
<h2>背景</h2> 大语言模型在生成高质量文案方面表现优异,然而其巨大的计算资源消耗和存储需求,使得实际应用尤其是在资源受限场景中的应用充满挑战。企业在寻求高效的文案生成时,常常面临着在性能和资源之间权衡的困境。在这种背景下,模型蒸馏技术为解决这一问题提供了新的思路。模型蒸馏是一种优化技术,旨在通过将知识从大型复杂模型中提取并转移到更小、计算更高效的模型中,使得这些小型模型能够在保留大多数性能优势的情况下显著降低资源需求。这一技术在大模型文案生成领域的应用,不仅能够保持生成质量接近原有大模型,还极大地减少了计算成本和部署难度。本文介绍如何使用EasyDistill算法框架以及PAI产品,实现基于模型蒸馏的大模型文案生成,通过这种方式节省人力成本,同时提高用户体验,推动业务的可持续增长。
部署教师大语言模型
部署模型服务
您可以按照以下操作步骤,部署教师大语言模型生成对应回复。
在PAI-Model Gallery选择DeepSeek-V3模型或者其他教师大模型,在模型部署区域,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改,参数配置完成后单击部署按钮。以DeepSeek-V3为例,其模型卡片如下所示:

模型部署和调用
PAI 提供的DeepSeek-V3预置了模型的部署配置信息,可以选择SGLang 部署/vLLM部署/Transformers部署,用户仅需提供推理服务的名称以及部署配置使用的资源信息即可将模型部署到PAI-EAS推理服务平台。
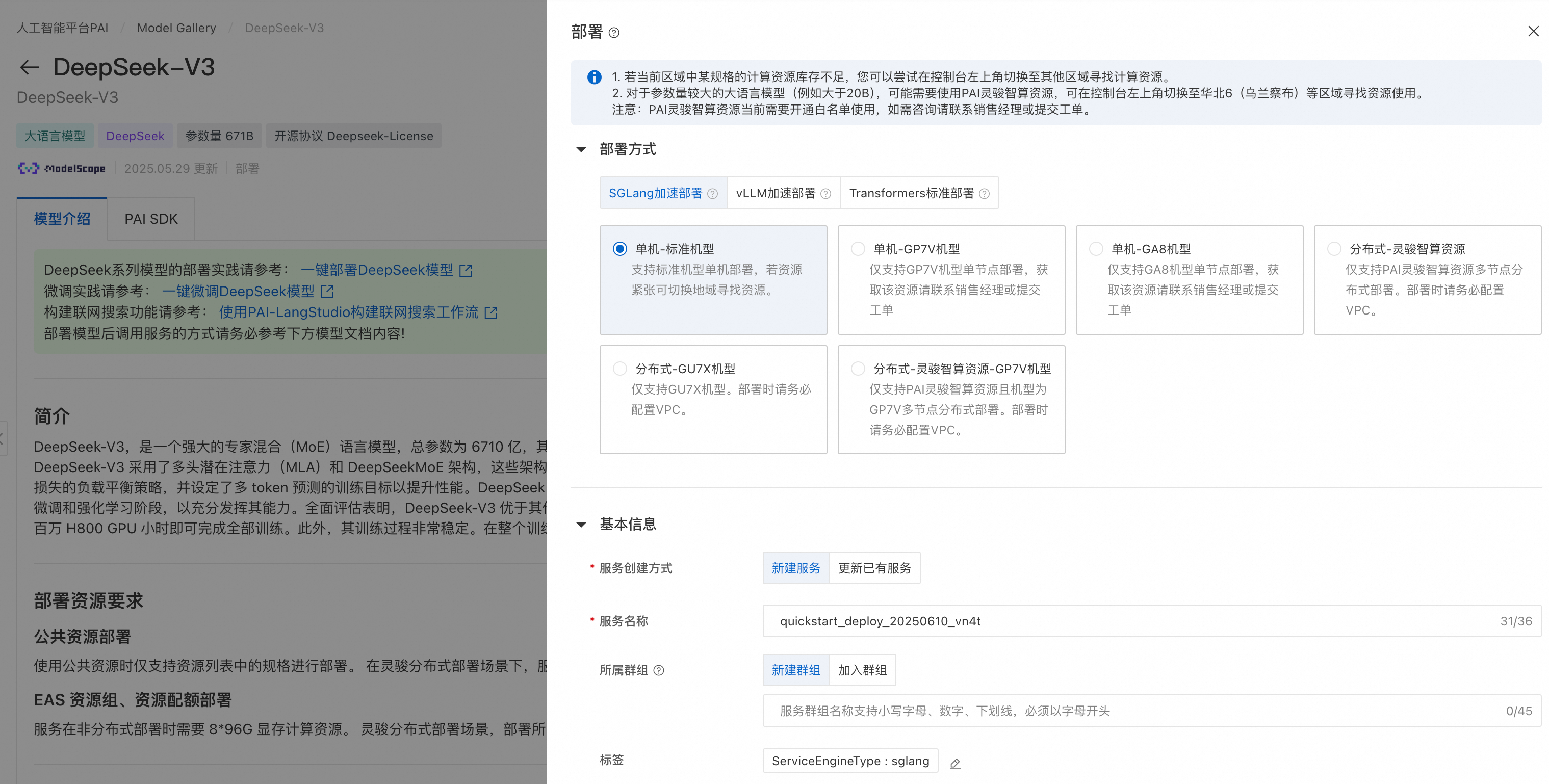
推理服务同样支持以OpenAI API兼容的方式调用,调用示例如下:
from openai import OpenAI
##### API 配置 #####
openai_api_key = "<EAS API KEY>"
openai_api_base = "<EAS API Endpoint>/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
print(model)
def main():
stream = True
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "你好,介绍一下你自己,越详细越好。",
}
],
}
],
model=model,
max_completion_tokens=1024,
stream=stream,
)
if stream:
for chunk in chat_completion:
print(chunk.choices[0].delta.content, end="")
else:
result = chat_completion.choices[0].message.content
print(result)
if __name__ == "__main__":
main()
更多细节可以参考”一键部署DeepSeek-V3、DeepSeek-R1模型”。
构建训练数据
构建SFT训练数据
您可以按照以下操作步骤,构建SFT训练数据。用户可以根据如下输入数据批量调用教师大模型,输入数据格式如下所示:
[
{
"instruction": "xxx"
},
{
"instruction": "xxx"
},
{
"instruction": "xxx"
}
]
其中,instruction为调用大模型的prompt,由任务模版和实际输入数据组成。这里,我们给出一个任务模版供您参考,实际内容可以根据业务场景和数据特征进行调整:
你是短视频文案生成专家,专注于根据视频原始标题、视频内容,生成文案的标题和内容。
你的任务是确保文案与视频核心内容高度匹配,并且吸引用户点击。
要求
1: 信息匹配度:确保文案准确反映视频核心看点,禁止出现视频中未呈现的虚构内容。
2. 情绪契合度:文案情绪需与视频内容保持一致。严肃悲伤类内容不要使用搞笑戏谑风格。
3. 内容规范度:确保句意表达清晰、完整、通顺、连贯,没有出现无意义字符。
4. 严格按照JSON格式输出:
{
"title": "",
"body": ""
}
避免出现情况
1. 标题要求在10个汉字以内。
2. 内容要求在30个汉字以内。
3. 禁止标题党,和过度夸张的表述。
4. 不得出现高敏感内容,或者低俗用语。
请严格按照JSON格式输出内容,不要在输出中加入解析和说明等其他内容。
视频原始标题和视频内容分别如下所示:
给定上述输入数据,我们可以批量调用教师大模型生成回复,示例代码如下:
import json
from openai import OpenAI
##### API 配置 #####
openai_api_key = "<EAS API KEY>"
openai_api_base = "<EAS API Endpoint>/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
# 获取模型
models = client.models.list()
model = models.data[0].id
print(model)
# 读取输入数据
def read_input_data(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return json.load(file)
# 调用大模型获取输出
def get_model_output(instruction):
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": instruction,
}
],
}
],
model=model,
max_completion_tokens=1024,
stream=False,
)
return chat_completion.choices[0].message.content
# 处理输入数据并生成输出
def process_data(input_data):
results = []
for item in input_data:
instruction = item.get("instruction")
output = get_model_output(instruction)
results.append({
"instruction": instruction,
"output": output
})
return results
# 保存输出数据到文件
def save_output_data(file_path, data):
with open(file_path, 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=2)
def main(input_file_path, output_file_path):
input_data = read_input_data(input_file_path)
output_data = process_data(input_data)
save_output_data(output_file_path, output_data)
print("Data processing complete.")
if __name__ == "__main__":
# 指定你的输入和输出文件路径
input_file_path = "input.json"
output_file_path = "output.json"
main(input_file_path, output_file_path)
当运行完上述代码后,我们得到构造好的SFT训练数据,格式如下:
[
{
"instruction": "xxx",
"output": "xxx"
},
{
"instruction": "xxx",
"output": "xxx"
},
{
"instruction": "xxx",
"output": "xxx"
}
]
为了保证SFT训练数据集的高质量,我们建议采用如下设置:
-
训练数据量至少应在3000条以上,而且需要尽可能覆盖输入视频的各种主题;
-
生成文案的任务模版可以按照实际业务需求进行修改,需要根据明确的业务需求,用自然语言精确描述生成的文案要求达到的效果和避免出现的情况;
-
为了保证生成文案的高质量,使用的教师大模型底座参数量需要尽可能高,例如使用满血版的DeepSeek-V3,一般不需要使用深度思考的模型,例如DeepSeek-R1或QwQ-32B;
-
在输入中,视频的内容可以通过OCR、ASR等多种途径从原始视频中抽取出来,需要保证抽取出来的内容具有较高的准确性;
-
建议在生成SFT训练数据集后人工抽样进行质量校验,并且根据校验结果,反复调整调用大模型的任务模版,以达到满意的效果。
构建DPO训练数据
如果您需要通过DPO算法继续优化较小的学生模型,则需要构造用于DPO算法训练的数据集。我们可以基于构造好的SFT训练数据进行继续构造流程。其中,DPO数据格式示例如下所示:
[
{
"prompt": "xxx",
"chosen": "xxx",
"rejected": "xxx"
},
{
"prompt": "xxx",
"chosen": "xxx",
"rejected": "xxx"
},
{
"prompt": "xxx",
"chosen": "xxx",
"rejected": "xxx"
}
]
其中,prompt对应SFT训练数据集的instruction,chosen可以使用SFT训练数据集的output字段,rejected为DPO算法中提供的低质量文案。在DPO算法的训练过程中,我们鼓励大模型生成高质量的chosen文案,惩罚大模型生成类似rejected的文案。因此,我们需要额外生成rejected文案。我们可以同样采用教师大模型生成rejected文案,利用SFT训练数据集作为输入,我们需要改变上文使用的任务模版。这里我们给出一个示例供您参考:
你是视频文案生成初学者,尝试根据视频原始标题、视频内容生成不够吸引人的文案标题和内容。
目标是生成逻辑不清、可能误导、不够吸引用户点击的文案。
要求
1. 信息匹配度:不要求准确反映视频核心看点,甚至可以与视频内容无关。
2. 情绪契合度:文案情绪可以与视频内容不一致。
3. 内容规范度:表达可以不清晰、不完整、不通顺、不连贯,可以出现无意义字符。
4. 可不用严格按照JSON格式输出。
视频原始标题和视频内容分别如下所示:
我们同样给出一个批量推理的脚本,生成上述数据,我们假设输入数据格式与SFT训练数据集相同,但是instruction字段采用上文生成低质量文案的任务模版:
import json
from openai import OpenAI
##### API 配置 #####
openai_api_key = "<EAS API KEY>"
openai_api_base = "<EAS API Endpoint>/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
# 获取模型
models = client.models.list()
model = models.data[0].id
print(model)
# 读取输入数据
def read_input_data(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return json.load(file)
# 调用大模型获取低质量文案
def get_rejected_output(instruction):
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": instruction,
}
],
}
],
model=model,
max_completion_tokens=1024,
stream=False,
)
return chat_completion.choices[0].message.content
# 处理输入数据并生成输出
def process_data(input_data):
results = []
for item in input_data:
instruction = item.get("instruction")
chosen = item.get("output")
rejected = get_rejected_output(instruction)
results.append({
"prompt": instruction,
"chosen": chosen,
"rejected": rejected
})
return results
# 保存输出数据到文件
def save_output_data(file_path, data):
with open(file_path, 'w', encoding='utf-8') as file:
json.dump([data], file, ensure_ascii=False, indent=2)
def main(input_file_path, output_file_path):
input_data = read_input_data(input_file_path)
output_data = process_data(input_data)
save_output_data(output_file_path, output_data)
print("Data processing complete.")
if __name__ == "__main__":
# 指定你的输入和输出文件路径
input_file_path = "input.json"
output_file_path = "output.json"
main(input_file_path, output_file_path)
为了保证DPO训练数据集的高质量,我们建议采用如下设置:
-
训练数据量至少应在1000条以上,而且需要尽可能覆盖输入视频的各种主题;
-
生成rejected文案的任务模版可以按照实际业务需求进行修改,需要和chosen文案在质量上有明显的差距,特别可以注重生成chosen文案中避免出现的情况(即负向样本);
-
为了保证生成文案质量满足要求,使用的教师大模型底座参数量需要尽可能高,例如使用满血版的DeepSeek-V3,一般不需要使用深度思考的模型,例如DeepSeek-R1或QwQ-32B;
-
在输入中,视频的内容可以通过OCR、ASR等多种途径从原始视频中抽取出来,需要保证抽取出来的内容具有较高的准确性;
-
建议在生成DPO训练数据集后人工抽样进行质量校验,并且根据校验结果,反复调整调用大模型的任务模版,以达到满意的效果。
通过SFT算法蒸馏训练较小的学生模型
接下来我们使用EasyDistill算法框架,利用准备好的训练数据,训练学生模型。在PAI-DSW中,根据”阿里云人工智能平台PAI开源EasyDistill框架助力大语言模型轻松瘦身“一文安装EasyDistill算法包后使用如下命令进行SFT模型训练:
python easydistill/kd/train.py --config=sft.json
其中,sft.json为SFT蒸馏训练的配置文件,示例如下:
{
"job_type": "kd_black_box_api",
"dataset": {
"labeled_path": "sft_train.json",
"template" : "chat_template_kd.jinja",
"seed": 42
},
"models": {
"student": "model/Qwen/Qwen2.5-0.5B-Instruct/"
},
"training": {
"output_dir": "result_sft/",
"num_train_epochs": 3,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 8,
"save_steps": 1000,
"logging_steps": 1,
"learning_rate": 2e-5,
"weight_decay": 0.05,
"warmup_ratio": 0.1,
"lr_scheduler_type": "cosine"
}
}
其中,sft_train.json为SFT训练数据集,model/Qwen/Qwen2.5-0.5B-Instruct/为学生模型路径,这里以Qwen2.5-0.5B-Instruct为示例,result_sft/为模型输出路径。您可以根据实际需要,在training字段中调整训练使用的超参数。
通过DPO算法继续优化较小的学生模型
由于SFT训练过程中提供给学生模型唯一的正确答案,因此这种训练存在两个限制条件:一为模型的泛化能力有限,二为缺乏更加细粒度的模型对齐。DPO算法通过提供chosen和rejected的模型回复,进一步提升模型的对齐能力。根据准备好的DPO训练数据,我们在SFT训练完的模型Checkpoint基础上,使用EasyDistill的如下命令,进行DPO模型训练:
python easydistill/rank/train.py --config=dpo.json
其中,dpo.json为DPO蒸馏训练的配置文件,示例如下:
"job_type": "rank_dpo_api",
"dataset": {
"labeled_path": "dpo_train.json",
"template" : "chat_template_kd.jinja",
"seed": 42
},
"models": {
"student": "result_sft/"
},
"training": {
"output_dir": "result_dpo/",
"num_train_epochs": 3,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 8,
"save_steps": 1000,
"logging_steps": 1,
"beta": 0.1,
"learning_rate": 2e-5,
"weight_decay": 0.05,
"warmup_ratio": 0.1,
"lr_scheduler_type": "cosine"
}
}
其中,dpo_train.json为SFT训练数据集,result_sft/为SFT训练之后的学生模型路径,result_dpo/为模型输出路径。您可以根据实际需要,在training字段中调整训练使用的超参数。
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


