维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道!

<blockquote> 编者按: AI 编程工具如何迅速检索海量代码库,并精准定位到最相关的代码片段?这个看似不可能完成的任务,却是决定现代 AI 编程工具用户体验的关键技术挑战。
我们今天为大家带来的这篇文章,作者的观点是:Cursor 通过巧妙运用默克尔树数据结构,实现了对大型代码库的快速索引和高效增量更新,这正是其能够提供精准 AI 辅助编程服务的技术基础。
作者 | Engineer’s Codex
编译 | 岳扬
Cursor —— 这家最近宣布斩获 3 亿美元年营收的热门 AI 开发工具 —— 正是利用默克尔树(Merkle trees)实现对代码的快速索引。本篇文章将为你详细介绍其运作原理。
在深入了解 Cursor 的具体实现方法之前,我们先来了解一下默克尔树的基本概念。
01 默克尔树的简单解释
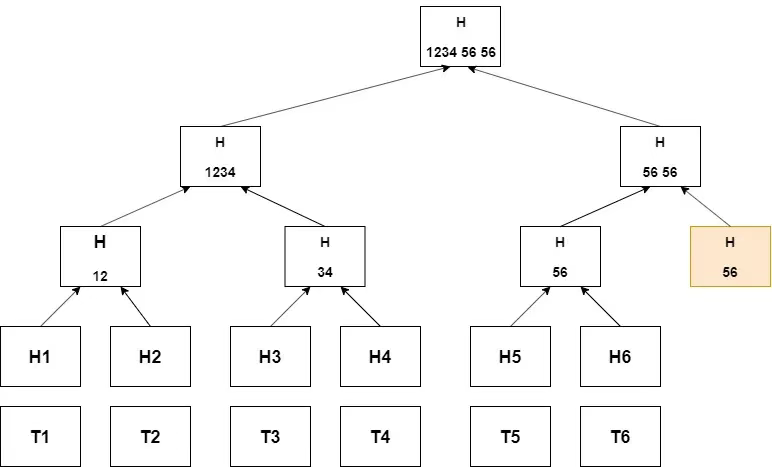
默克尔树(Merkle tree)是一种树状数据结构,其每个”叶”节点都标注了对应数据块的加密哈希值,而每个非叶节点则存储其子节点哈希值组合后的新哈希值。这种层级结构通过比较哈希值,能有效地侦测任何层级的数据变动。
通俗理解,它就像是数据的指纹系统:
1)每份数据(例如文件)都拥有自己独一无二的指纹(哈希值)
2)成对的指纹被组合在一起,生成一个新的指纹
3)此过程层层递进,直至形成唯一的主指纹(根哈希)
根哈希(root hash)概括了所有底层数据块的指纹信息,相当于对整个数据集做了一次加密公证。只要根哈希不变,就能证明原始数据分毫未改。此机制的精妙之处在于:任何一个数据块发生变化,都将牵一发而动全身 —— 改变其上所有层级的指纹,最终彻底改变根哈希值。
02 Cursor 如何利用默克尔树实现代码库索引功能
默克尔树 (Merkle trees) 是 Cursor 代码库索引功能的核心组件。根据 Cursor 创始人发布的帖子[1]和 Cursor 的安全文档[2],其工作流程如下:
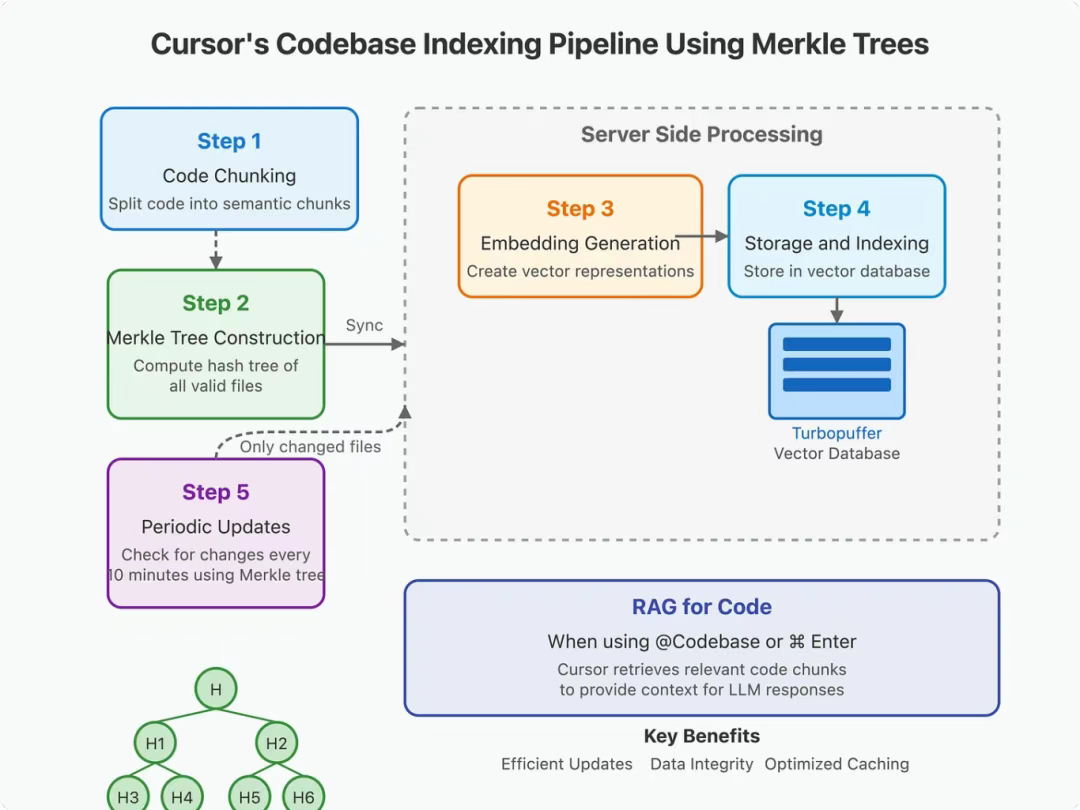
2.1 步骤 1:代码分块与预处理
Cursor 首先在本地对代码库文件进行分块处理,将代码分割成具有语义含义的片段。此步骤是后续操作的必要前提。
2.2 步骤 2:默克尔树的构建与同步
启用代码库索引功能后,Cursor 会扫描编辑器当前打开的文件夹,并为所有有效文件计算哈希值组成的默克尔树。随后,该默克尔树会与 Cursor 的服务器同步,其安全文档[2]详细描述了此过程。
2.3 步骤 3:生成嵌入向量
将代码分块并发送至 Cursor 服务器后,将使用 OpenAI 的嵌入 API 或自研的嵌入模型(我未能验证 Cursor 具体采用的是哪种方法)生成嵌入向量 (embeddings)。这些向量表征能够捕捉代码片段的语义信息。
2.4 步骤 4:存储与索引
生成的嵌入向量,连同起始/结束行号及文件路径等元数据,会被存储在一个远程向量数据库(Turbopuffer)中。为兼顾路径筛选功能与隐私保护,Cursor 会为每个向量附加经过混淆处理的相对文件路径。Cursor 创始人曾明确表示[1]:”我们的数据库中不会存储任何代码。请求处理完毕立即销毁存储的代码数据。”
2.5 步骤 5:基于默克尔树的定期更新
每隔 10 分钟,Cursor 就会检测哈希值的变化情况,利用默克尔树精准定位哪些文件发生了变动。如 Cursor 的安全文档[2]所述,只需上传所定位到的发生变动的文件,从而大幅降低带宽消耗。默克尔树结构的最大价值正体现于此 —— 它能实现高效的增量更新。
03 代码分块策略
代码库索引的有效性很大程度上取决于代码的分块方式。尽管我先前的说明未深入探讨代码分块方法,但这篇关于构建类 Cursor 代码库功能的博客[3]揭示了一些技术细节:
简单的分块方式(按字符/按单词/按行)往往会遗漏语义边界 —— 导致嵌入向量质量下降。
- 尽管可根据固定的 token 数分割代码,但这种方式可能导致函数或类等代码块被强制截断。
- 更有效的方案是使用能够理解代码结构的智能分割器,例如递归文本分割器(recursive text splitters),它使用高级分隔符(如类定义和函数声明)在恰当的语义边界处进行精准切分。
- 一个更优雅的解决方案是根据代码的抽象语法树(AST)结构来分割代码。通过深度优先遍历 AST,将代码分割成符合 token 数量限制的子树结构。为避免产生过多的碎片化分块,系统会在满足 token 限制的前提下,将同级语法节点合并为更大的代码块。此类 AST 解析工作可借助 tree-sitter[4] 等工具实现,其支持绝大多数主流编程语言。
04 嵌入向量在推理阶段的应用
在了解 Cursor 如何创建和存储代码嵌入向量后,一个自然而然的问题就出现了:这些嵌入向量在生成之后究竟是如何使用的?
4.1 语义搜索(Semantic Search)与上下文检索(Context Retrieval)
当你使用 Cursor 的 AI 功能(例如通过 @Codebase 或 ⌘ Enter 询问代码库相关问题时),将触发以下流程:
1)将查询转换为向量:Cursor 会为您的提问或当前代码上下文生成对应的嵌入向量。
2)向量相似性搜索:该查询向量被发送至 Turbopuffer(Cursor 的向量数据库),通过最近邻搜索找出与查询语义相似的代码块。
3)访问本地文件:Cursor 客户端接收到的检索结果包含经过混淆处理的文件路径和最相关代码块的行号范围。实际代码内容始终保留在用户本地设备,仅在需要时从本地读取。
4)上下文整合:客户端从用户本地文件读取这些相关代码块,并将其作为上下文与您的问题一并发送至服务器供大语言模型处理。
5)生成响应:此时大语言模型已获取代码库中的相关上下文,可据此提供精准回答或生成符合场景的代码补全。
这种由嵌入向量驱动的检索机制支持以下功能:
1)根据上下文生成代码:在编写新代码时,Cursor 可参考现有代码库中的相似实现,保持代码模式与代码风格的一致性。
2)代码库智能问答:可以获取基于代码库中实际代码的精准解答,而非通用回复。
3)智能代码补全:代码补全建议会融合项目的特定约定与特定模式。
4)智能重构辅助:重构代码时,系统可自动识别代码库中所有需要同步修改的关联代码段。
05 Cursor 为何选择默克尔树
这些设计细节多与安全有关,具体可参阅 Cursor 的安全文档[2]。
5.1 高效的增量更新
默克尔树使 Cursor 能精准定位自上次同步后变更的文件。因此,无需重新上传整个代码库,仅需上传修改过的特定文件。对于大型代码库来说这一点非常重要 —— 重新索引所有文件会消耗过多的带宽和处理时间。
5.2 数据完整性验证
默克尔树结构让 Cursor 能高效验证所索引的文件与服务器上存储的文件是否一致。分层的哈希结构可轻松检测传输过程中的数据异常或数据损坏。
5.3 缓存优化
Cursor 将嵌入向量(embeddings)存储在以代码块(chunk)哈希值为索引的缓存中,使得重复索引相同代码库时速度大幅提升。这对多人协作开发同一代码库的团队尤为有利。
5.4 隐私保护型索引
为保护文件路径中的敏感信息,Cursor 采用路径混淆技术:通过用 “/” 和 “.” 为分隔符切割路径,并用存储在客户端的密钥加密每一段。虽然这样做会暴露部分目录结构,但能隐藏绝大多数敏感细节。
5.5 集成 Git 版本历史
在 Git 仓库中启用代码库索引时,Cursor 还会索引 Git 的版本历史记录。它会存储 commit 的 SHA 值、父提交信息(parent information)及混淆后的文件名。为实现同 Git 仓库且同团队用户间的数据结构共享,用于混淆文件名的秘钥来自最近 commit 内容的哈希值。
06 嵌入模型的选择与技术考量
嵌入模型的选择直接影响代码搜索与理解的质量。 部分系统采用开源模型(如all-MiniLM-L6-v2[5]),而 Cursor 可能使用 OpenAI 的嵌入模型或针对代码场景进行优化的定制模型。对于专用的代码嵌入模型,微软的 unixcoder-base[6] 或 Voyage AI 的 voyage-code-2[7] 等模型对代码的语义理解效果显著。
由于嵌入模型存在 token 容量限制,使得该技术的实现难度大幅增加。以 OpenAI 的 text-embedding-3-small[8] 为例,其 token 上限为 8192。有效的分块策略能在保留语义的前提下不超出该限制。
07 握手同步流程
Cursor 默克尔树实现的核心在于同步时的握手机制。根据应用日志显示:在初始化代码库索引时,Cursor 会创建一个”merkle client”并与服务器进行”初始化握手流程”(详见 GitHub Issue #2209[9] 与 Issue #981[10]),该握手流程涉及向服务器发送本地计算的默克尔树的根哈希值。
握手流程使服务器能精准判定需同步的代码范围。 如握手日志所示(参照 GitHub Issue #2209[11]),Cursor 会计算代码库的初始哈希值,并将其发送至服务器进行验证。
08 技术实现挑战
虽然默克尔树方案有许多优势,但其实现过程仍存在一些技术难点。 Cursor 的索引服务常因瞬时流量过载,导致大量请求失败。如安全文档所述[2],用户可能观察到向 repo42.cursor.sh 发送的网络流量比预期要高 —— 这正是由于文件需多次重传才能被完全索引。
另一项挑战与嵌入向量的安全性有关。学术研究表明,特定条件下存在逆向解析嵌入向量的可能性。虽然当前的攻击手段通常需同时满足:1) 拥有嵌入模型的访问权限 2) 仅对短文本有效。但若攻击者获取 Cursor 向量数据库的访问权限,仍存在从存储的嵌入向量中提取代码库信息的风险。
END
本期互动内容 🍻
❓Cursor 通过路径混淆和本地哈希计算保护隐私,但同步时仍需上传部分数据。在团队协作场景下,你更倾向于完全本地化的方案,还是接受有限数据上传以换取更强的 AI 辅助?为什么?
文中链接
[1]https://forum.cursor.com/t/codebase-indexing/36
[2]https://www.cursor.com/en/security
[3]https://blog.lancedb.com/rag-codebase-1/
[4]https://tree-sitter.github.io/tree-sitter/
[5]https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
[6]https://huggingface.co/microsoft/unixcoder-base
[7]https://docs.voyageai.com/embeddings/models/
[8]https://platform.openai.com/docs/guides/embeddings
[9]https://github.com/getcursor/cursor/issues/2209
[10]https://github.com/getcursor/cursor/issues/981
[11]https://github.com/getcursor/cursor/issues/2209
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://read.engineerscodex.com/p/how-cursor-indexes-codebases-fast
</div>

