维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道!
“缓存搞定了、异步也安排了,RAG 终于跑得飞快……但它真的能看懂图了吗?”
🙋♀️ “PDF 里的图表,怎么总像谜语人?”
🙋♂️ “论文里密密麻麻的公式,是让人看,还是让人头疼?”
别急,前面几讲我们刚把 RAG 提速到起飞,这次——直接上天看图表!
第13、14讲,火力全开攻克“多模态”难题,聚焦如何让 RAG 看图识表、解读论文、图文并茂输出高质量答案!
为什么要引入多模态?
- 现实痛点:合同、论文、产品手册中,50%关键信息藏在图表里(如论文实验数据、财报统计图)
- 传统局限:纯文本RAG处理PDF时,图片=空白,表格=乱码(全靠OCR硬扛,效果看命💔)
- 解法:引入多模态大模型(MLLM),让AI像人类一样图文协同理解
基本原理
| 层级 |
核心任务 |
技术方案 |
关键突破 |
| 感知层 (特征提取) |
多模态→统一向量化 |
• 图像:CNN/ViT • 音频:频谱Transformer • 文本:BERT/GPT • 视频:帧序列编码 |
打破模态壁垒 异构数据统一表达 |
| 对齐层 (语义映射) |
跨模态语义关联 |
• • • |
建立“猫图”=“猫”的语义等价性 |
| 理解层 (推理生成) |
多模态协同推理 |
• LLM整合信息→语言建模驱动 • 输出:图文/音视频多态内容 • 任务:问答/描述/创作 |
实现“看CT说病情”类人认知 |
多模态智能 = 特征编码 ⊕ 语义对齐 ⊕ 语言推理(⊕ 代表跨模态融合运算符)
模型架构
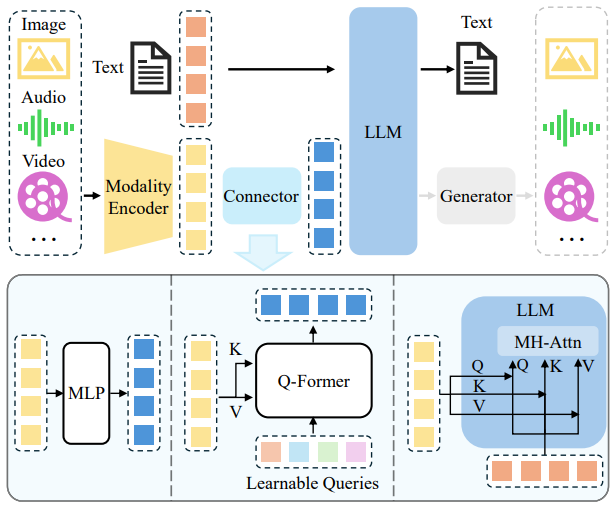
模态编码器(Modality Encoder)
⚒️作用:将不同模态的数据(如图像、音频、视频、文本)转为向量表示(embedding)
📌特点:每种模态使用专门模型编码
-
图像:CNN / ViT
-
音频:语音模型(如 Whisper)
-
文本:语言模型(如 BERT / T5)
连接器(Connector)
⚒️作用:将非文本模态的向量,对齐到文本 embedding 的语义空间,解决“语义壁垒”问题
📌常见连接方式:
-
MLP 映射:简单高效,常用于基础场景
-
Cross-Attention 映射:复杂任务下模态间深度交互的利器
-
模型内部融合:将图像 patch 和文本 token 混合输入,底层结构级融合(如 Flamingo、BLIP 模型)
语言模型(LLM)
⚒️作用:接收已对齐的统一向量,完成理解和生成任务
📌能力体现:
-
图文问答
-
多模态总结
-
推理与生成
主流开源模型
🎯 判别式范式(Discriminative Paradigm):以 CLIP 为代表,侧重于学习图文匹配与对齐,主要用于图像分类、检索等任务;
🧙♂️ 生成式范式(Generative Paradigm):以 OFA、VL-T5、Flamingo 等为代表,强调跨模态生成,如图像描述、视觉问答等。
在LazyLLM中使用多模态大模型
代码实现
import lazyllm
chat = lazyllm.OnlineChatModule(source="glm", model="glm-4v-flash")
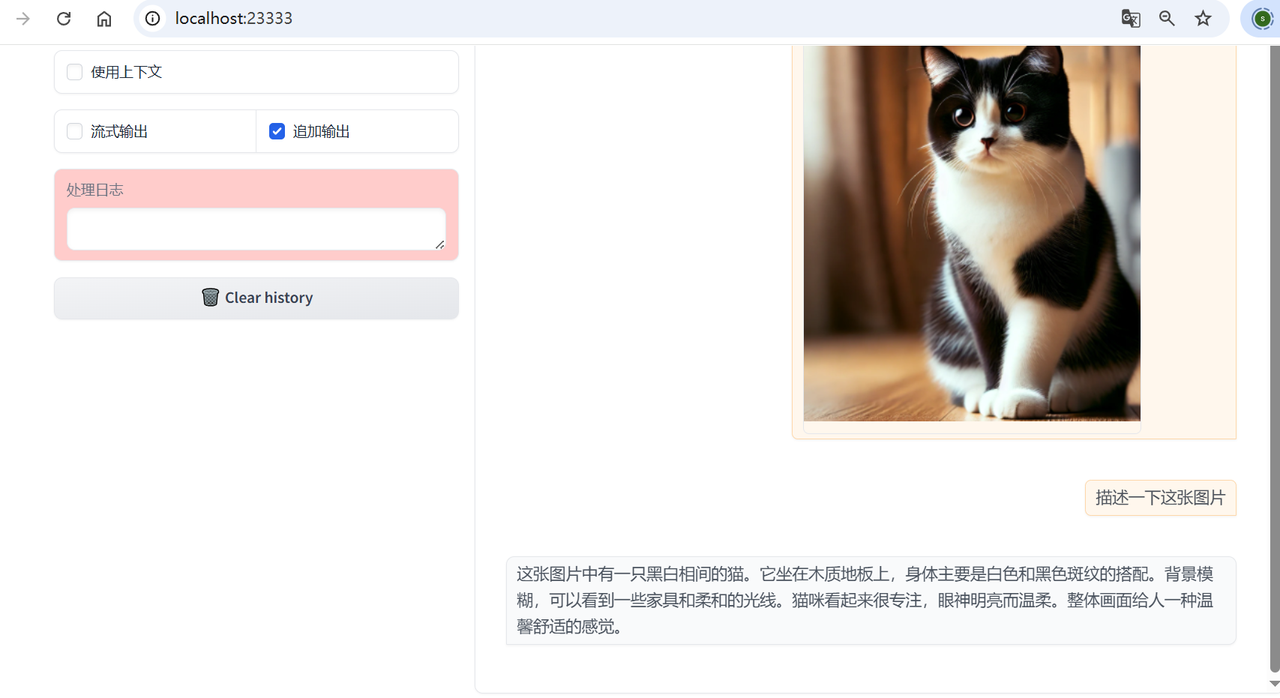
lazyllm.WebModule(chat, port=23333, files_target=chat).start().wait()效果展示
多模态RAG揭秘
整体架构
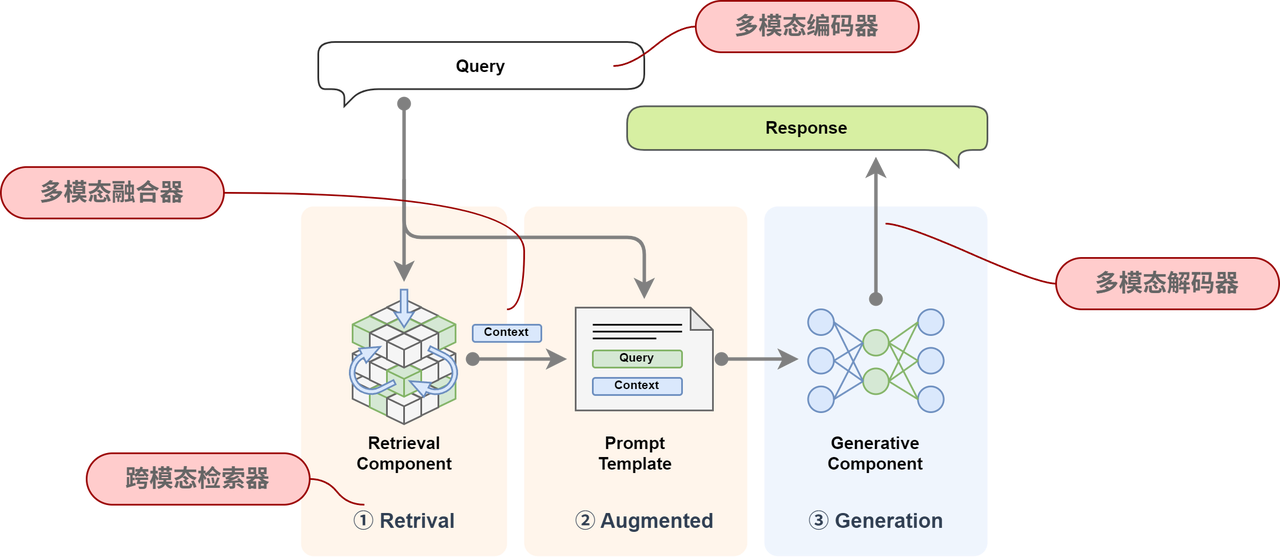
🧩 修改的模块包括:
- 检索模块:原本仅支持文本检索,现在需要扩展为支持多模态检索,例如图像、音频等信息的索引和匹配。
- 生成模块:原始 RAG 仅针对文本生成,现在需要扩展支持多模态输出,如文本结合图像、音频的生成能力。
核心组件
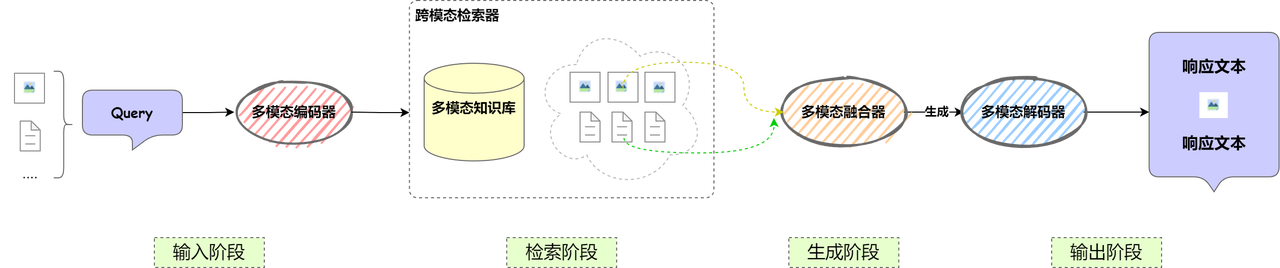
🌉 在原有组件上新增以下组件:
| 组件 |
功能 |
| 多模态编码器 |
用于对不同模态的数据(文本、图像、音频等)进行编码,以便统一表示并用于检索和生成。 |
| 多模态融合器 |
用于融合不同模态的信息,使其能够协同作用,提高生成内容的准确性和丰富度。 |
| 跨模态检索器 |
支持输入多种数据格式,并能在多模态知识库中找到相关信息。 |
| 多模态解码器 |
负责将生成结果解码为多种形式,如文本、图片、语音等,以适应不同的输出需求。 |
基于 PDF 文档的多模态 RAG
基于OCR文档解析的图文RAG系统流程包括文档解析、多模态嵌入以及查询与生成三个关键步骤。
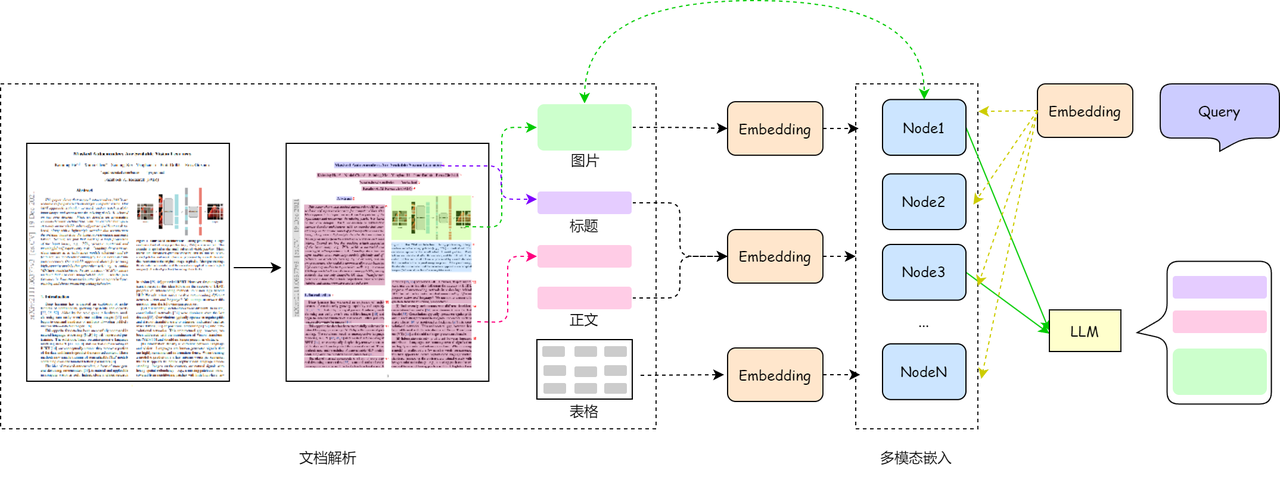
文档解析
1️⃣ PDF 是啥?
- 一种跨平台、排版固定的文档格式,支持文本、图片、表单、视频等内容,广泛用于办公和学术场景。
2️⃣ 两种常见 PDF 类型:
- 机器生成型:内容可选中、可搜索,适合直接用工具解析。
- 扫描生成型:本质是图片,需 OCR 技术识别文字。
3️⃣ 怎么解析?
- 机器 PDF:可用
pdfminer、pdfplumber等 Python 工具提取结构化文本、表格等信息。 - 扫描 PDF:需用 OCR 工具(如 Tesseract、PaddleOCR)识别文字,复杂场景可用 LayoutLM 等深度模型提升识别效果。
4️⃣ 结构保留也很重要:
- 仅提取文本远远不够,文档的段落结构、标题层级、表格排版等信息对语义理解同样关键,因此还需要布局分析(如使用 LayoutLM 等模型)。
5️⃣ 推荐工具:magic-pdf
- 集成了文本提取、结构恢复、表格/公式分析等功能,一站式解析 PDF,为多模态理解打好基础。
多模态嵌入
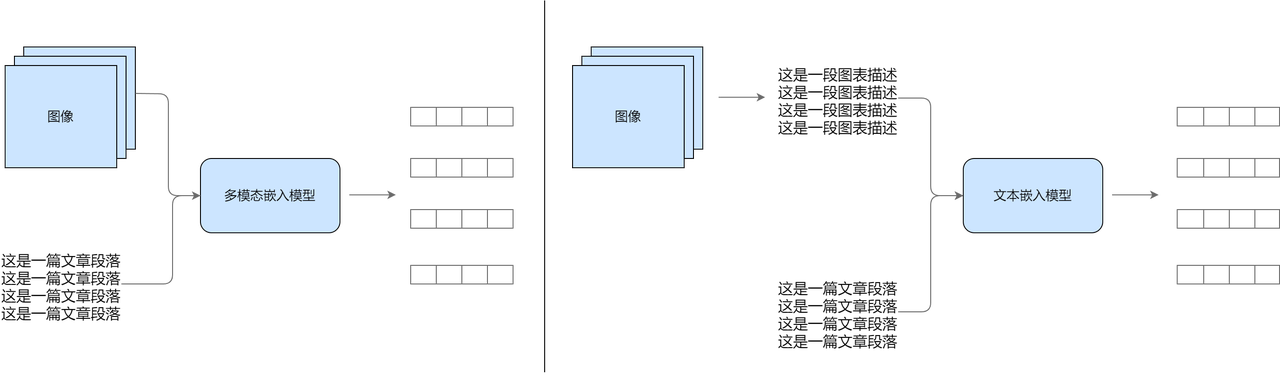
左侧为利用多模态模型进行映射方法,右侧为统一数据模态后进行向量嵌入方法
1️⃣ 直接嵌入统一空间
- 用多模态模型(如 CLIP、VisualBERT)将图像、文本一同编码进同一个向量空间,实现语义对齐。适用于图文结合的检索和生成任务,保留原始模态信息更完整。
2️⃣ 先转文本再嵌入
- 图像、表格等非文本内容先转成文本(比如描述语句或结构化语言),再用文本嵌入模型处理。可复用成熟文本工具,但可能损失部分细节。
两者选择取决于:
- 想保留原始信息 → 用第一种;
- 侧重统一处理流程 → 选第二种。
无论哪种方式,都可与文本 RAG 兼容,修改入库流程即可实现最基础的多模态 RAG。
🖼️ 图片自动生成问答对
借助如 InternVL-Chat 这样的多模态大模型,图片中的关键信息(标题、数据、趋势等)可被自动提取,并生成相关问题与答案,帮助系统理解图像内容、补足文档信息。比如看图秒懂论文结论,不再靠猜。
生成图文并茂的响应
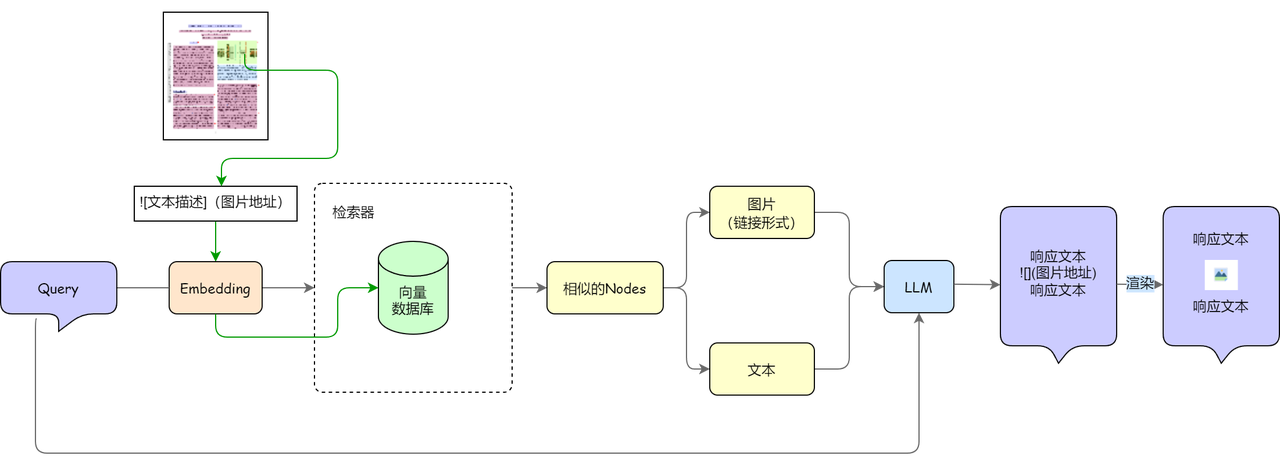
- 图表格式化保存:解析文档时提取图像及其描述,并以 Markdown 格式保存(如:
),方便后续展示。 - 节点类型分类:检索返回结果后,识别哪些是图像节点,为生成环节做好准备(例如生成图像相关内容或链接)。
- 提示词优化:在生成答案时,加入指令提示大模型:如果涉及图像内容,需输出对应链接和解释说明。
多模态内容向量化效果优化技巧
文本补全:结合图像标题与注解等文本信息
- 策略:将图像描述 + 标题 + 图注 拼接后,送入联合编码模型(如 CLIP)统一向量化。
- 示例及效果:

结构化生成:预先从多模态数据中提取 QA 对
- 策略:
- 用 OCR、图像解析等提取关键信息;
- 调用大模型生成 QA 对或摘要,补充至向量库。
- 示例:


