维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道!

<div> 一、背景
随着AI辅助编程工具的普及,Cursor IDE已经成为越来越多开发者的选择。然而,在实际使用过程中,我们发现了一个关键问题:如何让AI真正理解项目需求并生成高质量、一致性的代码?
答案在于构建一套系统化的AI协作规范。与传统的代码规范不同,AI协作规范需要考虑更多维度:
- 如何让AI准确理解业务逻辑和技术要求
- 如何确保生成代码的架构一致性和质量标准
- 如何在团队中推广和维护统一的开发模式
- 如何避免规范冲突和维护成本过高的问题
本文将分享我们在Cursor Rules优化过程中的实践经验,展示如何从混乱的规范体系演进到清晰、高效的AI协作规范架构。
二、旧版Rules痛点
在优化之前,团队已有的规范体系存在三个核心问题,这些问题影响了AI代码生成的质量和效率。
问题一:规则冗余与表述模糊
旧规范存在大量无效描述,包括模糊要求(如”确保高性能”)、重复定义和基础能力提示。这些冗余信息不仅增加token消耗,更分散AI注意力,显著降低代码生成效率。
问题二:提示词冲突
规范中角色定义混乱,不同文档将AI指定为架构师、开发者等矛盾角色。同时缺乏规则优先级机制,导致多规则同时生效时产生行为矛盾,无法形成明确执行路径。
问题三:维护困境
文档职责边界不清,新增规则时难以定位归属文件。修改单一功能需跨多文件调整,且规则间依赖关系不透明,造成维护成本指数级增长。
三、新版Rules设计理念
基于已有问题的深入分析,提出了一套新的设计理念,核心是:分层架构 + 职责分离 + 按需调用。
三层结构设计
新版本采用清晰的三层架构,每层都有明确的职责和边界:
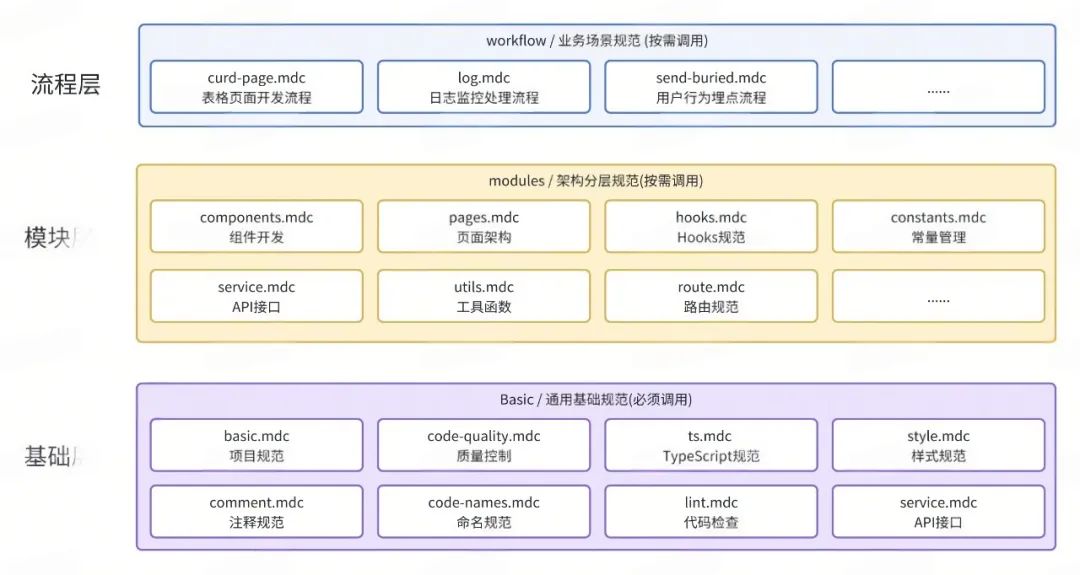

标准化规则格式
为了确保规范的一致性和可维护性,我们定义了统一的规则格式:
# 规则名称
## 基础规范- 明确的技术要求和实现标准
## 强制行为- 必须执行的具体操作和约束
## 禁止行为 - 严格禁止的操作和做法,需要避免的常见错误
## 示例代码- 具体的代码示例和最佳实践- 也通过 [文件名](mdc:路径) 引用外部示例
※ 该格式优势
- 结构清晰:每个部分的职责明确,便于AI理解。
- 可执行性:强制/禁止行为都有明确的操作指导。
- 示例驱动:用实际代码代替抽象描述。
AI协作执行协议
为了确保AI能够正确理解和执行规范,我们设计了一个明确的AI协作协议提示词:


# AI协作执行规则
## 规则分类- basic/下的通用规则: 必须调用,通用基础规范- modules/下的模块规则: 按需调用,架构分层规范 - workflow/下的流程规则: 按需调用,业务场景规范
## 执行流程1. 识别场景 → 调用相关规则2. 读取示例代码 → 作为生成参考3. 执行强制/禁止行为 → 确保代码质量4. 应用设计原则 → 组件化、单一职责、分层设计
## 质量保障- 所有规则必须100%执行,重点关注强制行为和禁止行为
四、三层结构深度剖析
接下来我们详细分析新版本架构的设计特点和技术实现。
基础层的精细化设计
基础层是整个规范体系的根基,我们将原来混乱的MDC文件,精确拆分为7个职责单一的规范文件:
| 文件名 |
职责 |
核心内容 |
| basic.mdc |
项目基础规范 |
目录结构、技术栈、开发流程 |
| code-quality.mdc |
代码质量控制 |
复杂度限制、安全性要求 |
| ts.mdc |
TypeScript规范 |
类型定义、严格模式配置 |
| comment.mdc |
注释规范 |
JSDoc格式、文件头注释 |
| code-names.mdc |
命名规范 |
变量、函数、组件命名约定 |
| style.mdc |
样式规范 |
CSS/Less编写标准 |
| lint.mdc |
代码检查 |
ESLint、Prettier配置 |
※ 此拆分好处
- 职责明确:每个文件只关注一个特定领域。
- 维护便利:修改某个规范不会影响其他领域。
- 学习友好:新人可以逐个理解每个规范的要求。
示例:code-quality.mdc定义了代码质量分规范:
# 代码质量分规范(通用规则)
## 强制行为
- 所有请求必须采用 HTTPS 协议- 确保第三方库安全可靠
## 禁止行为
- 代码复杂度限制 - 单个文件不得超过 500 行 - 条件复杂度不得超过 10 - 单个函数不得超过 199 行 - 超过限制时,应优先按功能模块拆分为多个函数或文件- 禁止使用非得物域名的外部 CDN 资源- 禁止在代码中包含明文密码或硬编码 token- 禁止出现敏感词- 避免重复代码块- 不允许单词拼写错误或不符合命名规范- 避免在前端直接进行金额计算(导致精度丢失)- 禁止使用魔数(如 a === '3'),应使用常量(如 a === statusMap.login)
模块层的分层设计
模块层的设计遵循前端分层架构思想,将复杂的应用拆分为职责明确的模块:
- 表现层:components.mdc(组件规范)、pages.mdc(页面规范)
- 业务逻辑层:hooks.mdc(状态管理)、utils.mdc(工具函数)
- 数据服务层:service.mdc(API接口)、constants.mdc(配置管理)
- 路由层:route.mdc(路由配置和导航)
示例:服务层规范(service.mdc)规范定义了API接口的标准化开发流程:
# API接口生成规范(模块规则)
## 存放位置规范(按优先级)- [p0] 页面级API:src/pages/{pageName}/services/{modules}.ts- [p1] 全局API:src/services/{modules}.ts- 类型文件:对应的 .interface.ts 文件
## 标准代码模板```import { request } from '@/utils/request';import { UniversalResp } from '@/utils/request-operation';import { IUserListReq, IUserListDataRes } from './interface';
/** * 获取用户列表 * @param data 请求参数 */export const fetchUserListApi = async (data: IUserListReq) => { return request.post<UniversalResp<IUserListDataRes>>( '/api/user/list', data );};```## 强制行为- 使用MCP Server的mooncake_get_api_details工具获取接口详情- 响应数据必须使用UniversalResp<T>泛型包装- 接口命名采用fetch{ApiFileName}Api格式- 类型定义必须完整,包含完整字段注释
流程层的场景化设计
流程层是当前架构的创新点,针对具体业务场景定制化规范,将复杂的业务场景标准化。
| 流程文件 |
业务场景 |
核心功能 |
| curd-page.mdc |
curd页面开发 |
curd页面完整使用流程 |
| log.mdc |
错误监控 |
APM监控和错误日志处理流程 |
| sendBuried.mdc |
数据埋点 |
用户行为埋点的标准流程 |
| …… |
|
|
示例: curd-page.mdc 定义了完整的表格页面开发流程:


※ 该流程确保
- 开发效率:标准化流程减少决策时间。
- 质量一致性:所有表格页面都遵循相同的标准。
- 维护性:统一的结构便于后期维护。
# pro-table生成新页面(流程规则)深入研究代码并理解[insert feature]是如何工作的。一旦你明白了,让我知道,我将提供我的任务给你。
## 工作流程按以下流程进行任务执行,如果评估存在非必须流程,可跳过。- MCP读取接口信息- 从用户输入中提取以下信息: - 列表名称 - 筛选项(需标记hideInTable) - 展示项(需标记hideInSearch) - 操作项 - 工具栏按钮- 评估完整的需求内容复杂度,考虑未来的扩展性,合理设计分层目录结构 - 各个模块保持单一职责,考虑合理的业务组件拆分,避免大量代码都在页面主入口文件 - 使用命令行批量创建目录文件(包含各类文件ts、tsx、less等) - 文件暂不生成代码- 配置页面的路由信息- 生成类型文件,确保所有类型定义清晰- 生成constants文件,定义所需常量- 生成services文件,实现数据服务- 生成所需的 hooks 文件- 生成页面(必需)和components(如需)文件 完成UI层
## 强制行为- 使用pro-table进行开发,包括筛选表单,符合最佳实践- 筛选项和列表项配置创建useColumns.tsx声明,筛选项(需标记hideInTable)、展示项(需标记hideInSearch)- 左侧字段按需固定,操作项右侧固定,最多显示两个,超出折叠显示- 文本左对齐,数字右对齐,状态枚举居中显示- 分页设置支持10、20、50、100- .....
# 禁止行为.....
五、最佳实践
快速开始
第一步:创建基础架构
.cursor/rules/├── ai.mdc # AI协作总纲├── basic/ # 基础规范目录│ ├── basic.mdc│ ├── code-quality.mdc│ ├── ts.mdc│ ├── style.mdc│ ├── comment.mdc│ ├── code-names.mdc│ └── lint.mdc├── modules/ # 模块规范目录│ ├── components.mdc│ ├── pages.mdc│ ├── hooks.mdc│ ├── service.mdc│ ├── constants.mdc│ ├── utils.mdc│ └── route.mdc└── workflow/ # 流程规范目录 ├── curd-page.mdc ├── log.mdc └── send-buried.mdc └── ......
第二步:配置AI协作协议
在 ai.mdc 中定义核心协作规则:
# AI协作执行规则
## 规则分类- basic/下的通用规则: 必须调用,通用基础规范- modules/下的模块规则: 按需调用,架构分层规范 - workflow/下的流程规则: 按需调用,业务场景规范
## 执行流程1. 识别场景 → 调用相关规则2. 读取示例代码 → 作为生成参考3. 执行强制/禁止行为 → 确保代码质量4. 应用设计原则 → 组件化、单一职责、分层设计
## 质量保障所有规则必须100%执行,重点关注强制行为和禁止行为
分阶段实施计划
| 阶段 |
目标 |
关键活动 |
| 试点阶段 |
验证规范有效性 |
选择1-2个项目试点,收集反馈 |
| 优化阶段 |
完善规范内容 |
根据试点反馈优化规范,开发工具 |
| 标准化阶段 |
形成团队标准 |
制定团队级标准,持续改进机制 |
六、总结
基于以下设计思路,并通过构建三层架构的AI协作规范体系:
- 单一职责:每个规范文件只负责一个功能领域,规则维护简单,冲突减少。
- 分层架构:基础→模块→流程的清晰层级,规则依赖明确,扩展容易。
- 按需调用:根据开发场景智能调用相关规范,使得上下文信息精准,效率提升。
- 示例驱动:用代码示例代替抽象描述,AI理解准确,执行到位。
- 持续进化:支持规范的迭代优化和扩展,研发适应变化,持续改进。
我们成功缓解了AI辅助编程中的核心问题,这套方法论不仅适用于Cursor Rules,更可以推广到其他AI协作工具的规范设计中。在AI辅助编程快速发展的今天,构建一套清晰、系统化的协作规范,将是每个开发团队的核心竞争力。
往期回顾
1.一致性框架:供应链分布式事务问题解决方案|得物技术
2.Redis 是单线程模型?|得物技术
3.得物社区活动:组件化的演进与实践
4.得物研发自测 & 前端自动化测试体系建设
5.从CPU冒烟到丝滑体验:算法SRE性能优化实战全揭秘|得物技术
文 / 阳凯
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
</div>

