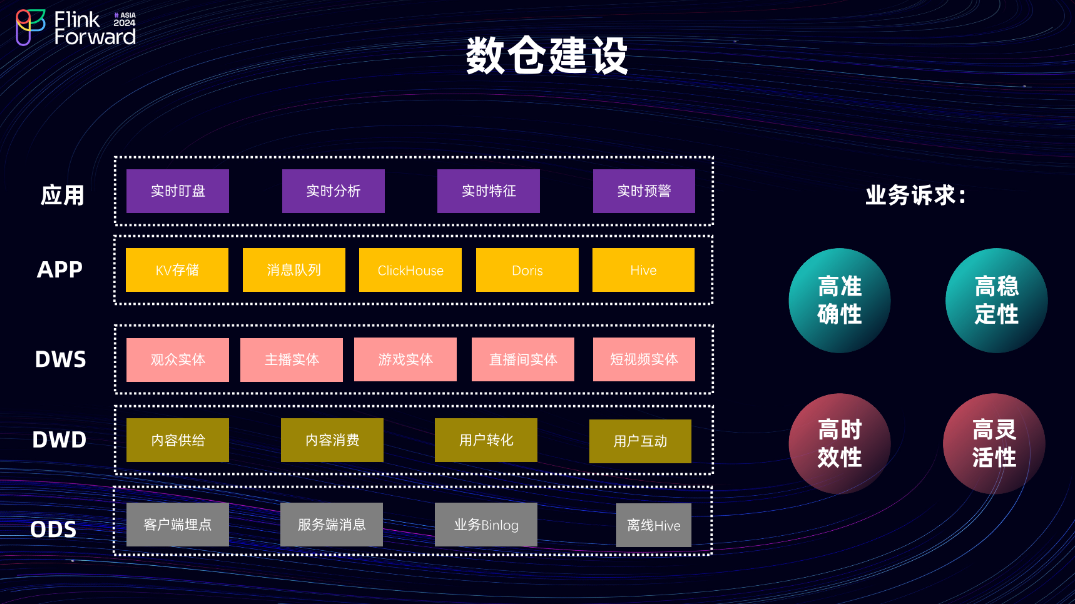
接下来审视实时数仓的整体建设。实时数仓采用行业通用的分层建设架构:
-
ODS 层:数据源主要有客户端埋点、服务端消息和业务 Binlog。
-
DWD 层:按照内容供给、内容消费、用户转化以及用户互动等维度进行业务域划分,并基于不同维度和实体构建窄表聚合模型。
-
APP 层:提供多种类型的存储,以满足下游批式和流式等不同场景的消费需求。其主要应用场景包括实时大盘、实时分析、实时特征和实时预警,旨在满足业务对实时数据的高准确性、高稳定性、高时效性和高灵活性的诉求。
1.3 架构实现
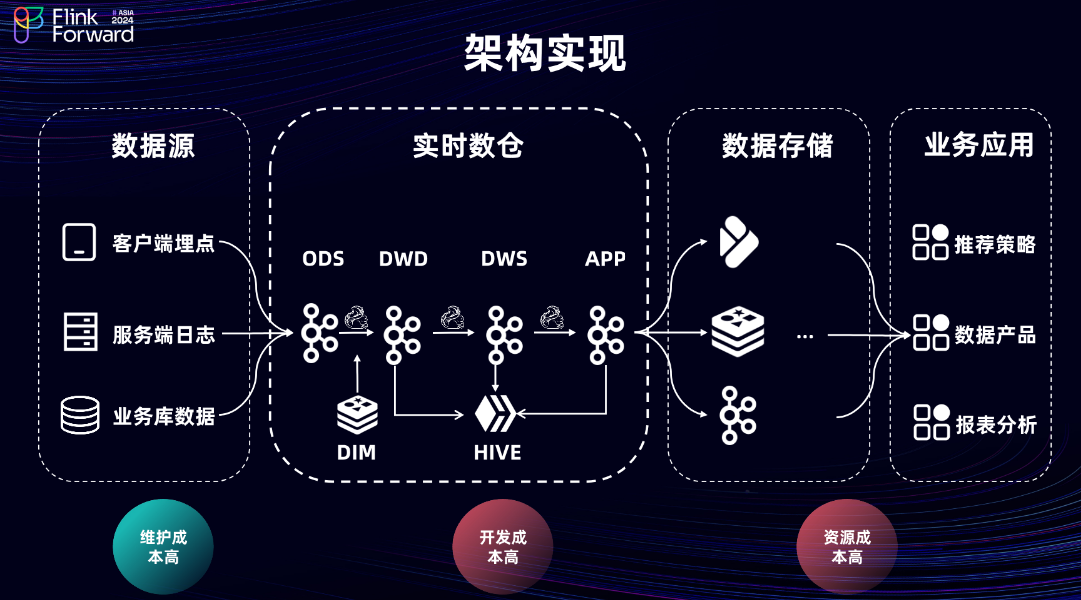
实时数仓的架构实现如图所示。首先,ODS 层的数据主要来自于客户端埋点、服务端日志和业务库数据。从 ODS 层到 APP 层的建设,采用行业较为成熟的 Flink + MQ 方案实现。其中,在 DWD 层主要进行数据的 ETL 和维表关联(打宽)处理。
维表关联主要通过两种方式实现:
-
使用 KV 存储实现 Lookup Join。对于时效性要求较高或流量较大的场景,通常采用此方式,并在 Flink 内部通过 Keyed State 和
distributeBy等多种优化手段,充分利用 Flink 的缓存以提升整体查询性能。但在巨大流量的冲击下,此方案依然对外部 KV 存储的稳定性构成巨大挑战。 -
基于 Hive 或 MySQL 实现 Broadcast Join。对于时效性要求较低的维表(如 T+1 维表),通常采用此方式进行维度关联,当 Hive 分区就绪时,会触发维表的更新。
在 DWD 层,由于内部 MQ 尚不支持精准一次(Exactly-Once)语义,因此需要进行数据去重。APP 层主要是根据业务诉求进行定制化的逻辑开发。最后,会将 ODS 层和 APP 层的数据写入下游的 OLAP 引擎或 KV 存储中,对外提供指标查询服务。
对于整个测试流程,以 DWS 层的测试为例,由于 MQ 不支持直接查询,因此需要将每一层的 MQ 数据同步至 Hive,再基于 Hive 进行数据比对,导致整体测试成本非常高。随着业务的发展,当前架构的痛点也愈发显著。为解决以上问题,团队调研了社区众多开源数据湖引擎,最终决定采用 Paimon 作为数据湖底座,重构实时数仓。
1.4 Paimon 介绍
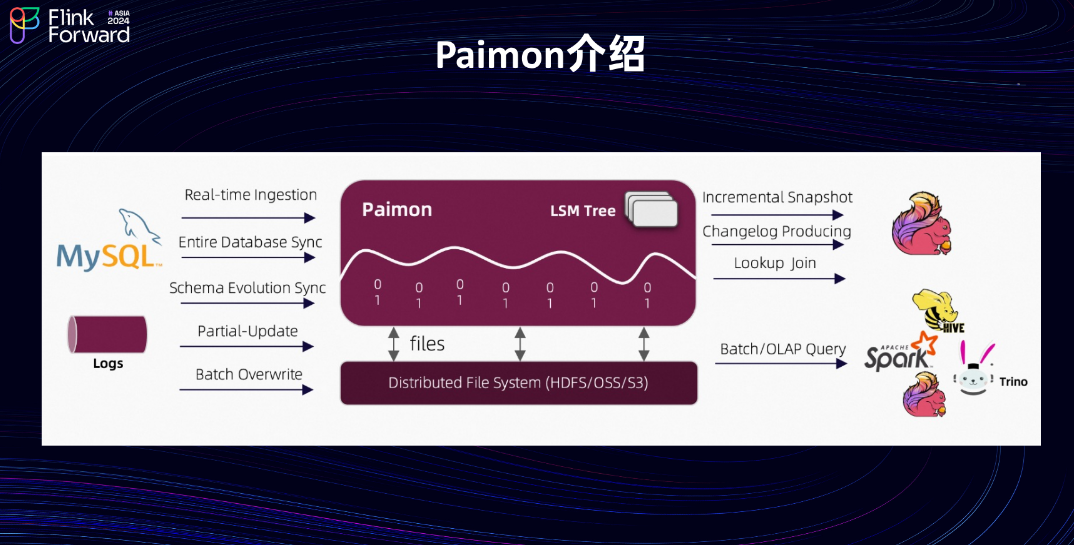
下面简单介绍 Paimon 的核心能力。它具备高吞吐、低延迟的数据摄入能力,同时支持流式订阅和批式查询。Paimon 支持主流的计算引擎和 OLAP 引擎,尤其与 Flink 的结合最为紧密。
1.5 湖仓一体架构
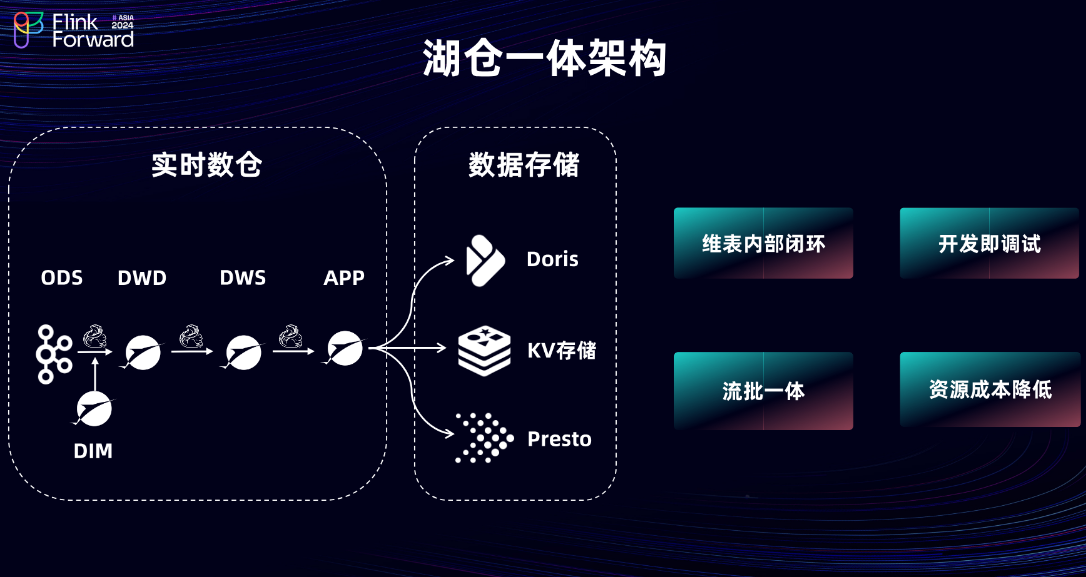
接下来看一下基于 Paimon 的湖仓一体架构。通过当前架构可以看出,相比前面介绍的 Flink + MQ 架构,其设计相当简洁。首先,在开发流程中,DWD 层不再依赖外部的 KV 存储,可直接使用 Paimon 作为维表,通过 Lookup Join 的方式进行维度关联。并且,从 DWD 层到 DWS 层也不再需要进行去重,因为 DWS 层可以直接消费 DWD 层的 Changelog,这样会极大地减少 Flink 作业的 Keyed State,保障数据的稳定性。由于 Paimon 维表目前存储在 HDFS 上,底层使用的是 SSD 存储,尽管如此,相比原有的 KV 存储,在资源成本上仍有非常大的收益。
在开发方式上,当前模式通过 Flink Batch 进行开发和调试,上线时再将作业转换为 Flink Streaming 模式在线上运行。对于整个测试流程,也与之前有所不同。在新的测试流程中,不再需要依赖 Hive 表,因为 Paimon 支持批式查询,且数据新鲜度可达到分钟级,这带来了测试效率的显著提升。
1.6 架构对比

接下来看两个架构的对比。
| 特性 | Flink + MQ 架构 | Paimon 湖仓一体架构 | | ———- | —————————————————- | ——————————————– | | 时效性 | 秒级延迟 | 分钟级延迟(与 Flink Checkpoint 间隔相关) | | 开发成本 | 依赖外部 Hive 进行开发调试,成本较高 | 内置批读批写能力,无需外部依赖,成本更低 | | 架构复杂度 | 需整合外部 KV、Hive 等多个组件,复杂度高,运维成本高 | 将维表、关联、批查等操作在内部收敛,架构简洁 |
02、落地实践
接下来以两个具体的实际场景为例,介绍整体的落地实践。
2.1 长周期指标聚合计算场景-背景介绍
首先考察长周期指标聚合场景的计算。当主播直播后,希望查看当前直播间的举报人数指标,从而优化其直播间内容。
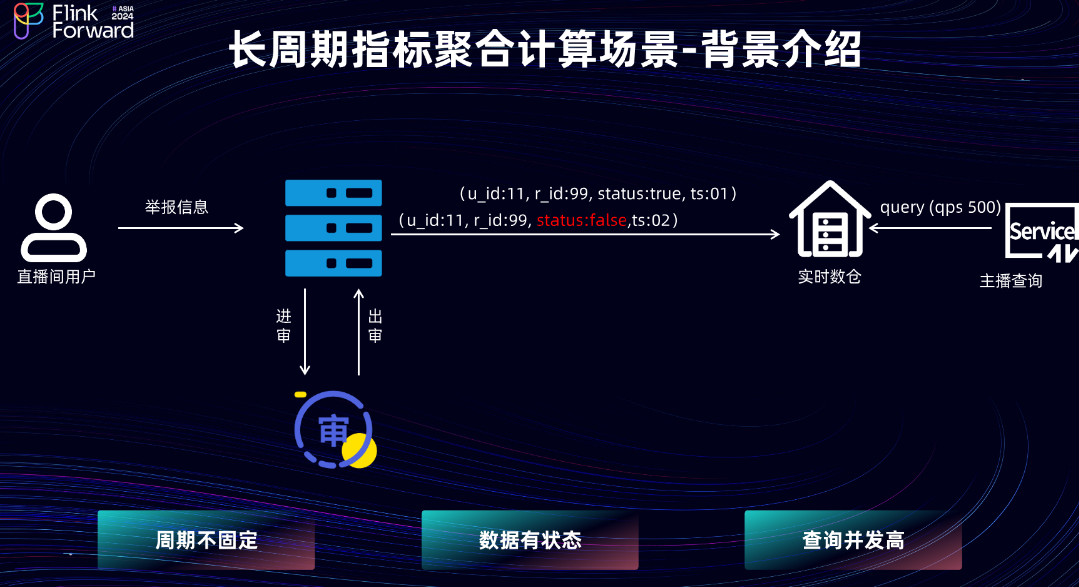
当用户对直播间进行举报后,其举报信息默认处理成功,此时信息会写入业务库,并提交至审核队列。当审核完成后,会修改业务库中的状态。但是,审核完成时间不固定,可能为 30 天,甚至更久。实时数仓通过消费业务库的 Binlog,计算直播间维度的用户举报指标,最后通过指标服务对外提供查询。在当前场景中,查询的 QPS 在 500 左右。
2.2 长周期指标聚合计算场景-方案演进
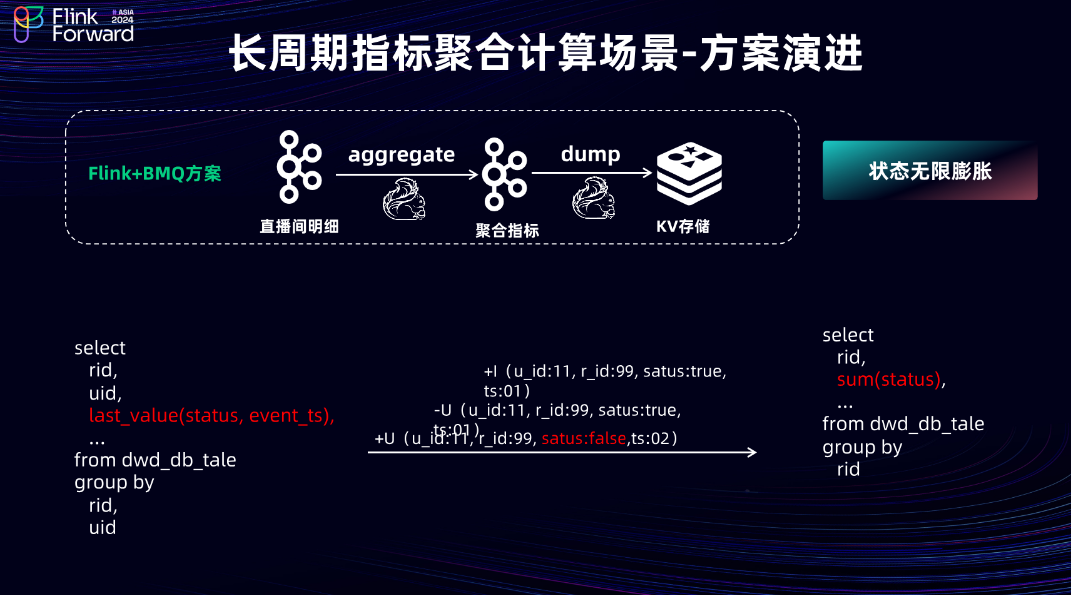
当前场景的架构演进过程。首先,在 Flink + MQ 架构中,当前场景的消息类型为 Changelog。因为 MQ 并不支持传递 Changelog 类型数据,所以在指标计算之前,需要按照用户粒度 + 直播间粒度,使用 Last_Value 等聚合函数手动构建 Retract 消息,再根据直播间 ID 聚合,得到直播间的用户举报人数。在此过程中,Flink 链路会产生大量的 Keyed State,并且由于审核完成时间不固定,无法确定状态到底需存储多久,这导致 Flink 任务中的状态会线性膨胀,引发任务不稳定。
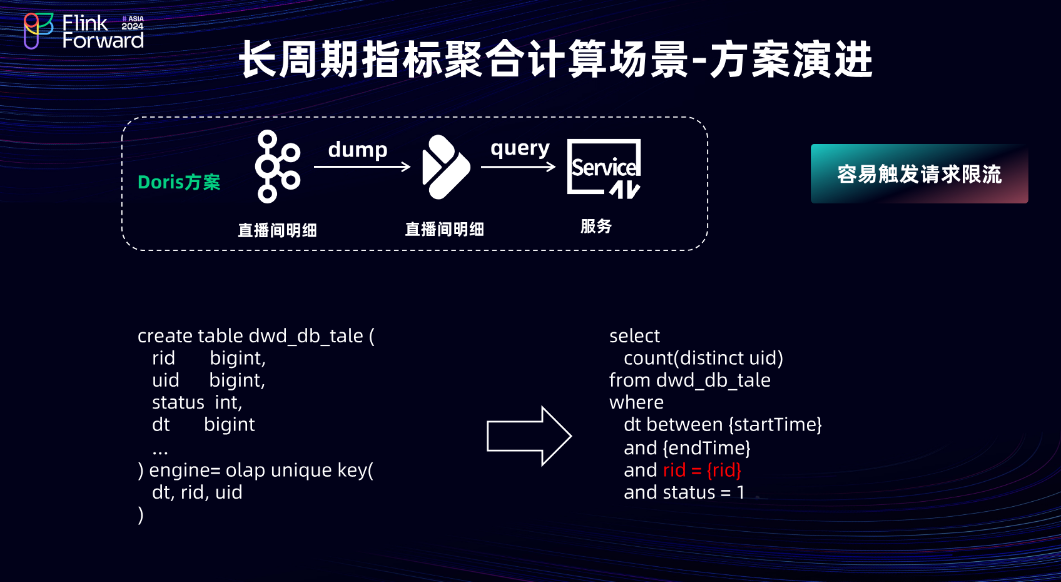
最终,团队采用 Doris 方案实现,将用户的举报明细直接写入 Doris 的明细表中,在查询服务层实现整体的计算逻辑。根据主播 ID 和直播间的开播/关播时间,点查 Doris 明细表,解决了 Flink + MQ 链路中的大状态问题。但是,为保障 Doris 集群的整体稳定性,对接口进行了限流,将限流阈值设置为 150 QPS。因此,当查询遇到高并发时,经常会触发限流,影响用户的查询体验。
2.3 长周期指标聚合计算场景-paimon 方案

基于以上问题,使用 Paimon 对此链路进行了重构。在 Paimon 链路中,DWD 层直接创建一张以用户 ID、房间 ID 和日期为主键的 Paimon 主键表,并且设置 'changelog-producer' = 'lookup'。在 DWS 层,创建一张以直播间 ID 为主键的聚合表。在 Flink 任务中,只需进行比较简单的操作,将原布尔类型的状态字段转换为 Int 类型的 0 和 1,并直接写入聚合表中,这样便会得到直播间粒度的聚合指标。最后,将计算好的指标写入外部的 KV 存储中,对外提供查询。
2.4 长周期指标聚合计算场景-业务收益
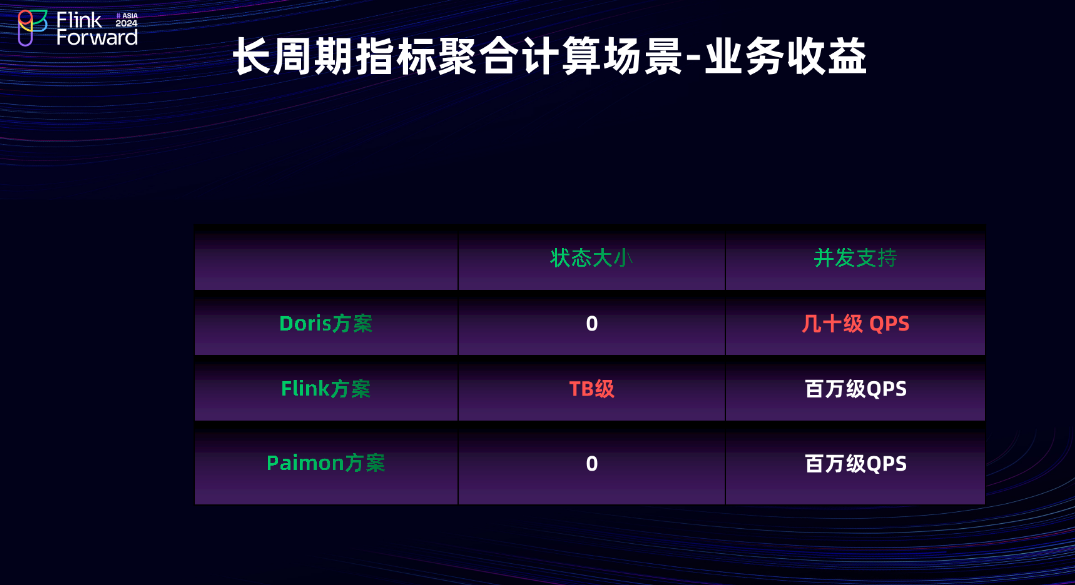
Paimon 方案整体解决了 Flink 方案中的大状态问题,因为其将 Flink 中的状态计算下沉到了 Paimon 存储层,所以 Flink 任务状态几乎可以忽略不计。其次,因为和 Flink 方案一样借助了外部的 KV 存储,所以其查询并发可达到百万级别。
2.5 大流量端到端场景-业务背景
接下来考察大流量端到端的场景。内部运营希望查看短视频内容的消费指标,从而及时调整其经营策略。但是,由于原始的短视频指标和数据并未携带游戏相关信息,所以需要接入全量的短视频数据,并关联游戏属性,才能计算游戏场景下的短视频聚合指标。最大的挑战在于,全量短视频数据在峰值的 RPS 可达到 800 万左右,这在进行维度关联时带来了巨大的挑战。
2.6 大流量端到端场景-方案演进
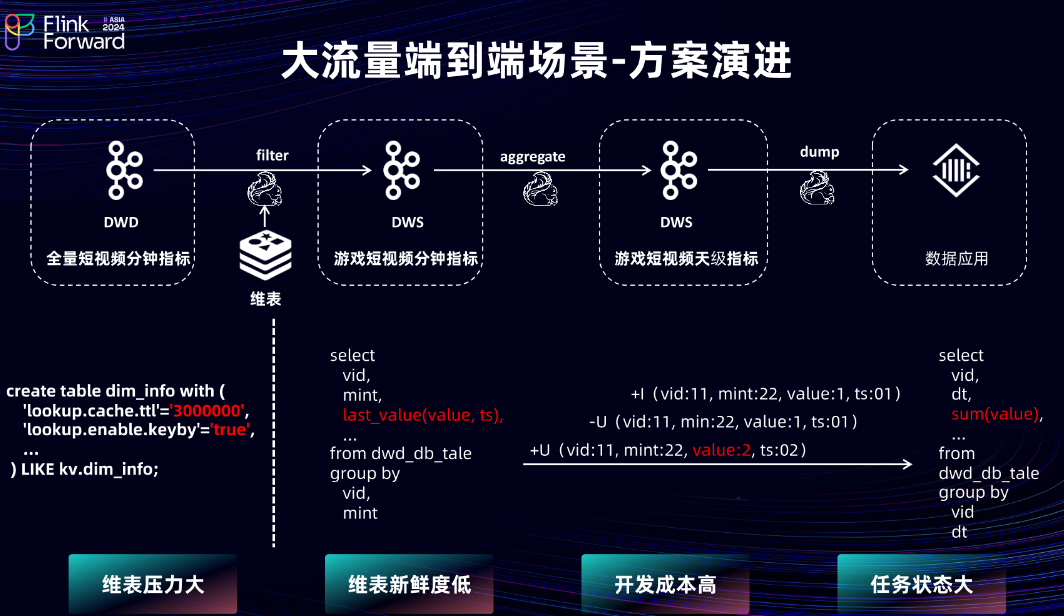
接下来审视整体的方案演进。首先,采用 Flink + MQ 的方式实现。为避免重复开发,在 DWD 层直接接入短视频团队的视频分钟指标。在 DWD 层,通过 Lookup Join 的方式直接关联外部 KV 存储,从而获取游戏相关信息。但由于全量的短视频分钟指标在峰值时达到 800 万 RPS 左右,所以在 Flink 中将 lookup.cache.ttl 设置为 50 分钟,并且开启 Keyed State,以使整体的缓存命中率保持在 90% 以上。尽管如此,穿透到外部 KV 存储的流量在峰值时依然可达到 40 万/秒。
接下来审视 DWS 层。为避免多次关联游戏维表,DWS 层基于分钟指标再次聚合上升到天粒度。因为分钟指标是不断变化的,其数据类型也是 Changelog,但由于 MQ 不支持 Changelog 类型,所以在这里继续使用 Last_Value 在 Flink 任务中构建 Retract 消息。在短视频的指标任务中,按照视频 ID 和日期进行上卷,最终得到短视频粒度的指标。但此过程会产生大量的 Keyed State,导致状态变得非常大,使任务不稳定。
2.7 大流量端到端场景-Paimon 方案
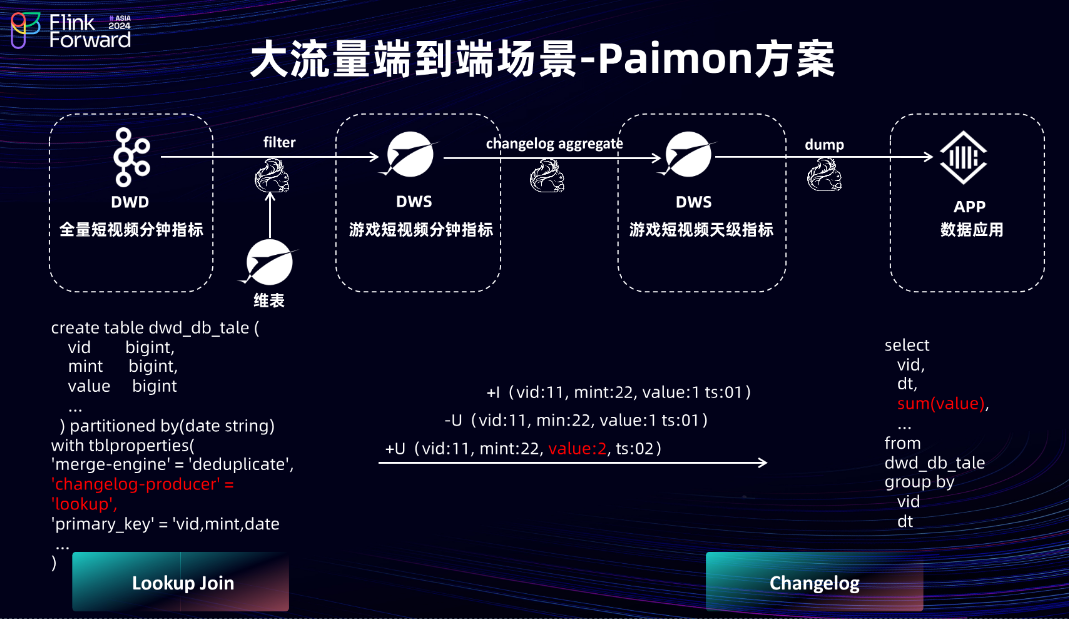
为解决以上问题,使用 Paimon 对此方案进行重构。首先,将原 KV 存储中的维表迁移至 Paimon 维表。因为 Paimon 的底层数据基于 LSM-Tree 结构存储,所以它天然支持大流量、高并发场景的点查。并且由于维表的数据量平均在 7000 万左右,所以将维表的 Flink Checkpoint 间隔设置为一分钟。因此,当前维表的数据新鲜度基本上可以做到两分钟以内。短视频分钟指标则直接创建一张 Paimon 主键表,并设置 Changelog Producer 为 Lookup 形式。这样,DWS 层可以直接消费分钟指标的 Changelog,并按照短视频 ID 和日期直接进行上卷和聚合,从而在 Flink 任务中减少 Keyed State 的产生,降低状态大小。
2.8 大流量端到端场景-业务收益

当前 Paimon 方案的收益如下:
-
维表服务请求:Paimon 直接在内部通过远端拉取数据到本地的方式进行 Lookup Join,因此没有外部请求。
-
灵活查询方面:在 Flink + MQ 链路中,无论是 MQ 还是 KV 存储,都不支持灵活查询。但在 Paimon 链路中,Paimon 既可以支持点查,也可以支持 OLAP 查询,其查询灵活度更高。
-
维表数据新鲜度:之前为保证缓存命中率在 90% 以上,将
lookup.cache.ttl设置为 50 分钟,这使得 KV 存储的维表数据新鲜度为 50 分钟。在 Paimon 表中,因为 Checkpoint 设置为一分钟,可以将整体维表的数据新鲜度从 50 分钟提升至两分钟以内。 -
状态大小:之前为处理 Flink + MQ 链路中的 Changelog 数据类型,引入了非常多的 Keyed State,而在 Paimon 链路中,由于直接支持 Changelog 消息类型,状态大小从 TB 级降低至百 GB 级别。
03、未来展望
最后看未来展望。

-
基于 Session 集群,探索小流量作业下的可扩展、低成本解决方案。因为目前有许多小流量的 Flink 作业是以 Application 模式运行,这会导致其一直占用资源。希望通过 Flink Session 集群能够实现资源共享,以达到降低资源成本的目的。
-
探索 TB 级的维表高性能同步方案。因为在使用 Paimon 的过程中发现一个痛点:Paimon 维表在冷启动或节点迁移时,需从远端同步数据至本地,该过程非常缓慢。并且在某些大流量、大维表的场景下,当前 Paimon 方案难以解决此问题,所以期望通过其他方式探索 TB 级的维表高性能同步方案。
-
将继续利用 Partial Update、Tag 和 Branch 等能力完成落地实践,以解决业务中的多流列式拼接以及数据回溯等问题。
更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动: 新用户复制点击下方链接或者扫描二维码即可0元免费试用 Flink + Paimon 实时计算 Flink 版(3000CU*小时,3 个月内) 了解活动详情:https://free.aliyun.com/?utm_content=g_1000395379&productCode=sc

</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


