
<p>作者:范阿冬(无哲)</p> JSON 格式因其灵活、易扩展、可读性强等特点,是日志数据中非常常见的格式之一。然而海量的 JSON 日志也给高效分析带来了挑战。本文将系统性地介绍在阿里云日志服务(SLS)中处理和分析 JSON 日志的最佳实践,帮助你从看似无序的数据海洋中精准、快速地挖掘出核心价值。
一、 数据预处理:从源头奠定高效分析的基础
对于结构相对固定的 JSON 日志,最佳策略是在数据进入存储之前就将其”拍平”(Flatten),即将嵌套的 JSON 字段展开为独立的、扁平化的字段。
这样做的好处显而易见:
- 查询性能更优:避免了在每次查询时都进行实时解析,直接对独立字段进行分析,速度更快,效率更高。
- 存储成本更低:消除了 JSON 格式本身(如大括号、引号、逗号)带来的冗余,有效降低存储开销。
SLS 提供了多种在数据写入前进行预处理的方式:
方式一:采集时处理(推荐 Logtail 用户)
如果你使用 Logtail 进行日志采集,可以直接利用其内置的 JSON 插件。该插件能在采集阶段就将 JSON 对象解析并展开为多个独立字段,从源头实现数据规整化。如果日志中只有部分字段是 JSON 字符串,也可以结合 SPL 语句在插件中对特定字段进行处理。
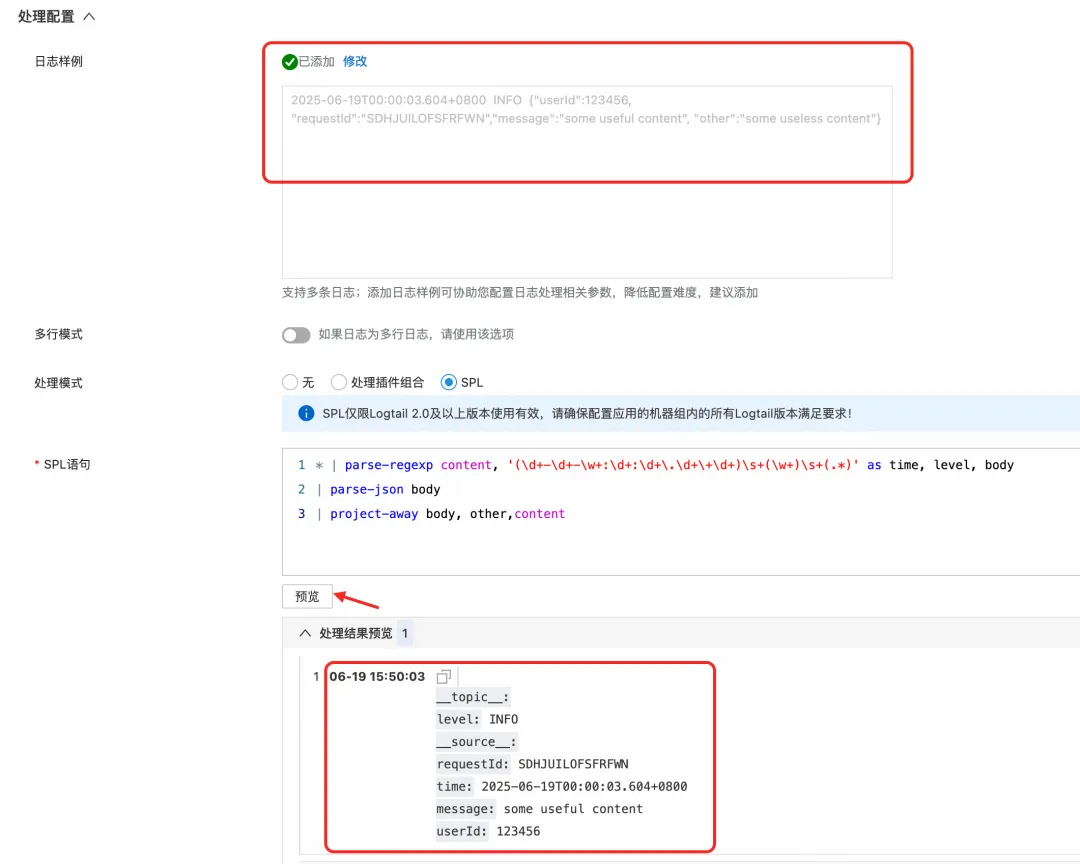
方式二:写入时处理(写入处理器)
当日志来源多样(例如,除了 Logtail 还有 API、SDK 等),或者你无法控制采集端的配置时,可以在 SLS 的 Logstore 上配置一个写入处理器(Ingestion Processor)。所有写入该 Logstore 的数据,在落盘前都会经过处理器的统一加工,同样可以实现 JSON 的展开。这提供了一个集中、统一的数据治理入口。
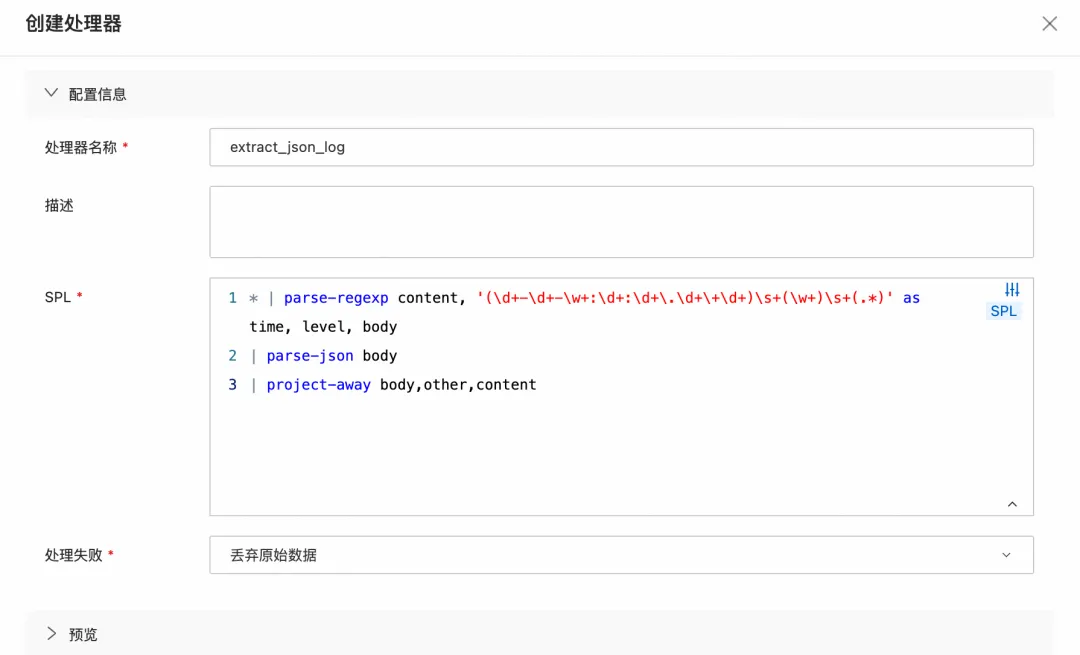
方式三:写入后处理(数据加工)
如果 JSON 日志已经存入 Logstore,也无需担心。可以通过数据加工任务,读取源 Logstore 的数据,使用 SPL 进行处理,然后将加工后的结构化数据写入一个新的 Logstore。这对于历史数据的清洗和归档非常有用。
无论选择哪种方式,强大的 SPL 都是你处理 JSON 数据的核心工具,它能轻松完成展开、提取、转换等各类操作,为后续的高效分析铺平道路。
二、 配置索引:在保留结构与查询性能间找到最佳平衡
虽然”拍平”存储是理想状态,但有时我们希望保留字段原始的 JSON 结构,以便更好地反映日志的层级关系。同时我们还是需要能够进行灵活的查询分析。
你可以为 JSON 字段本身创建 JSON 类型索引,并针对其中最常用的叶子节点路径(如 Payload.Status)单独创建子节点索引。这样,既保留了 Payload 字段的完整 JSON 结构,又能像查询普通字段一样,直接对高频子节点进行高速查询和分析。
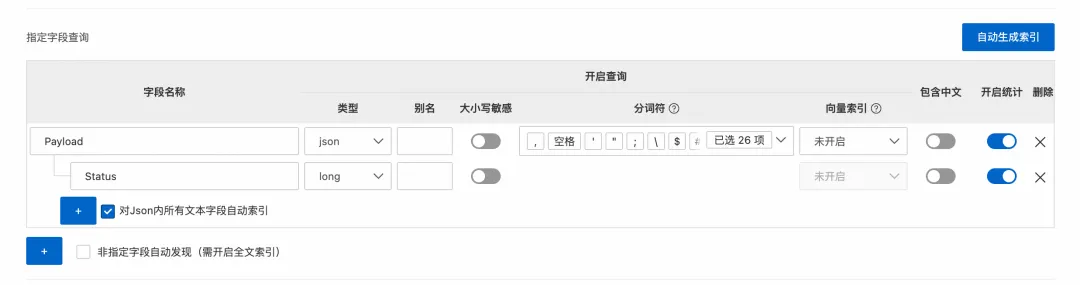
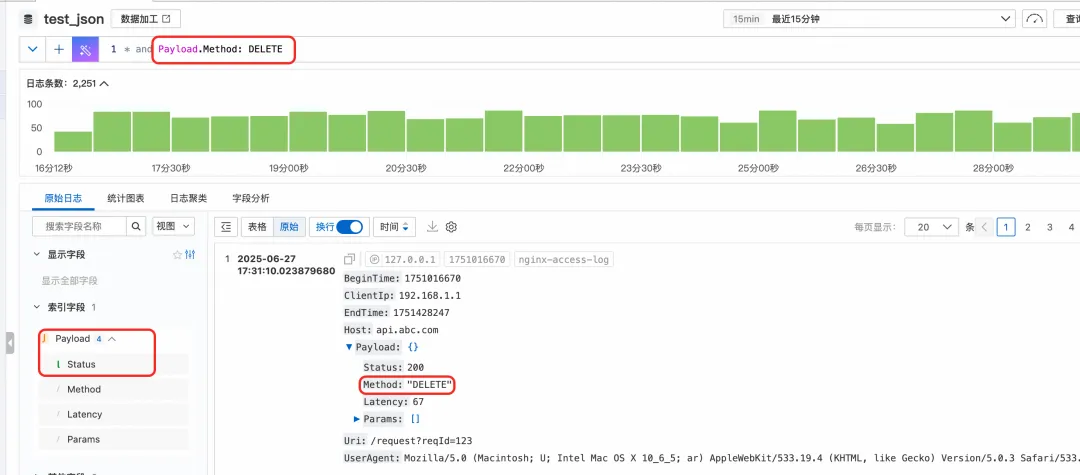
那如果想创建的字段太多怎么办?可以勾选上”对 Json 内所有文本字段自动索引”,这样所有的 JSON 的文本类型的子节点会自动加上索引,可以直接查询。比如这里,我们在索引配置里面并未给 Method 子节点显示添加索引,但是可以对 Payload.Method 直接进行关键词查询。
三、 JSON 函数:深入 JSON 内部的瑞士军刀
前面介绍了可以为 JSON 的子节点添加索引,然后直接分析,但是有些情况下我们无法或者不便添加子节点索引:
(1)JSON 对象包含的字段不确定,无法事先枚举
(2)对于 JSON 数组,或者 JSON 对象的中间节点,这些是不能单独建立索引的
SLS 强大的 JSON 分析函数便派上了用场。它们允许你在 SQL 查询中对 JSON 数据进行实时、灵活的深度分析。
json_extract vs. json_extract_scalar 选择合适的武器
这两个函数是 JSON 提取的基础,但用途不同:
json_extract(json,json_path):返回一个 JSON 对象或 JSON 数组。当你需要对 JSON 结构本身进行操作时(如计算数组长度),应使用此函数。json_extract_scalar(json,json_path):返回一个标量值(字符串、数字、布尔值),但其返回类型始终是varchar(字符串)。这是最常用的函数,用于提取字段值进行分析。
注意:使用 json_extract_scalar 提取数值进行计算时,需要先用 CAST 函数将其转换为数值类型。
* | select
json_extract_scalar(Payload, '$.Method') as method,
avg(
cast(
json_extract_scalar(Payload, '$.Latency') as bigint
)
) as latency
group by
method
在什么场景下使用 json_extract 函数呢?
当我们需要对 JSON 对象结构本身进行一些分析处理的时候。比如下面这个日志样例,Payload 是 JSON 日志字段,它有一个 Params 子数组,数组中又是一个个的 JSON 对象。
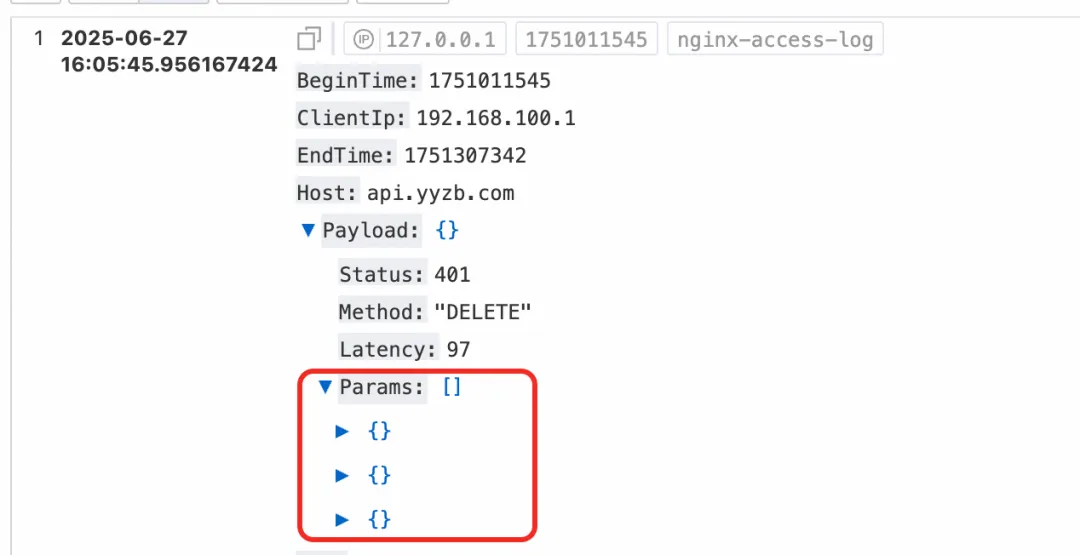
假设我们现在要分析每一条日志中的 Params 数组的平均长度,这个就是在分析 JSON 数组,就需要用 json_extract 函数先把数组提取出来,再用 json_array_lenth 函数去求数组的长度,然后再求平均值。
* | select
avg(
json_array_length(json_extract(Payload, '$.Params'))
)
json_extract_long/double/bool:告别繁琐的类型转换
json_extract_scalar 的返回值始终是 varchar 类型,这意味着在进行数值计算前,必须使用 CAST 函数进行转换。这不仅增加了 SQL 的复杂度,还会带来额外的性能开销。
为了简化查询并提升性能,SLS 提供了类型预置的提取函数。它们可以直接提取指定类型的值,省去了 CAST 操作。
json_extract_long(json,json_path): 提取为 64 位整型json_extract_double(json,json_path): 提取为双精度浮点型json_extract_bool(json,json_path): 提取为布尔型
例如前面的例子中的
cast(json_extract_scalar(Payload, '$.Latency') as bigint) as latency
可以简化成
json_extract_long(Payload, '$.Latency') as latency
json_path:玩转 JSON 路径,精准定位
使用 json_extract 或者 json_extract_scalar 等函数从 JSON 数据中提取的时候,需要指定 json_path 字段,用来表明需要提取 JSON 中的哪一部分。
json_path 的基本格式是类似”$.a.b”,$符号代表当前 JSON 对象根节点,然后通过”.”号引用到要提取的节点。
- 那如果 JSON 的 key 值本身是 a.b 的形式呢?
比如 Payload 有一个子节点的名字是 user.agent,这种情况下可以用中括号[]代替.号,中括号里的节点名称要用双引号括起来。
* | select json_extract_scalar(Payload, '$.["user.agent"]')
- 那如果是要获提取 JSON 数组中的某个元素呢?
这种情况下,也可以用中括号[],中括号中用数字来表示数字下标,下标从 0 开始。
* | select json_extract_long(Payload, '$.Params[0].value')
JSON 数组分析:unnest 帮你”化繁为简”
当单个日志条目中包含一个项目列表(即 JSON 数组)时,一个常见的分析需求是将数组展开,对其中每个元素进行聚合分析。unnest 函数正是为此而生,它可以将数组中的每个元素抽出来作为独立的行。
日志样例
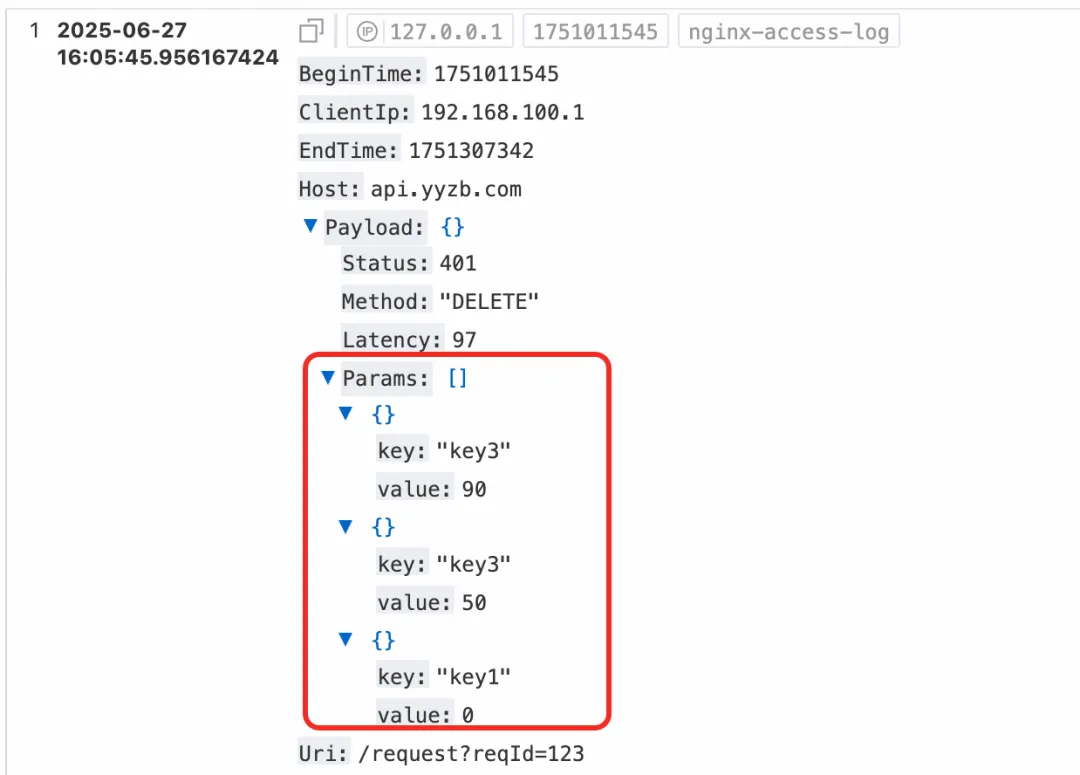
* | select
json_extract_scalar(kv, '$.key') as key,
avg(json_extract_long(kv, '$.value')) as value
FROM log,
unnest(
cast(json_extract(Payload, '$.Params') as array(json))
) as t(kv)
group by
key
执行结果
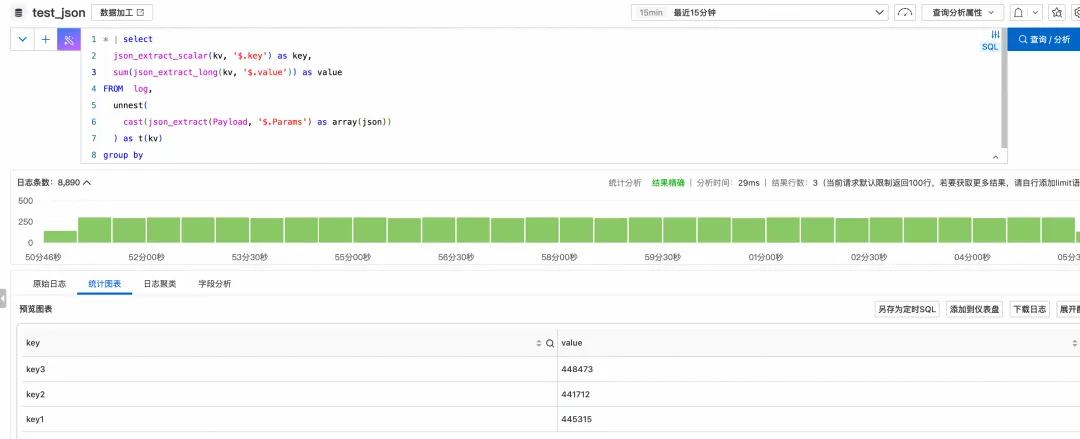
执行过程解析:
json_extract提取出Params数组。CAST(... AS array(json))将其转换为 SLS 可识别的 JSON 数组类型。UNNEST(...) AS t(kv)将数组展开,每一行中的kv列都是原数组的一个元素(一个 JSON 对象)。- 最后,我们就可以对
kv应用json_extract函数,并进行分组聚合了。
四、SQL Copilot:智能生成 SQL 语句
面对复杂的分析需求,手写 SQL 不仅耗时,还容易出错。阿里云 SLS 内置的 SQL Copilot 功能,彻底改变了这一现状。你只需用自然语言描述分析目标(例如:”展开 Payload 中的 Params 数组,按 key 分组计算 value 的平均值”),Copilot 就能自动为你生成精准的 SQL 查询语句。
这意味着你可以将更多精力聚焦于”分析什么”,而非”如何查询”。
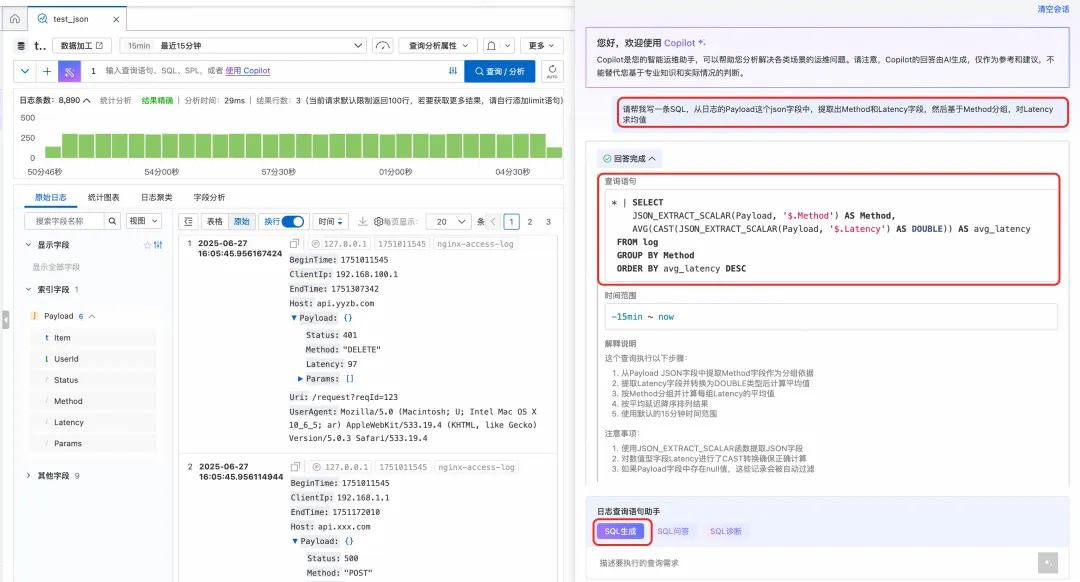
实践建议:在分析之初,不妨先用 SQL Copilot 生成基础查询,再根据具体需求进行微调和优化,事半功倍。
总结与展望
高效分析 JSON 日志是一个系统工程,SLS 为此提供了从数据入口到查询分析的全链路解决方案:
- 数据规整化优先:若条件允许,通过采集插件、写入处理器或数据加工在写入前将 JSON 展开,是实现高性能、低成本分析的最佳途径。
- 善用索引:对于以 JSON 格式存储的日志,为高频访问路径创建子索引,或开启自动全文索引,是加速查询的关键。
- 掌握核心函数:在需要实时、灵活分析时,熟练运用
json_extract系列函数、unnest等 JSON 分析函数,它们是你深入数据内部的强大武器。 - 拥抱 AI 能力:借助 SQL Copilot,让自然语言成为你与数据对话的桥梁,极大简化分析过程。
掌握这些方法与技巧,你将能够从容应对各种复杂的 JSON 日志分析场景,真正将海量日志数据转化为驱动业务决策的宝贵资产。
点击此处,查看日志服务 SLS 产品详情
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


