【栏目介绍:“玩转OurBMC”是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过“玩转OurBMC”栏目,帮助开发者们深入了解到社区文化、理念及特色,增进开发者对BMC全栈技术的理解。
欢迎各位关注“玩转OurBMC”栏目,共同探索OurBMC社区的精彩世界。同时,我们诚挚地邀请各位开发者向“玩转OurBMC”栏目投稿,共同学习进步,将栏目打造成为汇聚智慧、激发创意的知识园地。】
PCI-Express (peripheral component interconnect express)是一种高速串行计算机扩展总线标准,它采用高速串行点对点双通道的传输架构,使得每一个所连接的设备都能够被分配到独享的通道带宽,与传统共享总线带宽的方式截然不同,独享通道带宽有效避免了多个设备争抢带宽的情况,从而显著提升了数据传输的效率和稳定性。PCI – Express主要支持主动电源管理,错误报告,端对端的可靠性传输,热插拔以及服务质量(QOS)等重要功能,这些功能共同构建起了一个高效、稳定且灵活的计算机扩展总线系统。
飞腾腾珑E2000 PCIe介绍
PCIe拓扑结构采用点对点的链路连接方式,多个组件通过这些点对点链路相互连接,形成一个有机的整体,以实现设备之间高效的数据交换和通信。下图展示的是一个单一的结构实例,在PCIe体系里,将其称为一个层级,由根复合体(RC)、多个端点(I/O 设备)、交换机(Switch)和 PCI Express 到 PCI/PCI-X 桥接器组成,这些硬件都通过 PCI-Express 链路相互连接,共同构成了一个功能强大、高效稳定的 PCIe 拓扑结构。
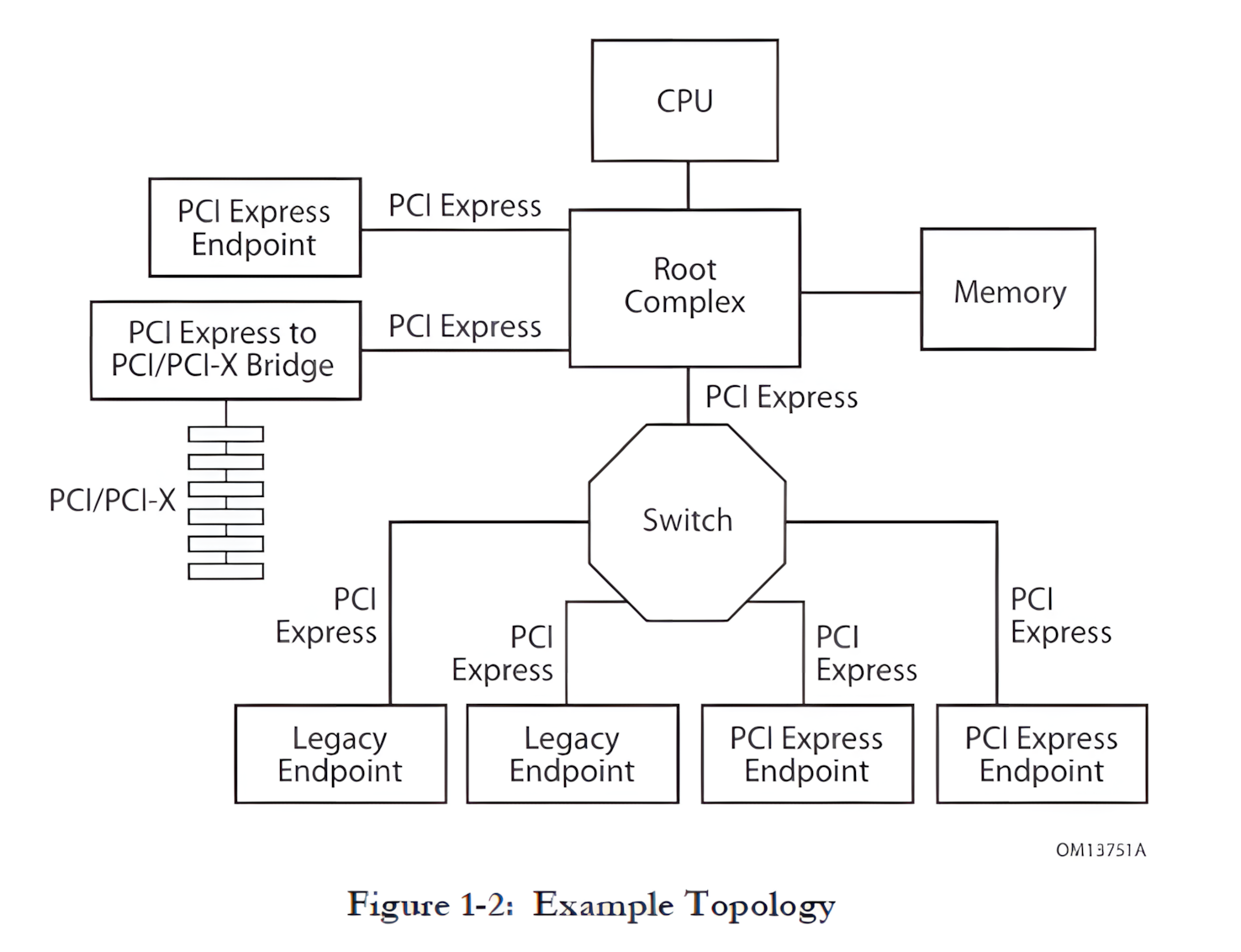
注:上图引用
BMC通常作为Endpoint(EP,端点设备)连接在RC或Switch下用于图形显示,在系统下被识别为一个GPU,操作系统根据厂商号、设备号加载对应的GPU驱动,然后系统便能够将图形界面数据输出到对应的视频接口,常见的视频接口包括VGA、DP、HDMI。
BMC与处理器之间通过 PCIe 接口以内存映射或 I/O 映射的方式进行数据交互。在内存映射方式下,PCIe 设备的寄存器和数据缓冲区被映射到 BMC 的内存地址空间,BMC 可以直接通过内存读写操作来访问设备的寄存器和传输数据,这种方式数据传输速度快,效率高。如下图 BAR0上地址 80058800000 则映射的是飞腾腾珑E2000 上 DC 控制器,BAR2上 80400000000 地址映射的是BMC内存空间,此部分内存空间会被 DC 驱动用作显存。在 BMC 固件中,需要将这部分内存预留出来,以确保 GPU 驱动能够正常使用。
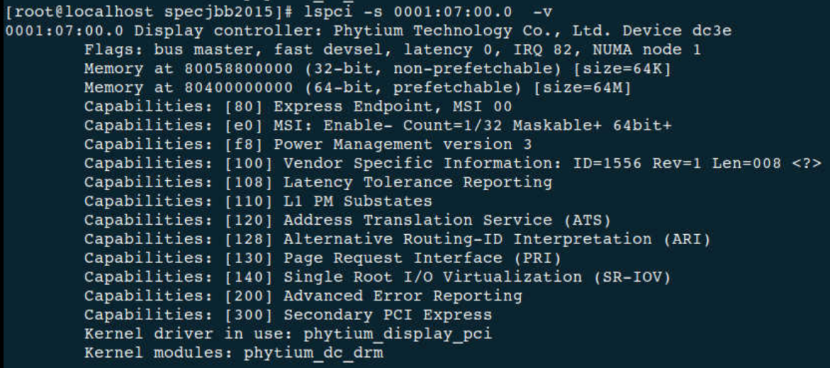
PCIe接口应用:共享内存
飞腾腾珑E2000 的 PCIe EP 使用的是Type0配置空间头,单个 function 最多可支持6个32位 BAR(0-5)或3个64位的BAR(0、2、4)空间。飞腾腾珑E2000 用作GPU时需要使用BAR0和BAR2。此时我们可以将未使用的BAR4利用起来,让BMC内核申请一块内存直接映射到 BAR4 上。完成配置后,如下图所示,Host和BMC映射地址的内容一致,Host 软件或 BIOS 向 BAR4 地址内读写数据,BMC 应用软件向申请的内存读写数据,即可基于 PCIe 接口实现 Host 与 BMC 以共享内存机制进行通信。

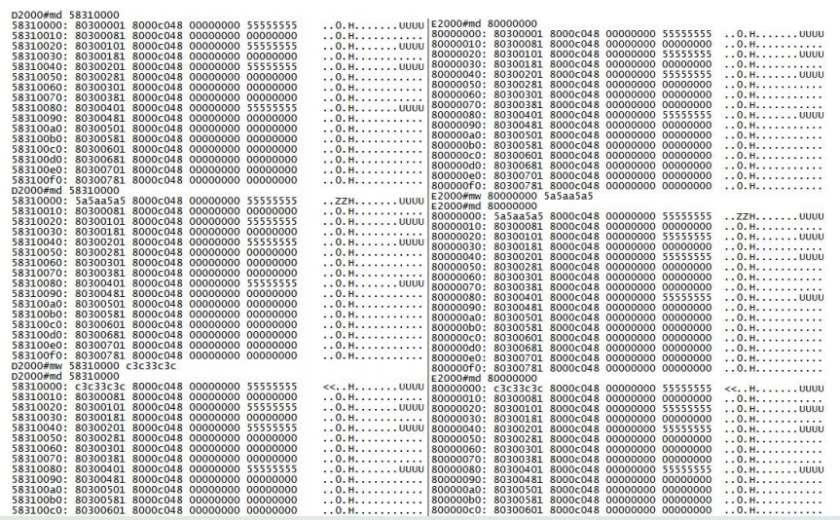
现在硬件上共享内存机制已经实现,Host与BMC通信还需要协商一种适合共享内存机制的通信协议来进行数据交互。针对共享内存的特性,DMTF组织定义MMBI(Memory-Mapped Buffer Interface)协议,常用于服务器场景的BIOS与BMC的通信。
MMBI协议在共享的内存空间定义 H2B(Host to BMC,即Host只写、BMC只读)和 B2H(BMC to Host,即BMC只写Host只读)空间,限制Host和BMC读和写范围,使用者可在数据结构中通过定义状态标志位同步、消息队列优先级、超时重传机制、互斥锁保护等机制确保H2B、B2H交互有序性,避免数据冲突。
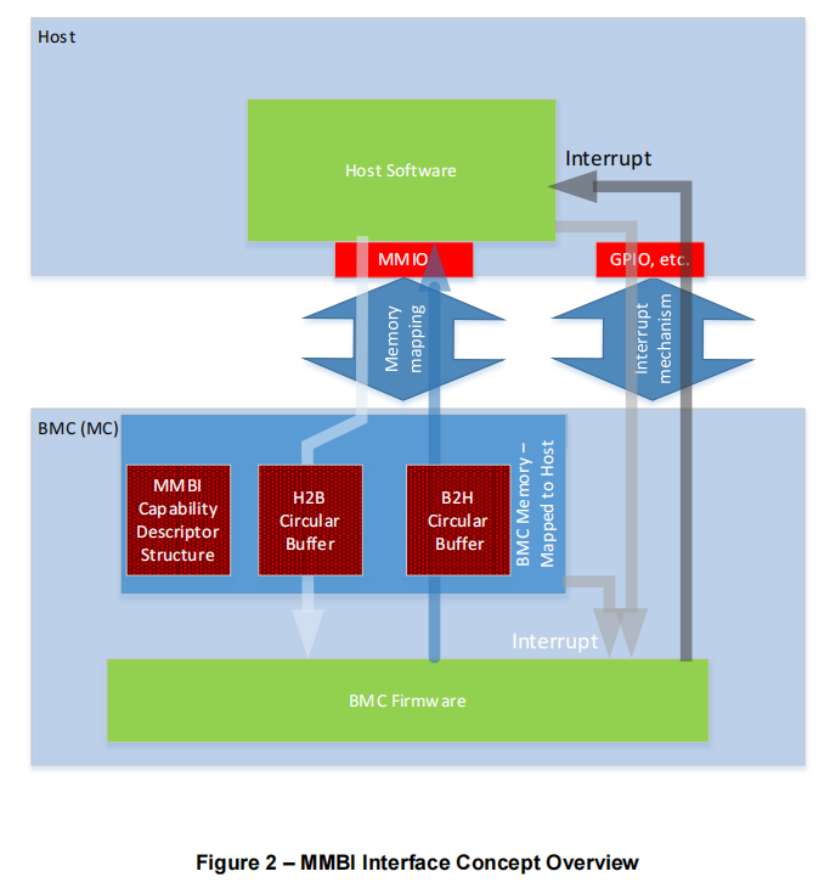
注:上图引用
正常来说用户到这里就可以基于MMBI协议自定义业务的通信协议实现BIOS与BMC的交互。但在复杂的系统管理场景中,往往涉及多组件协作、标准化协议兼容或跨介质扩展等需求。由于MMBI不规定传输的数据结构(如命令类型、参数格式、校验规则),若单独使用,BMC 与主机需自定义私有协议,导致兼容性差(不同厂商的实现无法互通)。当系统中存在多个管理组件(如 BMC、BIOS、NVMe 控制器、网卡管理模块等)时,MMBI 无法标识 “数据该发给哪个组件”,也无法实现跨组件的消息转发。MMBI 依赖 PCIe 实现共享内存映射,若未来系统需要通过其他介质(如 I2C、以太网)传输管理消息,单独的 MMBI 无法支持 “一套上层逻辑适配多底层” 的需求。
这时可以引入MCTP作为管理消息的传输协议,同样DMTF组织定义了《MCTP MMBI Transport Binding Specification》(MCTP over MMBI)规范,用于在MMBI通路上传输MCTP消息。这里只粗略描述MCTP功能特性,不深入阐述。
MCTP在每种通信介质(如PCIe、I2C、I3C等)一般都会定义Discovery机制发现MCTP设备并分配EID,MCTP消息内通过Destination EID、Source EID确定消息收发者。TO、Msg Tag区分报文请求、应答包。搭配SOM、EOM等字段实现拆包组包,可兼容不同通信介质下传输数据数量上限。
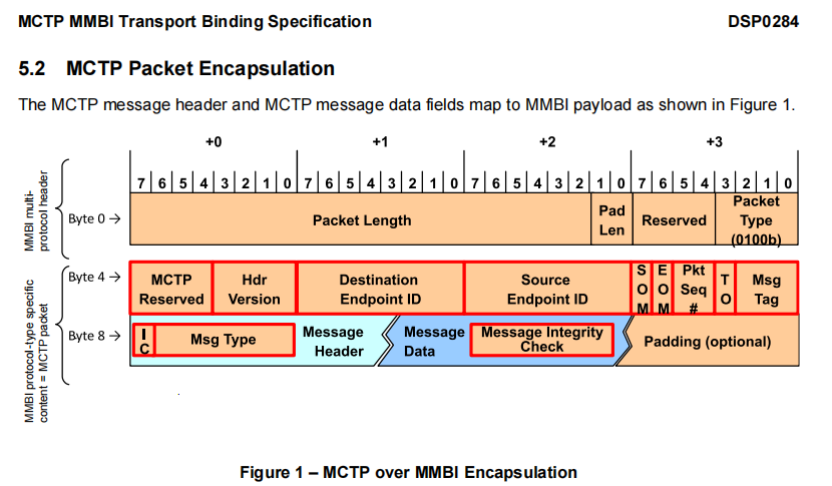
注:上图引用
MCTP 作为中间传输层协议,本身不会定义具体的功能协议。通过 MsgType 字段确认后续 MessageData 字段的具体含义。同样的DMTF组织定义 NVMe-MI、PLDM、NCSI over MCTP 等规范,不同功能的设备可以自由选择支持的功能,如NVMe盘的选择NVMe-MI,网卡 NCSI 等。基于此满足复杂的系统管理场景中,多组件协作、标准化协议兼容或跨介质扩展等需求。
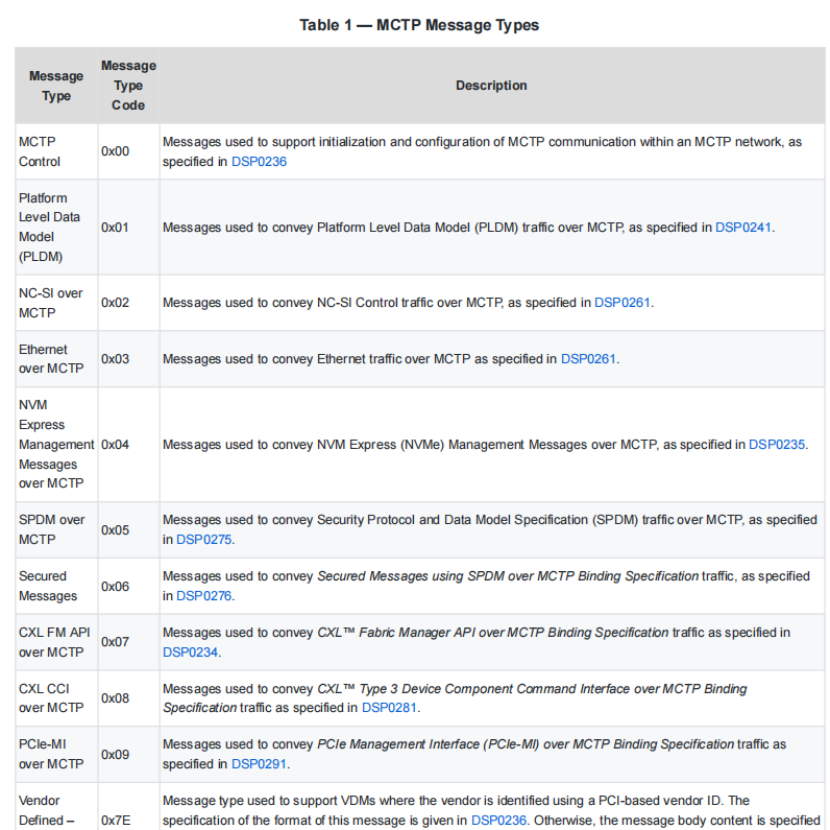
注:上图引用
下图为数据传输流程示例(NVMe-MI over MCTP over MMBI):
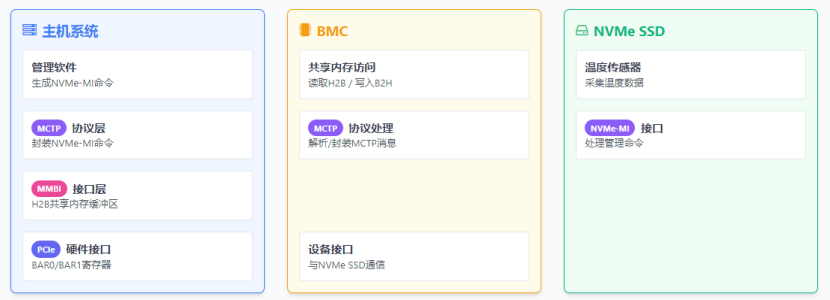
- NVMe-MI 等是 “应用层协议”,定义具体的管理命令,依赖 MCTP 实现传输;
- MCTP是 “中间传输协议”,负责管理消息的格式定义和端到端传输,承上启下;
- MMBI是 “数据链路层”,提供基于共享内存的通信能力,处于 MCTP 之下;
- PCIe是“物理层”,提供最基础的硬件传输能力,是 MMBI 能够实现 “内存直接访问” 的硬件基础。
这种层次划分既保证了底层通信的高效性(MMBI 的共享内存),又实现了上层协议的灵活性(MCTP 支持多介质、应用层聚焦业务),是现代服务器管理通信的典型架构。
本期内容着重为大家介绍了基于 PCIe 接口实现的应用场景–共享内存,共享内存作为一种高效的数据交互方式,通过 PCIe 接口实现时,能够充分发挥 PCIe 接口的高带宽和低延迟特性。在这种应用场景下,CPU 与 BMC 能够直接访问同一块物理内存区域,为大数据量传输提供了高效的通信基础。该机制尤其适用于需快速响应的中断场景,使用无握手的协议,CPU 可在触发中断后立即退出中断处理流程,迅速返回正常业务操作,从而显著减少中断延迟来提高系统的整体性能。下期我们将继续围绕PCIe接口应用为大家深入剖析另一个应用场景——虚拟网卡。敬请关注!
欢迎大家关注OurBMC社区,了解更多BMC技术干货。
OurBMC社区官方网站:
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


